Typedefs | |
| typedef std::vector< ColorSpinorField * > | CompositeColorSpinorField |
| typedef std::complex< double > | Complex |
| using | ColorSpinorFieldSet = ColorSpinorField |
| typedef struct curandStateMRG32k3a | cuRNGState |
| using | DynamicStride = Stride< Dynamic, Dynamic > |
| typedef std::map< TuneKey, TuneParam > | map |
| using | DenseMatrix = MatrixXcd |
| using | VectorSet = MatrixXcd |
| using | Vector = VectorXcd |
| using | RealVector = VectorXd |
| using | RowMajorDenseMatrix = Matrix< Complex, Dynamic, Dynamic, RowMajor > |
Functions | |
| std::ostream & | operator<< (std::ostream &output, const CloverFieldParam ¶m) |
| double | norm1 (const CloverField &u, bool inverse=false) |
| double | norm2 (const CloverField &a, bool inverse=false) |
| void | computeClover (CloverField &clover, const GaugeField &gauge, double coeff, QudaFieldLocation location) |
| void | copyGenericClover (CloverField &out, const CloverField &in, bool inverse, QudaFieldLocation location, void *Out=0, void *In=0, void *outNorm=0, void *inNorm=0) |
| This generic function is used for copying the clover field where in the input and output can be in any order and location. More... | |
| void | cloverInvert (CloverField &clover, bool computeTraceLog, QudaFieldLocation location) |
| This function compute the Cholesky decomposition of each clover matrix and stores the clover inverse field. More... | |
| void | cloverRho (CloverField &clover, double rho) |
| This function adds a real scalar onto the clover diagonal (only to the direct field not the inverse) More... | |
| void | computeCloverForce (GaugeField &force, const GaugeField &U, std::vector< ColorSpinorField *> &x, std::vector< ColorSpinorField *> &p, std::vector< double > &coeff) |
| Compute the force contribution from the solver solution fields. More... | |
| void | computeCloverSigmaOprod (GaugeField &oprod, std::vector< ColorSpinorField *> &x, std::vector< ColorSpinorField *> &p, std::vector< std::vector< double > > &coeff) |
| Compute the outer product from the solver solution fields arising from the diagonal term of the fermion bilinear in direction mu,nu and sum to outer product field. More... | |
| void | computeCloverSigmaTrace (GaugeField &output, const CloverField &clover, double coeff) |
| Compute the matrix tensor field necessary for the force calculation from the clover trace action. This computes a tensor field [mu,nu]. More... | |
| void | cloverDerivative (cudaGaugeField &force, cudaGaugeField &gauge, cudaGaugeField &oprod, double coeff, QudaParity parity) |
| Compute the derivative of the clover matrix in the direction mu,nu and compute the resulting force given the outer-product field. More... | |
| template<typename Float , int Nc, int Ns> | |
| __device__ __host__ Matrix< complex< Float >, Nc > | outerProdSpinTrace (const ColorSpinor< Float, Nc, Ns > &a, const ColorSpinor< Float, Nc, Ns > &b) |
| template<typename Float , int Nc, int Ns> | |
| __device__ __host__ ColorSpinor< Float, Nc, Ns > | operator+ (const ColorSpinor< Float, Nc, Ns > &x, const ColorSpinor< Float, Nc, Ns > &y) |
| ColorSpinor addition operator. More... | |
| template<typename Float , int Nc, int Ns> | |
| __device__ __host__ ColorSpinor< Float, Nc, Ns > | operator- (const ColorSpinor< Float, Nc, Ns > &x, const ColorSpinor< Float, Nc, Ns > &y) |
| ColorSpinor subtraction operator. More... | |
| template<typename Float , int Nc, int Ns, typename S > | |
| __device__ __host__ ColorSpinor< Float, Nc, Ns > | operator* (const S &a, const ColorSpinor< Float, Nc, Ns > &x) |
| Compute the scalar-vector product y = a * x. More... | |
| template<typename Float , int Nc, int Ns> | |
| __device__ __host__ ColorSpinor< Float, Nc, Ns > | operator* (const Matrix< complex< Float >, Nc > &A, const ColorSpinor< Float, Nc, Ns > &x) |
| Compute the matrix-vector product y = A * x. More... | |
| template<typename Float , int Nc, int Ns> | |
| __device__ __host__ ColorSpinor< Float, Nc, Ns > | operator* (const HMatrix< Float, Nc *Ns > &A, const ColorSpinor< Float, Nc, Ns > &x) |
| Compute the matrix-vector product y = A * x. More... | |
| void | copyGenericColorSpinor (ColorSpinorField &dst, const ColorSpinorField &src, QudaFieldLocation location, void *Dst=0, void *Src=0, void *dstNorm=0, void *srcNorm=0) |
| void | genericSource (cpuColorSpinorField &a, QudaSourceType sourceType, int x, int s, int c) |
| int | genericCompare (const cpuColorSpinorField &a, const cpuColorSpinorField &b, int tol) |
| void | genericPrintVector (cpuColorSpinorField &a, unsigned int x) |
| void | wuppertalStep (ColorSpinorField &out, const ColorSpinorField &in, int parity, const GaugeField &U, double A, double B) |
| void | wuppertalStep (ColorSpinorField &out, const ColorSpinorField &in, int parity, const GaugeField &U, double alpha) |
| void | exchangeExtendedGhost (cudaColorSpinorField *spinor, int R[], int parity, cudaStream_t *stream_p) |
| void | copyExtendedColorSpinor (ColorSpinorField &dst, const ColorSpinorField &src, QudaFieldLocation location, const int parity, void *Dst, void *Src, void *dstNorm, void *srcNorm) |
| void | genericPackGhost (void **ghost, const ColorSpinorField &a, QudaParity parity, int nFace, int dagger, MemoryLocation *destination=nullptr) |
| Generic ghost packing routine. More... | |
| void | spinorGauss (ColorSpinorField &src, int seed) |
| void | spinorGauss (ColorSpinorField &src, RNG &randstates) |
| template<typename ValueType > | |
| __host__ __device__ ValueType | cos (ValueType x) |
| template<typename ValueType > | |
| __host__ __device__ ValueType | sin (ValueType x) |
| template<typename ValueType > | |
| __host__ __device__ ValueType | tan (ValueType x) |
| template<typename ValueType > | |
| __host__ __device__ ValueType | acos (ValueType x) |
| template<typename ValueType > | |
| __host__ __device__ ValueType | asin (ValueType x) |
| template<typename ValueType > | |
| __host__ __device__ ValueType | atan (ValueType x) |
| template<typename ValueType > | |
| __host__ __device__ ValueType | atan2 (ValueType x, ValueType y) |
| template<typename ValueType > | |
| __host__ __device__ ValueType | cosh (ValueType x) |
| template<typename ValueType > | |
| __host__ __device__ ValueType | sinh (ValueType x) |
| template<typename ValueType > | |
| __host__ __device__ ValueType | tanh (ValueType x) |
| template<typename ValueType > | |
| __host__ __device__ ValueType | exp (ValueType x) |
| template<typename ValueType > | |
| __host__ __device__ ValueType | log (ValueType x) |
| template<typename ValueType > | |
| __host__ __device__ ValueType | log10 (ValueType x) |
| template<typename ValueType , typename ExponentType > | |
| __host__ __device__ ValueType | pow (ValueType x, ExponentType e) |
| template<typename ValueType > | |
| __host__ __device__ ValueType | sqrt (ValueType x) |
| template<typename ValueType > | |
| __host__ __device__ ValueType | abs (ValueType x) |
| template<typename ValueType > | |
| __host__ __device__ ValueType | conj (ValueType x) |
| template<typename ValueType > | |
| __host__ __device__ ValueType | abs (const complex< ValueType > &z) |
| Returns the magnitude of z. More... | |
| template<typename ValueType > | |
| __host__ __device__ ValueType | arg (const complex< ValueType > &z) |
| Returns the phase angle of z. More... | |
| template<typename ValueType > | |
| __host__ __device__ ValueType | norm (const complex< ValueType > &z) |
| Returns the magnitude of z squared. More... | |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | conj (const complex< ValueType > &z) |
| Returns the complex conjugate of z. More... | |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | polar (const ValueType &m, const ValueType &theta=0) |
| Returns the complex with magnitude m and angle theta in radians. More... | |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | operator* (const complex< ValueType > &lhs, const complex< ValueType > &rhs) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | operator* (const complex< ValueType > &lhs, const ValueType &rhs) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | operator* (const ValueType &lhs, const complex< ValueType > &rhs) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | operator/ (const complex< ValueType > &lhs, const complex< ValueType > &rhs) |
| template<> | |
| __host__ __device__ complex< float > | operator/ (const complex< float > &lhs, const complex< float > &rhs) |
| template<> | |
| __host__ __device__ complex< double > | operator/ (const complex< double > &lhs, const complex< double > &rhs) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | operator+ (const complex< ValueType > &lhs, const complex< ValueType > &rhs) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | operator+ (const complex< ValueType > &lhs, const ValueType &rhs) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | operator+ (const ValueType &lhs, const complex< ValueType > &rhs) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | operator- (const complex< ValueType > &lhs, const complex< ValueType > &rhs) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | operator- (const complex< ValueType > &lhs, const ValueType &rhs) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | operator- (const ValueType &lhs, const complex< ValueType > &rhs) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | operator+ (const complex< ValueType > &rhs) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | operator- (const complex< ValueType > &rhs) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | cos (const complex< ValueType > &z) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | cosh (const complex< ValueType > &z) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | exp (const complex< ValueType > &z) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | log (const complex< ValueType > &z) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | log10 (const complex< ValueType > &z) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | pow (const complex< ValueType > &z, const int &n) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | pow (const complex< ValueType > &z, const ValueType &x) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | pow (const complex< ValueType > &z, const complex< ValueType > &z2) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | pow (const ValueType &x, const complex< ValueType > &z) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | sin (const complex< ValueType > &z) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | sinh (const complex< ValueType > &z) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | sqrt (const complex< ValueType > &z) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | tan (const complex< ValueType > &z) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | tanh (const complex< ValueType > &z) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | acos (const complex< ValueType > &z) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | asin (const complex< ValueType > &z) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | atan (const complex< ValueType > &z) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | acosh (const complex< ValueType > &z) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | asinh (const complex< ValueType > &z) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | atanh (const complex< ValueType > &z) |
| template<typename ValueType , class charT , class traits > | |
| std::basic_ostream< charT, traits > & | operator<< (std::basic_ostream< charT, traits > &os, const complex< ValueType > &z) |
| template<typename ValueType , typename charT , class traits > | |
| std::basic_istream< charT, traits > & | operator>> (std::basic_istream< charT, traits > &is, complex< ValueType > &z) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | operator+ (const volatile complex< ValueType > &lhs, const volatile complex< ValueType > &rhs) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | operator/ (const complex< ValueType > &lhs, const ValueType &rhs) |
| template<typename ValueType > | |
| __host__ __device__ complex< ValueType > | operator/ (const ValueType &lhs, const complex< ValueType > &rhs) |
| template<> | |
| __host__ __device__ complex< float > | operator/ (const float &lhs, const complex< float > &rhs) |
| template<> | |
| __host__ __device__ complex< double > | operator/ (const double &lhs, const complex< double > &rhs) |
| template<typename ValueType > | |
| __host__ __device__ bool | operator== (const complex< ValueType > &lhs, const complex< ValueType > &rhs) |
| template<typename ValueType > | |
| __host__ __device__ bool | operator== (const ValueType &lhs, const complex< ValueType > &rhs) |
| template<typename ValueType > | |
| __host__ __device__ bool | operator== (const complex< ValueType > &lhs, const ValueType &rhs) |
| template<typename ValueType > | |
| __host__ __device__ bool | operator!= (const complex< ValueType > &lhs, const complex< ValueType > &rhs) |
| template<typename ValueType > | |
| __host__ __device__ bool | operator!= (const ValueType &lhs, const complex< ValueType > &rhs) |
| template<typename ValueType > | |
| __host__ __device__ bool | operator!= (const complex< ValueType > &lhs, const ValueType &rhs) |
| template<> | |
| __host__ __device__ float | abs (const complex< float > &z) |
| template<> | |
| __host__ __device__ double | abs (const complex< double > &z) |
| template<> | |
| __host__ __device__ float | arg (const complex< float > &z) |
| template<> | |
| __host__ __device__ double | arg (const complex< double > &z) |
| template<> | |
| __host__ __device__ complex< float > | polar (const float &magnitude, const float &angle) |
| template<> | |
| __host__ __device__ complex< double > | polar (const double &magnitude, const double &angle) |
| template<> | |
| __host__ __device__ complex< float > | cos (const complex< float > &z) |
| template<> | |
| __host__ __device__ complex< float > | cosh (const complex< float > &z) |
| template<> | |
| __host__ __device__ complex< float > | exp (const complex< float > &z) |
| template<> | |
| __host__ __device__ complex< float > | log (const complex< float > &z) |
| template<> | |
| __host__ __device__ complex< float > | pow (const float &x, const complex< float > &exponent) |
| template<> | |
| __host__ __device__ complex< float > | sin (const complex< float > &z) |
| template<> | |
| __host__ __device__ complex< float > | sinh (const complex< float > &z) |
| template<typename ValueType > | |
| __host__ __device__ complex< float > | sqrt (const complex< float > &z) |
| template<typename ValueType > | |
| __host__ __device__ complex< float > | atanh (const complex< float > &z) |
| void | contractCuda (const cudaColorSpinorField &x, const cudaColorSpinorField &y, void *result, const QudaContractType contract_type, const QudaParity parity, TimeProfile &profile) |
| void | contractCuda (const cudaColorSpinorField &x, const cudaColorSpinorField &y, void *result, const QudaContractType contract_type, const int tSlice, const QudaParity parity, TimeProfile &profile) |
| void | covDev (cudaColorSpinorField *out, cudaGaugeField &gauge, const cudaColorSpinorField *in, const int parity, const int mu, TimeProfile &profile) |
| void | ApplyCovDev (ColorSpinorField &out, const ColorSpinorField &in, const GaugeField &U, int parity, int mu) |
| Driver for applying the covariant derivative. More... | |
| template<typename scalar , int n> | |
| __device__ __host__ void | zero (vector_type< scalar, n > &v) |
| template<typename scalar , int n> | |
| __device__ __host__ vector_type< scalar, n > | operator+ (const vector_type< scalar, n > &a, const vector_type< scalar, n > &b) |
| template<int block_size_x, int block_size_y, typename T > | |
| __device__ void | reduce2d (ReduceArg< T > arg, const T &in, const int idx=0) |
| template<int block_size, typename T > | |
| __device__ void | reduce (ReduceArg< T > arg, const T &in, const int idx=0) |
| template<int block_size_x, int block_size_y, typename T > | |
| __device__ void | reduceRow (ReduceArg< T > arg, const T &in) |
| void | setDiracParam (DiracParam &diracParam, QudaInvertParam *inv_param, bool pc) |
| void | setDiracSloppyParam (DiracParam &diracParam, QudaInvertParam *inv_param, bool pc) |
| void | setKernelPackT (bool pack) |
| bool | getKernelPackT () |
| void | setPackComms (const int *commDim) |
| bool | getDslashLaunch () |
| void | createDslashEvents () |
| void | destroyDslashEvents () |
| void | wilsonDslashCuda (cudaColorSpinorField *out, const cudaGaugeField &gauge, const cudaColorSpinorField *in, const int oddBit, const int daggerBit, const cudaColorSpinorField *x, const double &k, const int *commDim, TimeProfile &profile) |
| void | cloverDslashCuda (cudaColorSpinorField *out, const cudaGaugeField &gauge, const FullClover &cloverInv, const cudaColorSpinorField *in, const int oddBit, const int daggerBit, const cudaColorSpinorField *x, const double &k, const int *commDim, TimeProfile &profile) |
| void | asymCloverDslashCuda (cudaColorSpinorField *out, const cudaGaugeField &gauge, const FullClover &cloverInv, const cudaColorSpinorField *in, const int oddBit, const int daggerBit, const cudaColorSpinorField *x, const double &k, const int *commDim, TimeProfile &profile) |
| void | ApplyClover (ColorSpinorField &out, const ColorSpinorField &in, const CloverField &clover, bool inverse, int parity) |
| Apply clover-matrix field to a color-spinor field. More... | |
| void | domainWallDslashCuda (cudaColorSpinorField *out, const cudaGaugeField &gauge, const cudaColorSpinorField *in, const int parity, const int dagger, const cudaColorSpinorField *x, const double &m_f, const double &k, const int *commDim, TimeProfile &profile) |
| void | domainWallDslashCuda (cudaColorSpinorField *out, const cudaGaugeField &gauge, const cudaColorSpinorField *in, const int parity, const int dagger, const cudaColorSpinorField *x, const double &m_f, const double &a, const double &b, const int *commDim, const int DS_type, TimeProfile &profile) |
| void | MDWFDslashCuda (cudaColorSpinorField *out, const cudaGaugeField &gauge, const cudaColorSpinorField *in, const int parity, const int dagger, const cudaColorSpinorField *x, const double &m_f, const double &k, const double *b5, const double *c_5, const double &m5, const int *commDim, const int DS_type, TimeProfile &profile) |
| void | staggeredDslashCuda (cudaColorSpinorField *out, const cudaGaugeField &gauge, const cudaColorSpinorField *in, const int parity, const int dagger, const cudaColorSpinorField *x, const double &k, const int *commDim, TimeProfile &profile) |
| void | improvedStaggeredDslashCuda (cudaColorSpinorField *out, const cudaGaugeField &fatGauge, const cudaGaugeField &longGauge, const cudaColorSpinorField *in, const int parity, const int dagger, const cudaColorSpinorField *x, const double &k, const int *commDim, TimeProfile &profile) |
| void | twistedMassDslashCuda (cudaColorSpinorField *out, const cudaGaugeField &gauge, const cudaColorSpinorField *in, const int parity, const int dagger, const cudaColorSpinorField *x, const QudaTwistDslashType type, const double &kappa, const double &mu, const double &epsilon, const double &k, const int *commDim, TimeProfile &profile) |
| void | ndegTwistedMassDslashCuda (cudaColorSpinorField *out, const cudaGaugeField &gauge, const cudaColorSpinorField *in, const int parity, const int dagger, const cudaColorSpinorField *x, const QudaTwistDslashType type, const double &kappa, const double &mu, const double &epsilon, const double &k, const int *commDim, TimeProfile &profile) |
| void | twistedCloverDslashCuda (cudaColorSpinorField *out, const cudaGaugeField &gauge, const FullClover *clover, const FullClover *cloverInv, const cudaColorSpinorField *in, const int parity, const int dagger, const cudaColorSpinorField *x, const QudaTwistCloverDslashType type, const double &kappa, const double &mu, const double &epsilon, const double &k, const int *commDim, TimeProfile &profile) |
| void | ApplyTwistGamma (ColorSpinorField &out, const ColorSpinorField &in, int d, double kappa, double mu, double epsilon, int dagger, QudaTwistGamma5Type type) |
| Apply the twisted-mass gamma operator to a color-spinor field. More... | |
| void | ApplyTwistClover (ColorSpinorField &out, const ColorSpinorField &in, const CloverField &clover, double kappa, double mu, double epsilon, int parity, int dagger, QudaTwistGamma5Type twist) |
| Apply twisted clover-matrix field to a color-spinor field. More... | |
| void | packFace (void *ghost_buf[2 *QUDA_MAX_DIM], cudaColorSpinorField &in, MemoryLocation location, const int nFace, const int dagger, const int parity, const int dim, const int face_num, const cudaStream_t &stream, const double a=0.0, const double b=0.0) |
| Dslash face packing routine. More... | |
| void | packFaceExtended (void *ghost_buf[2 *QUDA_MAX_DIM], cudaColorSpinorField &field, MemoryLocation location, const int nFace, const int R[], const int dagger, const int parity, const int dim, const int face_num, const cudaStream_t &stream, const bool unpack=false) |
| void | gamma5 (ColorSpinorField &out, const ColorSpinorField &in) |
| Applies a gamma5 matrix to a spinor (wrapper to ApplyGamma) More... | |
| __device__ __host__ void | zero (double &a) |
| __device__ __host__ void | zero (double2 &a) |
| __device__ __host__ void | zero (double3 &a) |
| __device__ __host__ void | zero (double4 &a) |
| __device__ __host__ void | zero (float &a) |
| __device__ __host__ void | zero (float2 &a) |
| __device__ __host__ void | zero (float3 &a) |
| __device__ __host__ void | zero (float4 &a) |
| __host__ __device__ double2 | operator+ (const double2 &x, const double2 &y) |
| __host__ __device__ double2 | operator- (const double2 &x, const double2 &y) |
| __host__ __device__ float2 | operator- (const float2 &x, const float2 &y) |
| __host__ __device__ float4 | operator- (const float4 &x, const float4 &y) |
| __host__ __device__ double3 | operator+ (const double3 &x, const double3 &y) |
| __host__ __device__ double4 | operator+ (const double4 &x, const double4 &y) |
| __host__ __device__ float4 | operator* (const float a, const float4 x) |
| __host__ __device__ float2 | operator* (const float a, const float2 x) |
| __host__ __device__ double2 | operator* (const double a, const double2 x) |
| __host__ __device__ double4 | operator* (const double a, const double4 x) |
| __host__ __device__ float2 | operator+ (const float2 x, const float2 y) |
| __host__ __device__ float4 | operator+ (const float4 x, const float4 y) |
| __host__ __device__ float4 | operator+= (float4 &x, const float4 y) |
| __host__ __device__ float2 | operator+= (float2 &x, const float2 y) |
| __host__ __device__ double2 | operator+= (double2 &x, const double2 y) |
| __host__ __device__ double3 | operator+= (double3 &x, const double3 y) |
| __host__ __device__ double4 | operator+= (double4 &x, const double4 y) |
| __host__ __device__ float4 | operator-= (float4 &x, const float4 y) |
| __host__ __device__ float2 | operator-= (float2 &x, const float2 y) |
| __host__ __device__ double2 | operator-= (double2 &x, const double2 y) |
| __host__ __device__ float2 | operator*= (float2 &x, const float a) |
| __host__ __device__ double2 | operator*= (double2 &x, const float a) |
| __host__ __device__ float4 | operator*= (float4 &a, const float &b) |
| __host__ __device__ double2 | operator*= (double2 &a, const double &b) |
| __host__ __device__ double4 | operator*= (double4 &a, const double &b) |
| __host__ __device__ float2 | operator- (const float2 &x) |
| __host__ __device__ double2 | operator- (const double2 &x) |
| __forceinline__ __host__ __device__ float | max_fabs (const float4 &c) |
| __forceinline__ __host__ __device__ float | max_fabs (const float2 &b) |
| __forceinline__ __host__ __device__ double | max_fabs (const double4 &c) |
| __forceinline__ __host__ __device__ double | max_fabs (const double2 &b) |
| __forceinline__ __host__ __device__ float2 | make_FloatN (const double2 &a) |
| __forceinline__ __host__ __device__ float4 | make_FloatN (const double4 &a) |
| __forceinline__ __host__ __device__ double2 | make_FloatN (const float2 &a) |
| __forceinline__ __host__ __device__ double4 | make_FloatN (const float4 &a) |
| __forceinline__ __host__ __device__ short4 | make_shortN (const float4 &a) |
| __forceinline__ __host__ __device__ short2 | make_shortN (const float2 &a) |
| __forceinline__ __host__ __device__ short4 | make_shortN (const double4 &a) |
| __forceinline__ __host__ __device__ short2 | make_shortN (const double2 &a) |
| template<typename Float2 , typename Complex > | |
| Float2 | make_Float2 (const Complex &a) |
| template<> | |
| double2 | make_Float2 (const complex< double > &a) |
| template<> | |
| double2 | make_Float2 (const complex< float > &a) |
| template<> | |
| float2 | make_Float2 (const complex< double > &a) |
| template<> | |
| float2 | make_Float2 (const complex< float > &a) |
| template<> | |
| double2 | make_Float2 (const std::complex< double > &a) |
| template<> | |
| double2 | make_Float2 (const std::complex< float > &a) |
| template<> | |
| float2 | make_Float2 (const std::complex< double > &a) |
| template<> | |
| float2 | make_Float2 (const std::complex< float > &a) |
| complex< double > | make_Complex (const double2 &a) |
| complex< float > | make_Complex (const float2 &a) |
| std::ostream & | operator<< (std::ostream &output, const GaugeFieldParam ¶m) |
| double | norm1 (const GaugeField &u) |
| This is a debugging function, where we cast a gauge field into a spinor field so we can compute its L1 norm. More... | |
| double | norm2 (const GaugeField &u) |
| This is a debugging function, where we cast a gauge field into a spinor field so we can compute its L2 norm. More... | |
| void | ax (const double &a, GaugeField &u) |
| Scale the gauge field by the scalar a. More... | |
| void | copyGenericGauge (GaugeField &out, const GaugeField &in, QudaFieldLocation location, void *Out=0, void *In=0, void **ghostOut=0, void **ghostIn=0, int type=0) |
| void | copyExtendedGauge (GaugeField &out, const GaugeField &in, QudaFieldLocation location, void *Out=0, void *In=0) |
| void | extractGaugeGhost (const GaugeField &u, void **ghost, bool extract=true, int offset=0) |
| void | extractExtendedGaugeGhost (const GaugeField &u, int dim, const int *R, void **ghost, bool extract) |
| double | maxGauge (const GaugeField &u) |
| void | applyGaugePhase (GaugeField &u) |
| uint64_t | Checksum (const GaugeField &u, bool mini=false) |
| void | gaugeForce (GaugeField &mom, const GaugeField &u, double coeff, int ***input_path, int *length, double *path_coeff, int num_paths, int max_length) |
| Compute the gauge-force contribution to the momentum. More... | |
| double3 | plaquette (const GaugeField &U, QudaFieldLocation location) |
| void | gaugeGauss (GaugeField &dataDs, RNG &rngstate) |
| void | APEStep (GaugeField &dataDs, const GaugeField &dataOr, double alpha) |
| void | STOUTStep (GaugeField &dataDs, const GaugeField &dataOr, double rho) |
| void | OvrImpSTOUTStep (GaugeField &dataDs, const GaugeField &dataOr, double rho, double epsilon) |
| void | gaugefixingOVR (cudaGaugeField &data, const int gauge_dir, const int Nsteps, const int verbose_interval, const double relax_boost, const double tolerance, const int reunit_interval, const int stopWtheta) |
| Gauge fixing with overrelaxation with support for single and multi GPU. More... | |
| void | gaugefixingFFT (cudaGaugeField &data, const int gauge_dir, const int Nsteps, const int verbose_interval, const double alpha, const int autotune, const double tolerance, const int stopWtheta) |
| Gauge fixing with Steepest descent method with FFTs with support for single GPU only. More... | |
| void | computeFmunu (GaugeField &Fmunu, const GaugeField &gauge, QudaFieldLocation location) |
| double | computeQCharge (GaugeField &Fmunu, QudaFieldLocation location) |
| void | updateGaugeField (GaugeField &out, double dt, const GaugeField &in, const GaugeField &mom, bool conj_mom, bool exact) |
| template<typename I , typename J , typename K > | |
| static __device__ __host__ int | linkIndexShift (const I x[], const J dx[], const K X[4]) |
| template<typename I , typename J , typename K > | |
| static __device__ __host__ int | linkIndexShift (I y[], const I x[], const J dx[], const K X[4]) |
| template<typename I > | |
| static __device__ __host__ int | linkIndex (const int x[], const I X[4]) |
| template<typename I > | |
| static __device__ __host__ int | linkIndex (int y[], const int x[], const I X[4]) |
| template<typename I > | |
| static __device__ __host__ int | linkIndexM1 (const int x[], const I X[4], const int mu) |
| template<typename I > | |
| static __device__ __host__ int | linkNormalIndexP1 (const int x[], const I X[4], const int mu) |
| template<typename I > | |
| static __device__ __host__ int | linkIndexP1 (const int x[], const I X[4], const int mu) |
| template<typename I > | |
| static __device__ __host__ void | getCoords (int x[], int cb_index, const I X[], int parity) |
| template<typename I , typename J > | |
| static __device__ __host__ void | getCoordsExtended (I x[], int cb_index, const J X[], int parity, const int R[]) |
| template<typename I > | |
| static __device__ __host__ void | getCoords5 (int x[5], int cb_index, const I X[5], int parity, QudaDWFPCType pc_type) |
| template<typename I > | |
| static __device__ __host__ int | getIndexFull (int cb_index, const I X[4], int parity) |
| template<int dir, typename I > | |
| __device__ __host__ int | ghostFaceIndex (const int x[], const I X[], int dim, int nFace) |
| __device__ void | load_streaming_double2 (double2 &a, const double2 *addr) |
| __device__ void | load_streaming_float4 (float4 &a, const float4 *addr) |
| __device__ void | load_global_float4 (float4 &a, const float4 *addr) |
| __device__ void | store_streaming_float4 (float4 *addr, float x, float y, float z, float w) |
| __device__ void | store_streaming_short4 (short4 *addr, short x, short y, short z, short w) |
| __device__ void | store_streaming_double2 (double2 *addr, double x, double y) |
| __device__ void | store_streaming_float2 (float2 *addr, float x, float y) |
| __device__ void | store_streaming_short2 (short2 *addr, short x, short y) |
| void | completeKSForce (GaugeField &mom, const GaugeField &oprod, const GaugeField &gauge, QudaFieldLocation location, long long *flops=NULL) |
| std::ostream & | operator<< (std::ostream &output, const LatticeFieldParam ¶m) |
| QudaFieldLocation | Location_ (const char *func, const char *file, int line, const LatticeField &a, const LatticeField &b) |
| Helper function for determining if the location of the fields is the same. More... | |
| template<typename... Args> | |
| QudaFieldLocation | Location_ (const char *func, const char *file, int line, const LatticeField &a, const LatticeField &b, const Args &... args) |
| Helper function for determining if the location of the fields is the same. More... | |
| QudaPrecision | Precision_ (const char *func, const char *file, int line, const LatticeField &a, const LatticeField &b) |
| Helper function for determining if the precision of the fields is the same. More... | |
| template<typename... Args> | |
| QudaPrecision | Precision_ (const char *func, const char *file, int line, const LatticeField &a, const LatticeField &b, const Args &... args) |
| Helper function for determining if the precision of the fields is the same. More... | |
| QudaFieldLocation | reorder_location () |
| Return whether data is reordered on the CPU or GPU. This can set at QUDA initialization using the environment variable QUDA_REORDER_LOCATION. More... | |
| void | reorder_location_set (QudaFieldLocation reorder_location_) |
| Set whether data is reorderd on the CPU or GPU. This can set at QUDA initialization using the environment variable QUDA_REORDER_LOCATION. More... | |
| void | fatLongKSLink (cudaGaugeField *fat, cudaGaugeField *lng, const cudaGaugeField &gauge, const double *coeff) |
| Compute the fat and long links for an improved staggered (Kogut-Susskind) fermions. More... | |
| void | printPeakMemUsage () |
| void | assertAllMemFree () |
| long | device_allocated_peak () |
| long | pinned_allocated_peak () |
| long | mapped_allocated_peak () |
| long | host_allocated_peak () |
| void * | device_malloc_ (const char *func, const char *file, int line, size_t size) |
| void * | device_pinned_malloc_ (const char *func, const char *file, int line, size_t size) |
| void * | safe_malloc_ (const char *func, const char *file, int line, size_t size) |
| void * | pinned_malloc_ (const char *func, const char *file, int line, size_t size) |
| void * | mapped_malloc_ (const char *func, const char *file, int line, size_t size) |
| void | device_free_ (const char *func, const char *file, int line, void *ptr) |
| void | device_pinned_free_ (const char *func, const char *file, int line, void *ptr) |
| void | host_free_ (const char *func, const char *file, int line, void *ptr) |
| constexpr const char * | str_end (const char *str) |
| constexpr bool | str_slant (const char *str) |
| constexpr const char * | r_slant (const char *str) |
| constexpr const char * | file_name (const char *str) |
| double | computeMomAction (const GaugeField &mom) |
| Compute and return global the momentum action 1/2 mom^2. More... | |
| void | updateMomentum (GaugeField &mom, double coeff, GaugeField &force) |
| void | applyU (GaugeField &force, GaugeField &U) |
| void | ApplyCoarse (ColorSpinorField &out, const ColorSpinorField &inA, const ColorSpinorField &inB, const GaugeField &Y, const GaugeField &X, double kappa, int parity=QUDA_INVALID_PARITY, bool dslash=true, bool clover=true, bool dagger=false) |
| void | CoarseOp (GaugeField &Y, GaugeField &X, GaugeField &Xinv, GaugeField &Yhat, const Transfer &T, const cudaGaugeField &gauge, const cudaCloverField *clover, double kappa, double mu, double mu_factor, QudaDiracType dirac, QudaMatPCType matpc) |
| Coarse operator construction from a fine-grid operator (Wilson / Clover) More... | |
| void | CoarseCoarseOp (GaugeField &Y, GaugeField &X, GaugeField &Xinv, GaugeField &Yhat, const Transfer &T, const GaugeField &gauge, const GaugeField &clover, const GaugeField &cloverInv, double kappa, double mu, double mu_factor, QudaDiracType dirac, QudaMatPCType matpc) |
| Coarse operator construction from an intermediate-grid operator (Coarse) More... | |
| void | Monte (cudaGaugeField &data, RNG &rngstate, double Beta, int nhb, int nover) |
| Perform heatbath and overrelaxation. Performs nhb heatbath steps followed by nover overrelaxation steps. More... | |
| void | InitGaugeField (cudaGaugeField &data) |
| Perform a cold start to the gauge field, identity SU(3) matrix, also fills the ghost links in multi-GPU case (no need to exchange data) More... | |
| void | InitGaugeField (cudaGaugeField &data, RNG &rngstate) |
| Perform a hot start to the gauge field, random SU(3) matrix, followed by reunitarization, also exchange borders links in multi-GPU case. More... | |
| void | PGaugeExchange (cudaGaugeField &data, const int dir, const int parity) |
| Perform heatbath and overrelaxation. Performs nhb heatbath steps followed by nover overrelaxation steps. More... | |
| void | PGaugeExchangeFree () |
| Release all allocated memory used to exchange data between nodes. More... | |
| double2 | getLinkDeterminant (cudaGaugeField &data) |
| Calculate the Determinant. More... | |
| double2 | getLinkTrace (cudaGaugeField &data) |
| Calculate the Trace. More... | |
| void | arpackSolve (std::vector< ColorSpinorField *> &B, void *evals, DiracMatrix &matEigen, QudaPrecision matPrec, QudaPrecision arpackPrec, double tol, int nev, int ncv, char *target) |
| void | qudaMemcpy_ (void *dst, const void *src, size_t count, cudaMemcpyKind kind, const char *func, const char *file, const char *line) |
| Wrapper around cudaMemcpy used for auto-profiling. Do not call directly, rather call macro below which will grab the location of the call. More... | |
| void | qudaMemcpyAsync_ (void *dst, const void *src, size_t count, cudaMemcpyKind kind, const cudaStream_t &stream, const char *func, const char *file, const char *line) |
| Wrapper around cudaMemcpyAsync or driver API equivalent Potentially add auto-profiling support. More... | |
| void | qudaMemcpy2DAsync_ (void *dst, size_t dpitch, const void *src, size_t spitch, size_t width, size_t hieght, cudaMemcpyKind kind, const cudaStream_t &stream, const char *func, const char *file, const char *line) |
| Wrapper around cudaMemcpy2DAsync or driver API equivalent Potentially add auto-profiling support. More... | |
| cudaError_t | qudaLaunchKernel (const void *func, dim3 gridDim, dim3 blockDim, void **args, size_t sharedMem, cudaStream_t stream) |
| Wrapper around cudaLaunchKernel. More... | |
| cudaError_t | qudaEventQuery (cudaEvent_t &event) |
| Wrapper around cudaEventQuery or cuEventQuery. More... | |
| cudaError_t | qudaEventRecord (cudaEvent_t &event, cudaStream_t stream=0) |
| Wrapper around cudaEventRecord or cuEventRecord. More... | |
| cudaError_t | qudaStreamWaitEvent (cudaStream_t stream, cudaEvent_t event, unsigned int flags) |
| Wrapper around cudaEventRecord or cuEventRecord. More... | |
| cudaError_t | qudaStreamSynchronize (cudaStream_t &stream) |
| Wrapper around cudaStreamSynchronize or cuStreamSynchronize. More... | |
| cudaError_t | qudaEventSynchronize (cudaEvent_t &event) |
| Wrapper around cudaEventSynchronize or cuEventSynchronize. More... | |
| cudaError_t | qudaDeviceSynchronize () |
| Wrapper around cudaDeviceSynchronize or cuDeviceSynchronize. More... | |
| void | printAPIProfile () |
| Print out the timer profile for CUDA API calls. More... | |
| bool | canReuseResidentGauge (QudaInvertParam *inv_param) |
| template<class Real > | |
| __device__ Real | Random (cuRNGState &state, Real a, Real b) |
| Return a random number between a and b. More... | |
| template<> | |
| __device__ float | Random< float > (cuRNGState &state, float a, float b) |
| template<> | |
| __device__ double | Random< double > (cuRNGState &state, double a, double b) |
| template<class Real > | |
| __device__ Real | Random (cuRNGState &state) |
| Return a random number between 0 and 1. More... | |
| template<> | |
| __device__ float | Random< float > (cuRNGState &state) |
| template<> | |
| __device__ double | Random< double > (cuRNGState &state) |
| template<typename T1 , typename T2 > | |
| __host__ __device__ void | copy (T1 &a, const T2 &b) |
| template<> | |
| __host__ __device__ void | copy (double &a, const int2 &b) |
| template<> | |
| __host__ __device__ void | copy (double2 &a, const int4 &b) |
| static __host__ __device__ float | s2f (const short &a) |
| static __host__ __device__ double | s2d (const short &a) |
| __device__ __host__ int | f2i (float f) |
| __device__ __host__ int | d2i (double d) |
| template<> | |
| __host__ __device__ void | copy (float &a, const short &b) |
| template<> | |
| __host__ __device__ void | copy (short &a, const float &b) |
| template<> | |
| __host__ __device__ void | copy (float2 &a, const short2 &b) |
| template<> | |
| __host__ __device__ void | copy (short2 &a, const float2 &b) |
| template<> | |
| __host__ __device__ void | copy (float4 &a, const short4 &b) |
| template<> | |
| __host__ __device__ void | copy (short4 &a, const float4 &b) |
| template<typename VectorType > | |
| __device__ __host__ VectorType | vector_load (void *ptr, int idx) |
| template<typename VectorType > | |
| __device__ __host__ void | vector_store (void *ptr, int idx, const VectorType &value) |
| template<> | |
| __device__ __host__ void | vector_store (void *ptr, int idx, const double2 &value) |
| template<> | |
| __device__ __host__ void | vector_store (void *ptr, int idx, const float4 &value) |
| template<> | |
| __device__ __host__ void | vector_store (void *ptr, int idx, const float2 &value) |
| template<> | |
| __device__ __host__ void | vector_store (void *ptr, int idx, const short4 &value) |
| template<> | |
| __device__ __host__ void | vector_store (void *ptr, int idx, const short2 &value) |
| void | computeStaggeredOprod (GaugeField *out[], ColorSpinorField &in, const double coeff[], int nFace) |
| Compute the outer-product field between the staggered quark field's one and (for HISQ and ASQTAD) three hop sites. E.g.,. More... | |
| void | ApplyLaplace (ColorSpinorField &out, const ColorSpinorField &in, const GaugeField &U, double kappa, const ColorSpinorField *x, int parity) |
| Driver for applying the Laplace stencil. More... | |
| template<typename Float2 , typename Float > | |
| __host__ __device__ int | checkUnitary (Matrix< Float2, 3 > &inv, Matrix< Float2, 3 > in, const Float tol) |
| Check the unitarity of the input matrix to a given tolerance. More... | |
| template<typename Float2 > | |
| __host__ __device__ int | checkUnitaryPrint (Matrix< Float2, 3 > &inv, Matrix< Float2, 3 > in) |
| Check the unitarity of the input matrix to a given tolerance (1e-14) and print out deviation for each component (used for debugging only). More... | |
| template<typename Float > | |
| __host__ __device__ void | polarSu3 (Matrix< complex< Float >, 3 > &in, Float tol) |
| Project the input matrix on the SU(3) group. First unitarize the matrix and then project onto the special unitary group. More... | |
| void | FillV (ColorSpinorField &V, const std::vector< ColorSpinorField *> &B, int Nvec) |
| void | BlockOrthogonalize (ColorSpinorField &V, int Nvec, const int *geo_bs, const int *fine_to_coarse, int spin_bs) |
| Block orthogonnalize the matrix field, where the blocks are defined by lookup tables that map the fine grid points to the coarse grid points, and similarly for the spin degrees of freedom. More... | |
| void | Prolongate (ColorSpinorField &out, const ColorSpinorField &in, const ColorSpinorField &v, int Nvec, const int *fine_to_coarse, const int *spin_map, int parity=QUDA_INVALID_PARITY) |
| Apply the prolongation operator. More... | |
| void | Restrict (ColorSpinorField &out, const ColorSpinorField &in, const ColorSpinorField &v, int Nvec, const int *fine_to_coarse, const int *coarse_to_fine, const int *spin_map, int parity=QUDA_INVALID_PARITY) |
| Apply the restriction operator. More... | |
| bool | activeTuning () |
| query if tuning is in progress More... | |
| void | loadTuneCache () |
| void | saveTuneCache () |
| void | saveProfile (const std::string label="") |
| Save profile to disk. More... | |
| void | flushProfile () |
| Flush profile contents, setting all counts to zero. More... | |
| TuneParam & | tuneLaunch (Tunable &tunable, QudaTune enabled, QudaVerbosity verbosity) |
| void | u32toa (char *buffer, uint32_t value) |
| void | i32toa (char *buffer, int32_t value) |
| void | u64toa (char *buffer, uint64_t value) |
| void | i64toa (char *buffer, int64_t value) |
| void | setUnitarizeLinksConstants (double unitarize_eps, double max_error, bool allow_svd, bool svd_only, double svd_rel_error, double svd_abs_error) |
| void | unitarizeLinksCPU (cpuGaugeField &outfield, const cpuGaugeField &infield) |
| void | unitarizeLinks (cudaGaugeField &outfield, const cudaGaugeField &infield, int *fails) |
| void | unitarizeLinks (cudaGaugeField &outfield, int *fails) |
| bool | isUnitary (const cpuGaugeField &field, double max_error) |
| void | projectSU3 (cudaGaugeField &U, double tol, int *fails) |
| Project the input gauge field onto the SU(3) group. This is a destructive operation. The number of link failures is reported so appropriate action can be taken. More... | |
| template<typename Arg > | |
| __device__ __host__ uint64_t | siteChecksum (const Arg &arg, int d, int parity, int x_cb) |
| template<typename Arg > | |
| uint64_t | ChecksumCPU (const Arg &arg) |
| template<typename real , typename Link > | |
| __device__ void | axpy (real a, const real *x, Link &y) |
| template<typename real , typename Link > | |
| __device__ void | operator+= (real *y, const Link &x) |
| template<typename real , typename Link > | |
| __device__ void | operator-= (real *y, const Link &x) |
| ColorSpinorParam | colorSpinorParam (const CloverField &a, bool inverse) |
| template<bool from_coarse, typename Float , int dim, QudaDirection dir, int fineSpin, int fineColor, int coarseSpin, int coarseColor, typename Arg > | |
| __device__ __host__ void | computeUV (Arg &arg, int parity, int x_cb, int ic_c) |
| template<bool from_coarse, typename Float , int dim, QudaDirection dir, int fineSpin, int fineColor, int coarseSpin, int coarseColor, typename Arg > | |
| void | ComputeUVCPU (Arg &arg) |
| template<bool from_coarse, typename Float , int dim, QudaDirection dir, int fineSpin, int fineColor, int coarseSpin, int coarseColor, typename Arg > | |
| __global__ void | ComputeUVGPU (Arg arg) |
| template<typename Float , int fineSpin, int fineColor, int coarseColor, typename Arg > | |
| __device__ __host__ void | computeAV (Arg &arg, int parity, int x_cb, int ic_c) |
| template<typename Float , int fineSpin, int fineColor, int coarseColor, typename Arg > | |
| void | ComputeAVCPU (Arg &arg) |
| template<typename Float , int fineSpin, int fineColor, int coarseColor, typename Arg > | |
| __global__ void | ComputeAVGPU (Arg arg) |
| template<typename Float , int fineSpin, int fineColor, int coarseColor, typename Arg > | |
| __device__ __host__ void | computeTMAV (Arg &arg, int parity, int x_cb, int v) |
| template<typename Float , int fineSpin, int fineColor, int coarseColor, typename Arg > | |
| void | ComputeTMAVCPU (Arg &arg) |
| template<typename Float , int fineSpin, int fineColor, int coarseColor, typename Arg > | |
| __global__ void | ComputeTMAVGPU (Arg arg) |
| template<typename Float , int fineSpin, int fineColor, int coarseColor, typename Arg > | |
| __device__ __host__ void | computeTMCAV (Arg &arg, int parity, int x_cb) |
| template<typename Float , int fineSpin, int fineColor, int coarseColor, typename Arg > | |
| void | ComputeTMCAVCPU (Arg &arg) |
| template<typename Float , int fineSpin, int fineColor, int coarseColor, typename Arg > | |
| __global__ void | ComputeTMCAVGPU (Arg arg) |
| template<bool from_coarse, typename Float , int dim, QudaDirection dir, int fineSpin, int fineColor, int coarseSpin, int coarseColor, typename Arg > | |
| __device__ __host__ void | multiplyVUV (complex< Float > vuv[], Arg &arg, int parity, int x_cb, int ic_c) |
| Do a single (AV)^ * UV product, where for preconditioned clover, AV correspond to the clover inverse multiplied by the packed null space vectors, else AV is simply the packed null space vectors. More... | |
| template<bool from_coarse, typename Float , int dim, QudaDirection dir, int fineSpin, int fineColor, int coarseSpin, int coarseColor, typename Arg > | |
| __device__ __host__ void | computeVUV (Arg &arg, int parity, int x_cb, int c_row) |
| template<bool from_coarse, typename Float , int dim, QudaDirection dir, int fineSpin, int fineColor, int coarseSpin, int coarseColor, typename Arg > | |
| void | ComputeVUVCPU (Arg arg) |
| template<bool from_coarse, typename Float , int dim, QudaDirection dir, int fineSpin, int fineColor, int coarseSpin, int coarseColor, typename Arg > | |
| __global__ void | ComputeVUVGPU (Arg arg) |
| template<typename Float , int nSpin, int nColor, typename Arg > | |
| __device__ __host__ void | computeYreverse (Arg &arg, int parity, int x_cb) |
| template<typename Float , int nSpin, int nColor, typename Arg > | |
| void | ComputeYReverseCPU (Arg &arg) |
| template<typename Float , int nSpin, int nColor, typename Arg > | |
| __global__ void | ComputeYReverseGPU (Arg arg) |
| template<bool bidirectional, typename Float , int nSpin, int nColor, typename Arg > | |
| __device__ __host__ void | computeCoarseLocal (Arg &arg, int parity, int x_cb) |
| template<bool bidirectional, typename Float , int nSpin, int nColor, typename Arg > | |
| void | ComputeCoarseLocalCPU (Arg &arg) |
| template<bool bidirectional, typename Float , int nSpin, int nColor, typename Arg > | |
| __global__ void | ComputeCoarseLocalGPU (Arg arg) |
| template<bool from_coarse, typename Float , int fineSpin, int coarseSpin, int fineColor, int coarseColor, typename Arg > | |
| __device__ __host__ void | computeCoarseClover (Arg &arg, int parity, int x_cb, int ic_c) |
| template<bool from_coarse, typename Float , int fineSpin, int coarseSpin, int fineColor, int coarseColor, typename Arg > | |
| void | ComputeCoarseCloverCPU (Arg &arg) |
| template<bool from_coarse, typename Float , int fineSpin, int coarseSpin, int fineColor, int coarseColor, typename Arg > | |
| __global__ void | ComputeCoarseCloverGPU (Arg arg) |
| template<typename Float , int nSpin, int nColor, typename Arg > | |
| void | AddCoarseDiagonalCPU (Arg &arg) |
| template<typename Float , int nSpin, int nColor, typename Arg > | |
| __global__ void | AddCoarseDiagonalGPU (Arg arg) |
| template<typename Float , int nSpin, int nColor, typename Arg > | |
| void | AddCoarseTmDiagonalCPU (Arg &arg) |
| template<typename Float , int nSpin, int nColor, typename Arg > | |
| __global__ void | AddCoarseTmDiagonalGPU (Arg arg) |
| template<typename Float , int n, typename Arg > | |
| __device__ __host__ void | computeYhat (Arg &arg, int d, int x_cb, int parity, int i) |
| template<typename Float , int n, typename Arg > | |
| void | CalculateYhatCPU (Arg &arg) |
| template<typename Float , int n, typename Arg > | |
| __global__ void | CalculateYhatGPU (Arg arg) |
| template<bool from_coarse, typename Float , int fineSpin, int fineColor, int coarseSpin, int coarseColor, QudaGaugeFieldOrder gOrder, typename F , typename Ftmp , typename coarseGauge , typename fineGauge , typename fineClover > | |
| void | calculateY (coarseGauge &Y, coarseGauge &X, coarseGauge &Xinv, Ftmp &UV, F &AV, F &V, fineGauge &G, fineClover &C, fineClover &Cinv, GaugeField &Y_, GaugeField &X_, GaugeField &Xinv_, GaugeField &Yhat_, ColorSpinorField &av, const ColorSpinorField &v, double kappa, double mu, double mu_factor, QudaDiracType dirac, QudaMatPCType matpc) |
| Calculate the coarse-link field, include the clover field, and its inverse, and finally also compute the preconditioned coarse link field. More... | |
| std::ostream & | operator<< (std::ostream &out, const ColorSpinorField &a) |
| template<typename Float , int Ns, int Ms, int Nc, int Mc, int nDim, typename Arg > | |
| __device__ __host__ void | packGhost (Arg &arg, int cb_idx, int parity, int spinor_parity, int spin_block, int color_block) |
| template<typename Float , int Ns, int Ms, int Nc, int Mc, int nDim, typename Arg > | |
| void | GenericPackGhost (Arg &arg) |
| template<typename Float , int Ns, int Ms, int Nc, int Mc, int nDim, typename Arg > | |
| __global__ void | GenericPackGhostKernel (Arg arg) |
| template<class T > | |
| void | random (T &t) |
| template<class T > | |
| void | point (T &t, int x, int s, int c) |
| template<class T > | |
| void | constant (T &t, int k, int s, int c) |
| template<class P > | |
| void | sin (P &p, int d, int n, int offset) |
| template<class U , class V > | |
| int | compareSpinor (const U &u, const V &v, const int tol) |
| template<class Order > | |
| void | print_vector (const Order &o, unsigned int x) |
| template<typename Float , int Nc, typename Vector , typename Arg > | |
| __device__ __host__ void | computeNeighborSum (Vector &out, Arg &arg, int x_cb, int parity) |
| template<typename Float , int Ns, int Nc, typename Arg > | |
| __device__ __host__ void | computeWupperalStep (Arg &arg, int x_cb, int parity) |
| template<typename Float , int Ns, int Nc, typename Arg > | |
| void | wuppertalStepCPU (Arg arg) |
| template<typename Float , int Ns, int Nc, typename Arg > | |
| __global__ void | wuppertalStepGPU (Arg arg) |
| void | copyGenericColorSpinorDD (ColorSpinorField &, const ColorSpinorField &, QudaFieldLocation, void *, void *, void *a=0, void *b=0) |
| void | copyGenericColorSpinorDS (ColorSpinorField &, const ColorSpinorField &, QudaFieldLocation, void *, void *, void *a=0, void *b=0) |
| void | copyGenericColorSpinorDH (ColorSpinorField &, const ColorSpinorField &, QudaFieldLocation, void *, void *, void *a=0, void *b=0) |
| void | copyGenericColorSpinorSD (ColorSpinorField &, const ColorSpinorField &, QudaFieldLocation, void *, void *, void *a=0, void *b=0) |
| void | copyGenericColorSpinorSS (ColorSpinorField &, const ColorSpinorField &, QudaFieldLocation, void *, void *, void *a=0, void *b=0) |
| void | copyGenericColorSpinorSH (ColorSpinorField &, const ColorSpinorField &, QudaFieldLocation, void *, void *, void *a=0, void *b=0) |
| void | copyGenericColorSpinorHD (ColorSpinorField &, const ColorSpinorField &, QudaFieldLocation, void *, void *, void *a=0, void *b=0) |
| void | copyGenericColorSpinorHS (ColorSpinorField &, const ColorSpinorField &, QudaFieldLocation, void *, void *, void *a=0, void *b=0) |
| void | copyGenericColorSpinorHH (ColorSpinorField &, const ColorSpinorField &, QudaFieldLocation, void *, void *, void *a=0, void *b=0) |
| void | copyGenericColorSpinorMGDD (ColorSpinorField &, const ColorSpinorField &, QudaFieldLocation, void *, void *, void *a=0, void *b=0) |
| void | copyGenericColorSpinorMGDS (ColorSpinorField &, const ColorSpinorField &, QudaFieldLocation, void *, void *, void *a=0, void *b=0) |
| void | copyGenericColorSpinorMGSD (ColorSpinorField &, const ColorSpinorField &, QudaFieldLocation, void *, void *, void *a=0, void *b=0) |
| void | copyGenericColorSpinorMGSS (ColorSpinorField &, const ColorSpinorField &, QudaFieldLocation, void *, void *, void *a=0, void *b=0) |
| template<typename FloatOut , typename FloatIn , int Ns, int Nc, typename Arg , typename Basis > | |
| void | copyColorSpinor (Arg &arg, const Basis &basis) |
| template<typename FloatOut , typename FloatIn , int Ns, int Nc, typename Arg , typename Basis > | |
| __global__ void | copyColorSpinorKernel (Arg arg, Basis basis) |
| template<typename FloatOut , typename FloatIn , int Ns, int Nc, typename Out , typename In > | |
| void | genericCopyColorSpinor (Out &outOrder, const In &inOrder, const ColorSpinorField &out, const ColorSpinorField &in, QudaFieldLocation location) |
| template<typename FloatOut , typename FloatIn , int Ns, int Nc, typename InOrder > | |
| void | genericCopyColorSpinor (InOrder &inOrder, ColorSpinorField &out, const ColorSpinorField &in, QudaFieldLocation location, FloatOut *Out, float *outNorm) |
| template<typename FloatOut , typename FloatIn , int Ns, int Nc> | |
| void | genericCopyColorSpinor (ColorSpinorField &out, const ColorSpinorField &in, QudaFieldLocation location, FloatOut *Out, FloatIn *In, float *outNorm, float *inNorm) |
| template<int Ns, int Nc, typename dstFloat , typename srcFloat > | |
| void | copyGenericColorSpinor (ColorSpinorField &dst, const ColorSpinorField &src, QudaFieldLocation location, dstFloat *Dst, srcFloat *Src, float *dstNorm, float *srcNorm) |
| template<int Nc, typename dstFloat , typename srcFloat > | |
| void | CopyGenericColorSpinor (ColorSpinorField &dst, const ColorSpinorField &src, QudaFieldLocation location, dstFloat *Dst, srcFloat *Src, float *dstNorm=0, float *srcNorm=0) |
| template<typename FloatOut , typename FloatIn , int Ns, int Nc, typename OutOrder , typename InOrder > | |
| void | packSpinor (OutOrder &outOrder, const InOrder &inOrder, int volume) |
| template<typename FloatOut , typename FloatIn , int Ns, int Nc, typename OutOrder , typename InOrder > | |
| __global__ void | packSpinorKernel (OutOrder outOrder, const InOrder inOrder, int volume) |
| template<typename FloatOut , typename FloatIn , int Ns, int Nc, typename OutOrder , typename InOrder > | |
| void | genericCopyColorSpinor (OutOrder &outOrder, const InOrder &inOrder, const ColorSpinorField &out, QudaFieldLocation location) |
| template<typename FloatOut , typename FloatIn , int Ns, int Nc, typename InOrder > | |
| void | genericCopyColorSpinor (InOrder &inOrder, ColorSpinorField &out, QudaFieldLocation location, FloatOut *Out) |
| template<typename FloatOut , typename FloatIn , int Ns, int Nc> | |
| void | genericCopyColorSpinor (ColorSpinorField &out, const ColorSpinorField &in, QudaFieldLocation location, FloatOut *Out, FloatIn *In) |
| template<int Ns, int Nc, typename dstFloat , typename srcFloat > | |
| void | copyGenericColorSpinor (ColorSpinorField &dst, const ColorSpinorField &src, QudaFieldLocation location, dstFloat *Dst, srcFloat *Src) |
| template<int Nc, typename dstFloat , typename srcFloat > | |
| void | CopyGenericColorSpinor (ColorSpinorField &dst, const ColorSpinorField &src, QudaFieldLocation location, dstFloat *Dst, srcFloat *Src) |
| void | copyGenericGaugeDoubleOut (GaugeField &out, const GaugeField &in, QudaFieldLocation location, void *Out, void *In, void **ghostOut, void **ghostIn, int type) |
| void | copyGenericGaugeHalfOut (GaugeField &out, const GaugeField &in, QudaFieldLocation location, void *Out, void *In, void **ghostOut, void **ghostIn, int type) |
| void | copyGenericGaugeSingleOut (GaugeField &out, const GaugeField &in, QudaFieldLocation location, void *Out, void *In, void **ghostOut, void **ghostIn, int type) |
| void | copyGenericGaugeMG (GaugeField &out, const GaugeField &in, QudaFieldLocation location, void *Out, void *In, void **ghostOut, void **ghostIn, int type) |
| void | checkMomOrder (const GaugeField &u) |
| template<typename FloatOut , typename FloatIn , int length, typename OutOrder , typename InOrder , bool regularToextended> | |
| __device__ __host__ void | copyGaugeEx (CopyGaugeExArg< OutOrder, InOrder > &arg, int X, int parity) |
| template<typename FloatOut , typename FloatIn , int length, typename OutOrder , typename InOrder , bool regularToextended> | |
| void | copyGaugeEx (CopyGaugeExArg< OutOrder, InOrder > arg) |
| template<typename FloatOut , typename FloatIn , int length, typename OutOrder , typename InOrder , bool regularToextended> | |
| __global__ void | copyGaugeExKernel (CopyGaugeExArg< OutOrder, InOrder > arg) |
| template<typename FloatOut , typename FloatIn , int length, typename OutOrder , typename InOrder > | |
| void | copyGaugeEx (OutOrder outOrder, const InOrder inOrder, const int *E, const int *X, const int *faceVolumeCB, const GaugeField &meta, QudaFieldLocation location) |
| template<typename FloatOut , typename FloatIn , int length, typename InOrder > | |
| void | copyGaugeEx (const InOrder &inOrder, const int *X, GaugeField &out, QudaFieldLocation location, FloatOut *Out) |
| template<typename FloatOut , typename FloatIn , int length> | |
| void | copyGaugeEx (GaugeField &out, const GaugeField &in, QudaFieldLocation location, FloatOut *Out, FloatIn *In) |
| template<typename FloatOut , typename FloatIn > | |
| void | copyGaugeEx (GaugeField &out, const GaugeField &in, QudaFieldLocation location, FloatOut *Out, FloatIn *In) |
| template<typename FloatOut , typename FloatIn , int length, typename OutOrder , typename InOrder > | |
| void | copyGauge (CopyGaugeArg< OutOrder, InOrder > arg) |
| template<typename Float , int length, typename Arg > | |
| void | checkNan (Arg arg) |
| template<typename FloatOut , typename FloatIn , int length, typename OutOrder , typename InOrder > | |
| __global__ void | copyGaugeKernel (CopyGaugeArg< OutOrder, InOrder > arg) |
| template<typename FloatOut , typename FloatIn , int length, typename OutOrder , typename InOrder > | |
| void | copyGhost (CopyGaugeArg< OutOrder, InOrder > arg) |
| template<typename FloatOut , typename FloatIn , int length, typename OutOrder , typename InOrder > | |
| __global__ void | copyGhostKernel (CopyGaugeArg< OutOrder, InOrder > arg) |
| template<typename FloatOut , typename FloatIn , int length, typename OutOrder , typename InOrder > | |
| void | copyGauge (OutOrder &&outOrder, const InOrder &inOrder, int volume, const int *faceVolumeCB, int nDim, int geometry, const GaugeField &out, const GaugeField &in, QudaFieldLocation location, int type) |
| template<typename FloatOut , typename FloatIn , int length, typename InOrder > | |
| void | copyGauge (const InOrder &inOrder, const GaugeField &out, const GaugeField &in, QudaFieldLocation location, FloatOut *Out, FloatOut **outGhost, int type) |
| template<typename FloatOut , typename FloatIn , int length> | |
| void | copyGauge (GaugeField &out, const GaugeField &in, QudaFieldLocation location, FloatOut *Out, FloatIn *In, FloatOut **outGhost, FloatIn **inGhost, int type) |
| template<typename FloatOut , typename FloatIn , int length, typename Out , typename In , typename Arg > | |
| void | copyMom (Arg &arg, const GaugeField &out, const GaugeField &in, QudaFieldLocation location) |
| template<typename FloatOut , typename FloatIn > | |
| void | copyGauge (GaugeField &out, const GaugeField &in, QudaFieldLocation location, FloatOut *Out, FloatIn *In, FloatOut **outGhost, FloatIn **inGhost, int type) |
| template<typename FloatOut , typename FloatIn , int length, typename InOrder > | |
| void | copyGaugeMG (const InOrder &inOrder, GaugeField &out, const GaugeField &in, QudaFieldLocation location, FloatOut *Out, FloatOut **outGhost, int type) |
| template<typename FloatOut , typename FloatIn , int length> | |
| void | copyGaugeMG (GaugeField &out, const GaugeField &in, QudaFieldLocation location, FloatOut *Out, FloatIn *In, FloatOut **outGhost, FloatIn **inGhost, int type) |
| template<typename FloatOut , typename FloatIn > | |
| void | copyGaugeMG (GaugeField &out, const GaugeField &in, QudaFieldLocation location, FloatOut *Out, FloatIn *In, FloatOut **outGhost, FloatIn **inGhost, int type) |
| void * | create_gauge_buffer (size_t bytes, QudaGaugeFieldOrder order, QudaFieldGeometry geometry) |
| void ** | create_ghost_buffer (size_t bytes[], QudaGaugeFieldOrder order, QudaFieldGeometry geometry) |
| void | free_gauge_buffer (void *buffer, QudaGaugeFieldOrder order, QudaFieldGeometry geometry) |
| void | free_ghost_buffer (void **buffer, QudaGaugeFieldOrder order, QudaFieldGeometry geometry) |
| std::ostream & | operator<< (std::ostream &out, const cudaColorSpinorField &a) |
| const map & | getTuneCache () |
| void | disableProfileCount () |
| void | enableProfileCount () |
| void | setPolicyTuning (bool) |
| template<typename Float , int nColor, typename Arg > | |
| void | gammaCPU (Arg arg) |
| template<typename Float , int nColor, int d, typename Arg > | |
| __global__ void | gammaGPU (Arg arg) |
| template<typename Float , int nColor> | |
| void | ApplyGamma (ColorSpinorField &out, const ColorSpinorField &in, int d) |
| template<typename Float > | |
| void | ApplyGamma (ColorSpinorField &out, const ColorSpinorField &in, int d) |
| template<bool doublet, typename Float , int nColor, typename Arg > | |
| void | twistGammaCPU (Arg arg) |
| template<bool doublet, typename Float , int nColor, int d, typename Arg > | |
| __global__ void | twistGammaGPU (Arg arg) |
| template<typename Float , int nSpin, int nColor, typename Arg > | |
| __device__ __host__ void | cloverApply (Arg &arg, int x_cb, int parity) |
| template<typename Float , int nSpin, int nColor, typename Arg > | |
| void | cloverCPU (Arg &arg) |
| template<typename Float , int nSpin, int nColor, typename Arg > | |
| __global__ void | cloverGPU (Arg arg) |
| template<bool inverse, typename Float , int nSpin, int nColor, typename Arg > | |
| __device__ __host__ void | twistCloverApply (Arg &arg, int x_cb, int parity) |
| template<bool inverse, typename Float , int nSpin, int nColor, typename Arg > | |
| void | twistCloverCPU (Arg &arg) |
| template<bool inverse, typename Float , int nSpin, int nColor, typename Arg > | |
| __global__ void | twistCloverGPU (Arg arg) |
| static void | report (const char *type) |
| template<typename FloatOut , typename FloatIn , int Ns, int Nc, typename OutOrder , typename InOrder , typename Basis , bool extend> | |
| __device__ __host__ void | copyInterior (CopySpinorExArg< OutOrder, InOrder, Basis > &arg, int X) |
| template<typename FloatOut , typename FloatIn , int Ns, int Nc, typename OutOrder , typename InOrder , typename Basis , bool extend> | |
| __global__ void | copyInteriorKernel (CopySpinorExArg< OutOrder, InOrder, Basis > arg) |
| template<typename FloatOut , typename FloatIn , int Ns, int Nc, typename OutOrder , typename InOrder , typename Basis , bool extend> | |
| void | copyInterior (CopySpinorExArg< OutOrder, InOrder, Basis > &arg) |
| template<typename FloatOut , typename FloatIn , int Ns, int Nc, typename OutOrder , typename InOrder , typename Basis > | |
| void | copySpinorEx (OutOrder outOrder, const InOrder inOrder, const Basis basis, const int *E, const int *X, const int parity, const bool extend, const ColorSpinorField &meta, QudaFieldLocation location) |
| template<typename FloatOut , typename FloatIn , int Ns, int Nc, typename OutOrder , typename InOrder > | |
| void | copySpinorEx (OutOrder outOrder, InOrder inOrder, const QudaGammaBasis outBasis, const QudaGammaBasis inBasis, const int *E, const int *X, const int parity, const bool extend, const ColorSpinorField &meta, QudaFieldLocation location) |
| template<typename FloatOut , typename FloatIn , int Ns, int Nc, typename InOrder > | |
| void | extendedCopyColorSpinor (InOrder &inOrder, ColorSpinorField &out, QudaGammaBasis inBasis, const int *E, const int *X, const int parity, const bool extend, QudaFieldLocation location, FloatOut *Out, float *outNorm) |
| template<typename FloatOut , typename FloatIn , int Ns, int Nc> | |
| void | extendedCopyColorSpinor (ColorSpinorField &out, const ColorSpinorField &in, const int parity, const QudaFieldLocation location, FloatOut *Out, FloatIn *In, float *outNorm, float *inNorm) |
| template<int Ns, typename dstFloat , typename srcFloat > | |
| void | copyExtendedColorSpinor (ColorSpinorField &dst, const ColorSpinorField &src, const int parity, const QudaFieldLocation location, dstFloat *Dst, srcFloat *Src, float *dstNorm, float *srcNorm) |
| template<typename dstFloat , typename srcFloat > | |
| void | CopyExtendedColorSpinor (ColorSpinorField &dst, const ColorSpinorField &src, const int parity, const QudaFieldLocation location, dstFloat *Dst, srcFloat *Src, float *dstNorm=0, float *srcNorm=0) |
| template<typename Float > | |
| void | extractGhost (const GaugeField &u, Float **Ghost, bool extract, int offset) |
| void | extractGaugeGhostMG (const GaugeField &u, void **ghost, bool extract, int offset) |
| template<typename Float , int length, int dim, typename Arg > | |
| __device__ __host__ void | extractor (Arg &arg, int dir, int a, int b, int c, int d, int g, int parity) |
| template<typename Float , int length, int dim, typename Arg > | |
| __device__ __host__ void | injector (Arg &arg, int dir, int a, int b, int c, int d, int g, int parity) |
| template<typename Float , int length, int nDim, int dim, typename Order , bool extract> | |
| void | extractGhostEx (ExtractGhostExArg< Order, nDim, dim > arg) |
| template<typename Float , int length, int nDim, int dim, typename Order , bool extract> | |
| __global__ void | extractGhostExKernel (ExtractGhostExArg< Order, nDim, dim > arg) |
| template<typename Float , int length, typename Order > | |
| void | extractGhostEx (Order order, const int dim, const int *surfaceCB, const int *E, const int *R, bool extract, const GaugeField &u, QudaFieldLocation location) |
| template<typename Float > | |
| void | extractGhostEx (const GaugeField &u, int dim, const int *R, Float **Ghost, bool extract) |
| template<typename Float , int length, int nDim, typename Order , bool extract> | |
| void | extractGhost (ExtractGhostArg< Order, nDim > arg) |
| template<typename Float , int length, int nDim, typename Order , bool extract> | |
| __global__ void | extractGhostKernel (ExtractGhostArg< Order, nDim > arg) |
| template<typename Float , int length, typename Order > | |
| void | extractGhost (Order order, const GaugeField &u, QudaFieldLocation location, bool extract, int offset) |
| template<typename Float , int Nc> | |
| void | extractGhostMG (const GaugeField &u, Float **Ghost, bool extract, int offset) |
| template<typename Float > | |
| void | extractGhostMG (const GaugeField &u, Float **Ghost, bool extract, int offset) |
| ColorSpinorParam | colorSpinorParam (const GaugeField &a) |
| template<int NCOLORS> | |
| static __host__ __device__ void | IndexBlock (int block, int &p, int &q) |
| template<int blockSize, typename Float , int gauge_dir, int NCOLORS> | |
| __forceinline__ __device__ void | GaugeFixHit_AtomicAdd (Matrix< complex< Float >, NCOLORS > &link, const Float relax_boost, const int tid) |
| template<int blockSize, typename Float , int gauge_dir, int NCOLORS> | |
| __forceinline__ __device__ void | GaugeFixHit_NoAtomicAdd (Matrix< complex< Float >, NCOLORS > &link, const Float relax_boost, const int tid) |
| template<int blockSize, typename Float , int gauge_dir, int NCOLORS> | |
| __forceinline__ __device__ void | GaugeFixHit_NoAtomicAdd_LessSM (Matrix< complex< Float >, NCOLORS > &link, const Float relax_boost, const int tid) |
| template<int blockSize, typename Float , int gauge_dir, int NCOLORS> | |
| __forceinline__ __device__ void | GaugeFixHit_AtomicAdd (Matrix< complex< Float >, NCOLORS > &link, Matrix< complex< Float >, NCOLORS > &link1, const Float relax_boost, const int tid) |
| template<int blockSize, typename Float , int gauge_dir, int NCOLORS> | |
| __forceinline__ __device__ void | GaugeFixHit_NoAtomicAdd (Matrix< complex< Float >, NCOLORS > &link, Matrix< complex< Float >, NCOLORS > &link1, const Float relax_boost, const int tid) |
| template<int blockSize, typename Float , int gauge_dir, int NCOLORS> | |
| __forceinline__ __device__ void | GaugeFixHit_NoAtomicAdd_LessSM (Matrix< complex< Float >, NCOLORS > &link, Matrix< complex< Float >, NCOLORS > &link1, const Float relax_boost, const int tid) |
| template<typename Float , typename GaugeOr , typename GaugeDs , typename Float2 > | |
| __host__ __device__ void | computeStapleRectangle (GaugeOvrImpSTOUTArg< Float, GaugeOr, GaugeDs > &arg, int idx, int parity, int dir, Matrix< Float2, 3 > &staple, Matrix< Float2, 3 > &rectangle) |
| template<typename Float , typename GaugeOr , typename GaugeDs > | |
| __global__ void | computeOvrImpSTOUTStep (GaugeOvrImpSTOUTArg< Float, GaugeOr, GaugeDs > arg) |
| template<typename Float , typename GaugeOr , typename GaugeDs > | |
| void | OvrImpSTOUTStep (GaugeOr origin, GaugeDs dest, const GaugeField &dataOr, Float rho, Float epsilon) |
| template<typename Float > | |
| void | OvrImpSTOUTStep (GaugeField &dataDs, const GaugeField &dataOr, Float rho, Float epsilon) |
| void | printLaunchTimer () |
| void | setDiracPreParam (DiracParam &diracParam, QudaInvertParam *inv_param, const bool pc, bool comms) |
| void | createDirac (Dirac *&d, Dirac *&dSloppy, Dirac *&dPre, QudaInvertParam ¶m, const bool pc_solve) |
| void | massRescale (cudaColorSpinorField &b, QudaInvertParam ¶m) |
| void | fillInnerSolveParam (SolverParam &inner, const SolverParam &outer) |
| int | reliable (double &rNorm, double &maxrx, double &maxrr, const double &r2, const double &delta) |
| template<libtype which_lib> | |
| void | ComputeRitz (EigCGArgs &args) |
| template<> | |
| void | ComputeRitz< libtype::eigen_lib > (EigCGArgs &args) |
| template<> | |
| void | ComputeRitz< libtype::magma_lib > (EigCGArgs &args) |
| static void | fillEigCGInnerSolverParam (SolverParam &inner, const SolverParam &outer, bool use_sloppy_partial_accumulator=true) |
| static void | fillInitCGSolverParam (SolverParam &inner, const SolverParam &outer) |
| double | timeInterval (struct timeval start, struct timeval end) |
| void | computeBeta (Complex **beta, std::vector< ColorSpinorField *> Ap, int i, int N, int k) |
| void | updateAp (Complex **beta, std::vector< ColorSpinorField *> Ap, int begin, int size, int k) |
| void | orthoDir (Complex **beta, std::vector< ColorSpinorField *> Ap, int k, int pipeline) |
| void | backSubs (const Complex *alpha, Complex **const beta, const double *gamma, Complex *delta, int n) |
| void | updateSolution (ColorSpinorField &x, const Complex *alpha, Complex **const beta, double *gamma, int k, std::vector< ColorSpinorField *> p) |
| template<libtype which_lib> | |
| void | ComputeHarmonicRitz (GMResDRArgs &args) |
| template<> | |
| void | ComputeHarmonicRitz< libtype::magma_lib > (GMResDRArgs &args) |
| template<> | |
| void | ComputeHarmonicRitz< libtype::eigen_lib > (GMResDRArgs &args) |
| template<libtype which_lib> | |
| void | ComputeEta (GMResDRArgs &args) |
| template<> | |
| void | ComputeEta< libtype::magma_lib > (GMResDRArgs &args) |
| template<> | |
| void | ComputeEta< libtype::eigen_lib > (GMResDRArgs &args) |
| void | fillFGMResDRInnerSolveParam (SolverParam &inner, const SolverParam &outer) |
| template<typename T > | |
| static void | applyT (T d_out[], const T d_in[], const T gamma[], const T rho[], int N) |
| template<typename T > | |
| static void | applyB (T d_out[], const T d_in[], int N) |
| void | print (const double d[], int n) |
| template<typename T > | |
| static void | zero (T d[], int N) |
| template<typename T > | |
| static void | applyThirdTerm (T d_out[], const T d_in[], int k, int j, int s, const T gamma[], const T rho[], const T gamma_kprev[], const T rho_kprev[]) |
| template<typename T > | |
| static void | computeCoeffs (T d_out[], const T d_p1[], const T d_p2[], int k, int j, int s, const T gamma[], const T rho[], const T gamma_kprev[], const T rho_kprev[]) |
| void | solve (Complex *psi, std::vector< ColorSpinorField *> &p, std::vector< ColorSpinorField *> &q, ColorSpinorField &b) |
| Solve the equation A p_k psi_k = b by minimizing the residual and using Gaussian elimination. More... | |
| void | updateAlphaZeta (double *alpha, double *zeta, double *zeta_old, const double *r2, const double *beta, const double pAp, const double *offset, const int nShift, const int j_low) |
| static void | fillInnerSolverParam (SolverParam &inner, const SolverParam &outer) |
| template<typename Float , typename Oprod , typename Gauge , typename Mom > | |
| __host__ __device__ void | completeKSForceCore (KSForceArg< Oprod, Gauge, Mom > &arg, int idx) |
| template<typename Float , typename Oprod , typename Gauge , typename Mom > | |
| __global__ void | completeKSForceKernel (KSForceArg< Oprod, Gauge, Mom > arg) |
| template<typename Float , typename Oprod , typename Gauge , typename Mom > | |
| void | completeKSForceCPU (KSForceArg< Oprod, Gauge, Mom > &arg) |
| template<typename Float , typename Oprod , typename Gauge , typename Mom > | |
| void | completeKSForce (Oprod oprod, Gauge gauge, Mom mom, int dim[4], const GaugeField &meta, QudaFieldLocation location, long long *flops) |
| template<typename Float , typename Result , typename Oprod , typename Gauge > | |
| __host__ __device__ void | computeKSLongLinkForceCore (KSLongLinkArg< Result, Oprod, Gauge > &arg, int idx) |
| template<typename Float , typename Result , typename Oprod , typename Gauge > | |
| __global__ void | computeKSLongLinkForceKernel (KSLongLinkArg< Result, Oprod, Gauge > arg) |
| template<typename Float , typename Result , typename Oprod , typename Gauge > | |
| void | computeKSLongLinkForceCPU (KSLongLinkArg< Result, Oprod, Gauge > &arg) |
| template<typename Float , typename Result , typename Oprod , typename Gauge > | |
| void | computeKSLongLinkForce (Result res, Oprod oprod, Gauge gauge, int dim[4], const GaugeField &meta, QudaFieldLocation location) |
| template<typename Float > | |
| void | computeKSLongLinkForce (GaugeField &result, const GaugeField &oprod, const GaugeField &gauge, QudaFieldLocation location) |
| template<typename Float , int nDim, int nColor, typename Vector , typename Arg > | |
| __device__ __host__ void | applyLaplace (Vector &out, Arg &arg, int x_cb, int parity) |
| template<typename Float , int nDim, int nColor, typename Arg > | |
| __device__ __host__ void | laplace (Arg &arg, int x_cb, int parity) |
| template<typename Float , int nDim, int nColor, typename Arg > | |
| void | laplaceCPU (Arg arg) |
| template<typename Float , int nDim, int nColor, typename Arg > | |
| __global__ void | laplaceGPU (Arg arg) |
| static void | print_trace (void) |
| static void | print_alloc_header () |
| static void | print_alloc (AllocType type) |
| static void | track_malloc (const AllocType &type, const MemAlloc &a, void *ptr) |
| static void | track_free (const AllocType &type, void *ptr) |
| static void * | aligned_malloc (MemAlloc &a, size_t size) |
| template<typename Float , int Nc, typename Order > | |
| double | maxGauge (const Order order, int volume, int nDim) |
| template<typename Float > | |
| void | arpack_solve (std::vector< ColorSpinorField *> &B, void *evals, DiracMatrix &matEigen, QudaPrecision matPrec, QudaPrecision arpackPrec, double tol, int nev, int ncv, char *target) |
| template<class T > | |
| __device__ __host__ T | getTrace (const Matrix< T, 3 > &a) |
| template<template< typename, int > class Mat, class T > | |
| __device__ __host__ T | getDeterminant (const Mat< T, 3 > &a) |
| template<template< typename, int > class Mat, class T , int N> | |
| __device__ __host__ Mat< T, N > | operator+ (const Mat< T, N > &a, const Mat< T, N > &b) |
| template<template< typename, int > class Mat, class T , int N> | |
| __device__ __host__ Mat< T, N > | operator+= (Mat< T, N > &a, const Mat< T, N > &b) |
| template<template< typename, int > class Mat, class T , int N> | |
| __device__ __host__ Mat< T, N > | operator+= (Mat< T, N > &a, const T &b) |
| template<template< typename, int > class Mat, class T , int N> | |
| __device__ __host__ Mat< T, N > | operator-= (Mat< T, N > &a, const Mat< T, N > &b) |
| template<template< typename, int > class Mat, class T , int N> | |
| __device__ __host__ Mat< T, N > | operator- (const Mat< T, N > &a, const Mat< T, N > &b) |
| template<template< typename, int > class Mat, class T , int N, class S > | |
| __device__ __host__ Mat< T, N > | operator* (const S &scalar, const Mat< T, N > &a) |
| template<template< typename, int > class Mat, class T , int N, class S > | |
| __device__ __host__ Mat< T, N > | operator* (const Mat< T, N > &a, const S &scalar) |
| template<template< typename, int > class Mat, class T , int N, class S > | |
| __device__ __host__ Mat< T, N > | operator*= (Mat< T, N > &a, const S &scalar) |
| template<template< typename, int > class Mat, class T , int N> | |
| __device__ __host__ Mat< T, N > | operator- (const Mat< T, N > &a) |
| template<template< typename, int > class Mat, class T , int N> | |
| __device__ __host__ Mat< T, N > | operator* (const Mat< T, N > &a, const Mat< T, N > &b) |
| Generic implementation of matrix multiplication. More... | |
| template<template< typename > class complex, typename T , int N> | |
| __device__ __host__ Matrix< complex< T >, N > | operator* (const Matrix< complex< T >, N > &a, const Matrix< complex< T >, N > &b) |
| Specialization of complex matrix multiplication that will issue optimal fma instructions. More... | |
| template<class T , int N> | |
| __device__ __host__ Matrix< T, N > | operator*= (Matrix< T, N > &a, const Matrix< T, N > &b) |
| template<class T , class U , int N> | |
| __device__ __host__ Matrix< typename PromoteTypeId< T, U >::Type, N > | operator* (const Matrix< T, N > &a, const Matrix< U, N > &b) |
| template<class T > | |
| __device__ __host__ Matrix< T, 2 > | operator* (const Matrix< T, 2 > &a, const Matrix< T, 2 > &b) |
| template<class T , int N> | |
| __device__ __host__ Matrix< T, N > | conj (const Matrix< T, N > &other) |
| template<class T > | |
| __device__ __host__ void | computeMatrixInverse (const Matrix< T, 3 > &u, Matrix< T, 3 > *uinv) |
| template<class T , int N> | |
| __device__ __host__ void | setIdentity (Matrix< T, N > *m) |
| template<int N> | |
| __device__ __host__ void | setIdentity (Matrix< float2, N > *m) |
| template<int N> | |
| __device__ __host__ void | setIdentity (Matrix< double2, N > *m) |
| template<class T , int N> | |
| __device__ __host__ void | setZero (Matrix< T, N > *m) |
| template<int N> | |
| __device__ __host__ void | setZero (Matrix< float2, N > *m) |
| template<int N> | |
| __device__ __host__ void | setZero (Matrix< double2, N > *m) |
| template<typename Complex , int N> | |
| __device__ __host__ void | makeAntiHerm (Matrix< Complex, N > &m) |
| template<class T , int N> | |
| __device__ __host__ void | copyColumn (const Matrix< T, N > &m, int c, Array< T, N > *a) |
| template<class T , int N> | |
| __device__ __host__ void | outerProd (const Array< T, N > &a, const Array< T, N > &b, Matrix< T, N > *m) |
| template<class T , int N> | |
| __device__ __host__ void | outerProd (const T(&a)[N], const T(&b)[N], Matrix< T, N > *m) |
| template<class T , int N> | |
| std::ostream & | operator<< (std::ostream &os, const Matrix< T, N > &m) |
| template<class T , int N> | |
| std::ostream & | operator<< (std::ostream &os, const Array< T, N > &a) |
| template<class T , class U > | |
| __device__ void | loadLinkVariableFromArray (const T *const array, const int dir, const int idx, const int stride, Matrix< U, 3 > *link) |
| template<class T , class U , int N> | |
| __device__ void | loadMatrixFromArray (const T *const array, const int idx, const int stride, Matrix< U, N > *mat) |
| __device__ void | loadLinkVariableFromArray (const float2 *const array, const int dir, const int idx, const int stride, Matrix< complex< double >, 3 > *link) |
| template<class T , int N, class U > | |
| __device__ void | writeMatrixToArray (const Matrix< T, N > &mat, const int idx, const int stride, U *const array) |
| __device__ void | appendMatrixToArray (const Matrix< complex< double >, 3 > &mat, const int idx, const int stride, double2 *const array) |
| __device__ void | appendMatrixToArray (const Matrix< complex< float >, 3 > &mat, const int idx, const int stride, float2 *const array) |
| template<class T , class U > | |
| __device__ void | writeLinkVariableToArray (const Matrix< T, 3 > &link, const int dir, const int idx, const int stride, U *const array) |
| __device__ void | writeLinkVariableToArray (const Matrix< complex< double >, 3 > &link, const int dir, const int idx, const int stride, float2 *const array) |
| template<class T > | |
| __device__ void | loadMomentumFromArray (const T *const array, const int dir, const int idx, const int stride, Matrix< T, 3 > *mom) |
| template<class T , class U > | |
| __device__ void | writeMomentumToArray (const Matrix< T, 3 > &mom, const int dir, const int idx, const U coeff, const int stride, T *const array) |
| template<class Cmplx > | |
| __device__ __host__ void | computeLinkInverse (Matrix< Cmplx, 3 > *uinv, const Matrix< Cmplx, 3 > &u) |
| void | copyArrayToLink (Matrix< float2, 3 > *link, float *array) |
| template<class Cmplx , class Real > | |
| void | copyArrayToLink (Matrix< Cmplx, 3 > *link, Real *array) |
| void | copyLinkToArray (float *array, const Matrix< float2, 3 > &link) |
| template<class Cmplx , class Real > | |
| void | copyLinkToArray (Real *array, const Matrix< Cmplx, 3 > &link) |
| template<class T > | |
| __device__ __host__ Matrix< T, 3 > | getSubTraceUnit (const Matrix< T, 3 > &a) |
| template<class T > | |
| __device__ __host__ void | SubTraceUnit (Matrix< T, 3 > &a) |
| template<class T > | |
| __device__ __host__ double | getRealTraceUVdagger (const Matrix< T, 3 > &a, const Matrix< T, 3 > &b) |
| template<class Cmplx > | |
| __host__ __device__ void | printLink (const Matrix< Cmplx, 3 > &link) |
| template<class Cmplx > | |
| __device__ __host__ bool | isUnitary (const Matrix< Cmplx, 3 > &matrix, double max_error) |
| template<class Cmplx > | |
| __device__ __host__ double | ErrorSU3 (const Matrix< Cmplx, 3 > &matrix) |
| template<class T > | |
| __device__ __host__ void | exponentiate_iQ (const Matrix< T, 3 > &Q, Matrix< T, 3 > *exp_iQ) |
| dim3 | GetBlockDim (size_t threads, size_t size) |
| __global__ void | kernel_random (cuRNGState *state, int seed, int rng_size, int node_offset) |
| CUDA kernel to initialize CURAND RNG states. More... | |
| __global__ void | kernel_random (cuRNGState *state, int seed, int rng_size, int node_offset, rngArg arg) |
| void | launch_kernel_random (cuRNGState *state, int seed, int rng_size, int node_offset, int X[4]) |
| Call CUDA kernel to initialize CURAND RNG states. More... | |
| template<IndexType idxType, typename Int > | |
| __device__ __forceinline__ int | neighborIndex (const unsigned int &cb_idx, const int(&shift)[4], const bool(&partitioned)[4], const unsigned int &parity) |
| template<typename FloatN , int N, typename Output , typename Input > | |
| __global__ void | shiftColorSpinorFieldKernel (ShiftQuarkArg< Output, Input > arg) |
| template<typename FloatN , int N, typename Output , typename Input > | |
| __global__ void | shiftColorSpinorFieldExternalKernel (ShiftQuarkArg< Output, Input > arg) |
| void | shiftColorSpinorField (cudaColorSpinorField &dst, const cudaColorSpinorField &src, const unsigned int parity, const unsigned int dim, const int shift) |
| static void | report (const char *type) |
| template<typename InOrder , typename FloatIn > | |
| __device__ __host__ void | genGauss (InOrder &inOrder, cuRNGState &localState, int x, int s, int c) |
| template<typename FloatIn , int Ns, int Nc, typename InOrder > | |
| void | gaussSpinor (InOrder &inOrder, int volume, RNG rngstate) |
| template<typename FloatIn , int Ns, int Nc, typename InOrder > | |
| __global__ void | gaussSpinorKernel (InOrder inOrder, int volume, RNG rngstate) |
| template<typename FloatIn , int Ns, int Nc, typename InOrder > | |
| void | gaussSpinor (InOrder &inOrder, const ColorSpinorField &meta, RNG &rngstate) |
| template<typename FloatIn , int Ns, int Nc> | |
| void | gaussSpinor (ColorSpinorField &in, RNG &rngstate) |
| void | computeStaggeredOprod (GaugeField &outA, GaugeField &outB, ColorSpinorField &inEven, ColorSpinorField &inOdd, const unsigned int parity, const double coeff[2], int nFace) |
| bool | traceEnabled () |
| static void | deserializeTuneCache (std::istream &in) |
| static void | serializeTuneCache (std::ostream &out) |
| static void | serializeProfile (std::ostream &out, std::ostream &async_out) |
| static void | serializeTrace (std::ostream &out) |
| static void | broadcastTuneCache () |
| bool | policyTuning () |
| template<typename Float , typename G > | |
| __global__ void | ProjectSU3kernel (ProjectSU3Arg< Float, G > arg) |
| void | setTransferGPU (bool) |
Variables | |
| __device__ unsigned int | count [QUDA_MAX_MULTI_REDUCE] = { } |
| __shared__ bool | isLastBlockDone |
| __shared__ volatile bool | isLastWarpDone [16] |
| const int | Nstream = 9 |
| static const char | gDigitsLut [200] |
| static bool | bidirectional_debug = false |
| cudaStream_t * | stream |
| static bool | complete_recv_fwd [QUDA_MAX_DIM] = { } |
| static bool | complete_recv_back [QUDA_MAX_DIM] = { } |
| static bool | complete_send_fwd [QUDA_MAX_DIM] = { } |
| static bool | complete_send_back [QUDA_MAX_DIM] = { } |
| static auto | pinned_allocator = [] (size_t bytes ) { return static_cast<Complex*>(pool_pinned_malloc(bytes)); } |
| static auto | pinned_deleter = [] (Complex *hptr) { pool_pinned_free(hptr); } |
| static bool | dslash_init = false |
| static std::vector< DslashCoarsePolicy > | policy |
| static int | config = 0 |
| static bool | kernelPackT = false |
| static double | unscaled_shifts [QUDA_MAX_MULTI_SHIFT] |
| static int | max_eigcg_cycles = 4 |
| static QudaFieldLocation | reorder_location_ = QUDA_CUDA_FIELD_LOCATION |
| static std::map< void *, MemAlloc > | alloc [N_ALLOC_TYPE] |
| static long | total_bytes [N_ALLOC_TYPE] = {0} |
| static long | max_total_bytes [N_ALLOC_TYPE] = {0} |
| static long | total_host_bytes |
| static long | max_total_host_bytes |
| static long | total_pinned_bytes |
| static long | max_total_pinned_bytes |
| static bool | debug = false |
| static TimeProfile | apiTimer ("CUDA API calls (driver)") |
| static TuneKey | last_key |
| static std::list< TraceKey > | trace_list |
| static bool | enable_trace = false |
| static const std::string | quda_hash = QUDA_HASH |
| static std::string | resource_path |
| static map | tunecache |
| static map::iterator | it |
| static size_t | initial_cache_size = 0 |
| static const std::string | quda_version = STR(QUDA_VERSION_MAJOR) "." STR(QUDA_VERSION_MINOR) "." STR(QUDA_VERSION_SUBMINOR) |
| static bool | tuning = false |
| static bool | profile_count = true |
| static bool | policy_tuning = false |
| static TimeProfile | launchTimer ("tuneLaunch") |
Detailed Description
This is the covariant derivative based on the basic gauged Laplace operator
This code has not been checked. In particular, I suspect it is erroneous in multi-GPU since it looks like the halo ghost region isn't being treated here.
Generic Multi Shift Solver
For staggered, the mass is folded into the dirac operator Otherwise the matrix mass is 'unmodified'.
The lowest offset is in offsets[0]
This is a basic gauged Laplace operator
Typedef Documentation
◆ ColorSpinorFieldSet
| using quda::ColorSpinorFieldSet = typedef ColorSpinorField |
Definition at line 808 of file invert_quda.h.
◆ Complex
| typedef std::complex< double > quda::Complex |
Definition at line 13 of file eig_variables.h.
◆ CompositeColorSpinorField
| typedef std::vector<ColorSpinorField*> quda::CompositeColorSpinorField |
Typedef for a set of spinors. Can be further divided into subsets ,e.g., with different precisions (not implemented currently)
Definition at line 17 of file color_spinor_field.h.
◆ cuRNGState
| typedef struct curandStateMRG32k3a quda::cuRNGState |
Definition at line 17 of file random_quda.h.
◆ DenseMatrix
| typedef MatrixXcd quda::DenseMatrix |
Definition at line 36 of file inv_eigcg_quda.cpp.
◆ DynamicStride
| typedef Stride< Dynamic, Dynamic > quda::DynamicStride |
Definition at line 22 of file deflation.cpp.
◆ map
Definition at line 948 of file dslash_coarse.cu.
◆ RealVector
| using quda::RealVector = typedef VectorXd |
Definition at line 39 of file inv_eigcg_quda.cpp.
◆ RowMajorDenseMatrix
| typedef Matrix< Complex, Dynamic, Dynamic, RowMajor > quda::RowMajorDenseMatrix |
Definition at line 42 of file inv_eigcg_quda.cpp.
◆ Vector
| typedef VectorXcd quda::Vector |
Definition at line 38 of file inv_eigcg_quda.cpp.
◆ VectorSet
| typedef MatrixXcd quda::VectorSet |
Definition at line 37 of file inv_eigcg_quda.cpp.
Enumeration Type Documentation
◆ AllocType
| enum quda::AllocType |
| Enumerator | |
|---|---|
| DEVICE | |
| HOST | |
| PINNED | |
| MAPPED | |
| N_ALLOC_TYPE | |
Definition at line 15 of file malloc.cpp.
◆ BiCGstabLUpdateType
The following code is based on Kate's worker class in Multi-CG.
This worker class is used to update most of the u and r vectors. On BiCG iteration j, r[0] through r[j] and u[0] through u[j] all get updated, but the subsequent mat-vec operation only gets applied to r[j] and u[j]. Thus, we can hide updating r[0] through r[j-1] and u[0] through u[j-1], respectively, in the comms for the matvec on r[j] and u[j]. This results in improved strong scaling for BiCGstab-L.
See paragraphs 2 and 3 in the comments on the Worker class in Multi-CG for more remarks.
| Enumerator | |
|---|---|
| BICGSTABL_UPDATE_U | |
| BICGSTABL_UPDATE_R | |
Definition at line 181 of file inv_bicgstabl_quda.cpp.
◆ ComputeType
| enum quda::ComputeType |
| Enumerator | |
|---|---|
| COMPUTE_UV | |
| COMPUTE_AV | |
| COMPUTE_TMAV | |
| COMPUTE_TMCAV | |
| COMPUTE_VUV | |
| COMPUTE_COARSE_CLOVER | |
| COMPUTE_REVERSE_Y | |
| COMPUTE_COARSE_LOCAL | |
| COMPUTE_DIAGONAL | |
| COMPUTE_TMDIAGONAL | |
| COMPUTE_INVALID | |
Definition at line 916 of file coarse_op.cuh.
◆ DslashCoarsePolicy
Definition at line 863 of file dslash_coarse.cu.
◆ libtype [1/2]
|
strong |
| Enumerator | |
|---|---|
| eigen_lib | |
| magma_lib | |
| lapack_lib | |
| mkl_lib | |
| eigen_lib | |
| magma_lib | |
| lapack_lib | |
| mkl_lib | |
Definition at line 47 of file inv_eigcg_quda.cpp.
◆ libtype [2/2]
|
strong |
| Enumerator | |
|---|---|
| eigen_lib | |
| magma_lib | |
| lapack_lib | |
| mkl_lib | |
| eigen_lib | |
| magma_lib | |
| lapack_lib | |
| mkl_lib | |
Definition at line 57 of file inv_gmresdr_quda.cpp.
◆ MemoryLocation
| enum quda::MemoryLocation |
| Enumerator | |
|---|---|
| Device | |
| Host | |
| Remote | |
Definition at line 15 of file color_spinor_field.h.
◆ QudaProfileType
Definition at line 167 of file quda_internal.h.
Function Documentation
◆ abs() [1/4]
|
inline |
Definition at line 110 of file complex_quda.h.
Referenced by ComputeHarmonicRitz< libtype::eigen_lib >(), ComputeHarmonicRitz< libtype::magma_lib >(), log(), maxGauge(), quda::BiCGstab::operator()(), solve(), sqrt(), and test().

◆ abs() [2/4]
|
inline |
Returns the magnitude of z.
Definition at line 864 of file complex_quda.h.

◆ abs() [3/4]

◆ abs() [4/4]
Definition at line 874 of file complex_quda.h.
Referenced by abs().

◆ acos() [1/2]
|
inline |
Definition at line 50 of file complex_quda.h.
Referenced by exponentiate_iQ().

◆ acos() [2/2]
|
inline |

◆ acosh()
|
inline |
◆ activeTuning()
| bool quda::activeTuning | ( | ) |
query if tuning is in progress
- Returns
- tuning in progress?
Definition at line 103 of file tune.cpp.
References tuning.
Referenced by qudaLaunchKernel().

◆ AddCoarseDiagonalCPU()
| void quda::AddCoarseDiagonalCPU | ( | Arg & | arg | ) |

◆ AddCoarseDiagonalGPU()
| __global__ void quda::AddCoarseDiagonalGPU | ( | Arg | arg | ) |

◆ AddCoarseTmDiagonalCPU()
| void quda::AddCoarseTmDiagonalCPU | ( | Arg & | arg | ) |

◆ AddCoarseTmDiagonalGPU()
| __global__ void quda::AddCoarseTmDiagonalGPU | ( | Arg | arg | ) |

◆ aligned_malloc()
Under CUDA 4.0, cudaHostRegister seems to require that both the beginning and end of the buffer be aligned on page boundaries. This local function takes care of the alignment and gets called by pinned_malloc_() and mapped_malloc_()
Definition at line 139 of file malloc.cpp.
References a, errorQuda, malloc(), posix_memalign(), printfQuda, ptr, and size.
Referenced by mapped_malloc_(), and pinned_malloc_().

◆ APEStep()
| void quda::APEStep | ( | GaugeField & | dataDs, |
| const GaugeField & | dataOr, | ||
| double | alpha | ||
| ) |
Apply APE smearing to the gauge field
- Parameters
-
dataDs Output smeared field dataOr Input gauge field alpha smearing parameter
Definition at line 240 of file gauge_ape.cu.
References errorQuda, float, quda::GaugeField::isNative(), quda::GaugeField::Order(), quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, QUDA_HALF_PRECISION, QUDA_SINGLE_PRECISION, and quda::GaugeField::Reconstruct().
Referenced by performAPEnStep().

◆ appendMatrixToArray() [1/2]
|
inline |
Definition at line 794 of file quda_matrix.h.
References array, fused_exterior_ndeg_tm_dslash_cuda_gen::i, idx, and mat().
◆ appendMatrixToArray() [2/2]
|
inline |
Definition at line 804 of file quda_matrix.h.
References array, fused_exterior_ndeg_tm_dslash_cuda_gen::i, idx, and mat().
◆ applyB()
|
static |
Definition at line 37 of file inv_mpcg_quda.cpp.
References fused_exterior_ndeg_tm_dslash_cuda_gen::i.
Referenced by applyThirdTerm().

◆ ApplyClover()
| void quda::ApplyClover | ( | ColorSpinorField & | out, |
| const ColorSpinorField & | in, | ||
| const CloverField & | clover, | ||
| bool | inverse, | ||
| int | parity | ||
| ) |
Apply clover-matrix field to a color-spinor field.
- Parameters
-
[out] out Result color-spinor field [in] in Input color-spinor field [in] clover Clover-matrix field [in] inverse Whether we are applying the inverse or not [in] Field parity (if color-spinor field is single parity)
Definition at line 557 of file dslash_quda.cu.
References quda::Clover< Float, nSpin, nColor, Arg >::apply(), arg(), checkCudaError, dslash_cuda_gen::clover, errorQuda, in, quda::ColorSpinorField::Nspin(), Nstream, out, parity, and streams.
Referenced by quda::DiracClover::Clover(), and quda::DiracCloverPC::CloverInv().
◆ ApplyCoarse()
| void quda::ApplyCoarse | ( | ColorSpinorField & | out, |
| const ColorSpinorField & | inA, | ||
| const ColorSpinorField & | inB, | ||
| const GaugeField & | Y, | ||
| const GaugeField & | X, | ||
| double | kappa, | ||
| int | parity = QUDA_INVALID_PARITY, |
||
| bool | dslash = true, |
||
| bool | clover = true, |
||
| bool | dagger = false |
||
| ) |
Definition at line 1096 of file dslash_coarse.cu.
References dslash_cuda_gen::clover, deg_tm_dslash_cuda_gen::dagger, kappa, out, parity, policy, and X.
Referenced by quda::DiracCoarse::Clover(), quda::DiracCoarse::CloverInv(), quda::DiracCoarse::Dslash(), quda::DiracCoarsePC::Dslash(), quda::DiracCoarse::DslashXpay(), and quda::DiracCoarse::M().
◆ ApplyCovDev()
| void quda::ApplyCovDev | ( | ColorSpinorField & | out, |
| const ColorSpinorField & | in, | ||
| const GaugeField & | U, | ||
| int | parity, | ||
| int | mu | ||
| ) |
Driver for applying the covariant derivative.
out = U * in
where U is the gauge field in a particular direction.
This operator can be applied to both single parity (checker-boarded) fields, or to full fields.
- Parameters
-
[out] out The output result field [in] in The input field [in] U The gauge field used for the covariant derivative [in] mu Direction of the derivative. For mu > 3 it goes backwards
Definition at line 264 of file covDev.cu.
References quda::Worker::apply(), quda::dslash::aux_worker, quda::LatticeField::bufferIndex, checkLocation, checkPrecision, errorQuda, quda::cpuColorSpinorField::exchangeGhost(), quda::ColorSpinorField::FieldOrder(), in, mu, out, parity, quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, QUDA_SINGLE_PRECISION, and quda::ColorSpinorField::V().
Referenced by quda::GaugeCovDev::DslashCD().
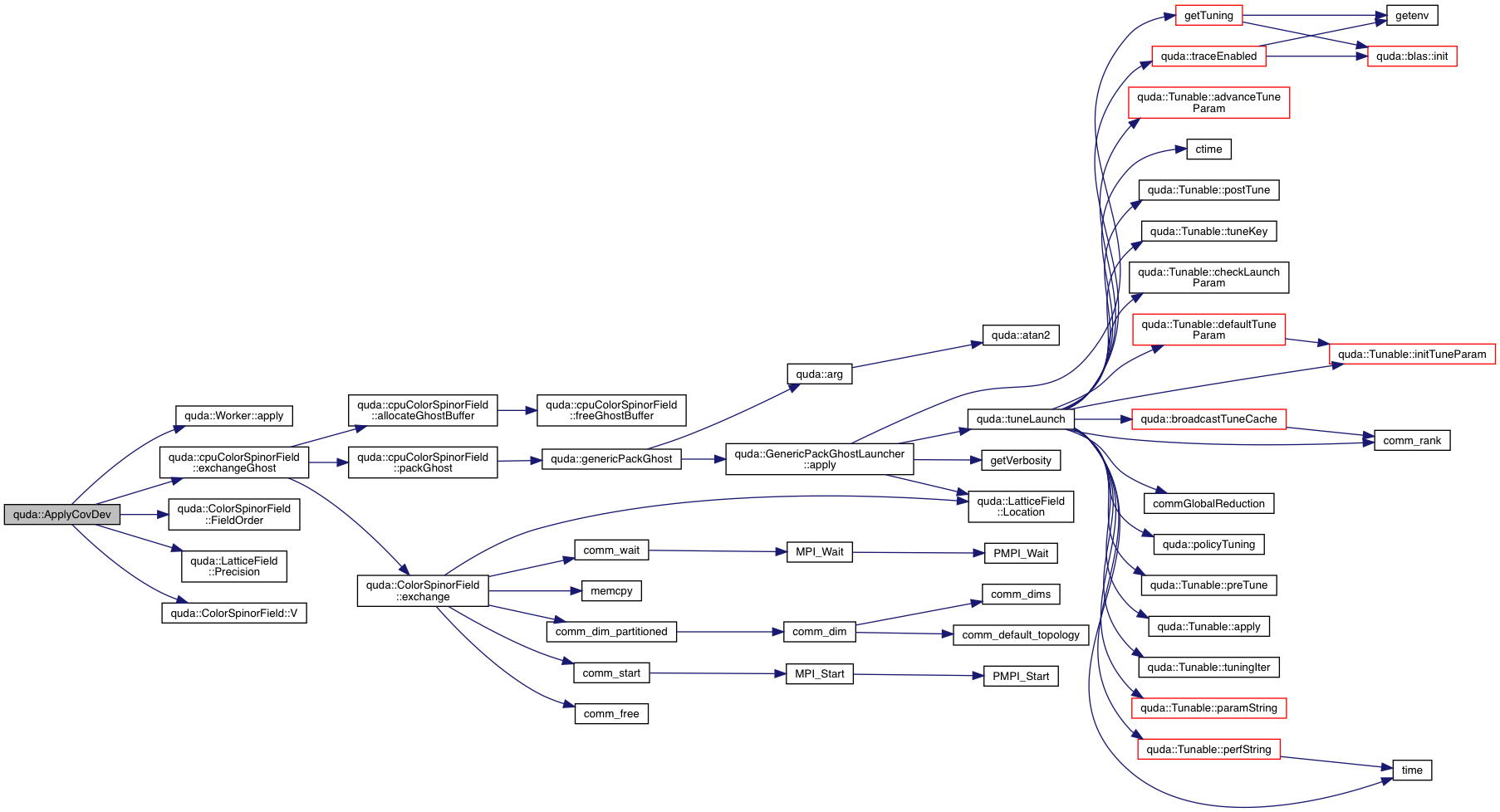

◆ ApplyGamma() [1/2]
| void quda::ApplyGamma | ( | ColorSpinorField & | out, |
| const ColorSpinorField & | in, | ||
| int | d | ||
| ) |
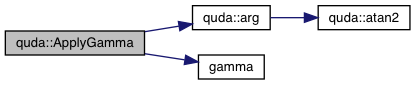

◆ ApplyGamma() [2/2]
| void quda::ApplyGamma | ( | ColorSpinorField & | out, |
| const ColorSpinorField & | in, | ||
| int | d | ||
| ) |
Definition at line 271 of file dslash_quda.cu.
References d, errorQuda, in, quda::ColorSpinorField::Ncolor(), and out.

◆ applyGaugePhase()
| void quda::applyGaugePhase | ( | GaugeField & | u | ) |
Apply the staggered phase factor to the gauge field.
- Parameters
-
[in] u The gauge field to which we apply the staggered phase factors
Definition at line 244 of file gauge_phase.cu.
References errorQuda, quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, and QUDA_SINGLE_PRECISION.
Referenced by quda::GaugeField::applyStaggeredPhase(), and quda::GaugeField::removeStaggeredPhase().


◆ ApplyLaplace()
| void quda::ApplyLaplace | ( | ColorSpinorField & | out, |
| const ColorSpinorField & | in, | ||
| const GaugeField & | U, | ||
| double | kappa, | ||
| const ColorSpinorField * | x, | ||
| int | parity | ||
| ) |
Driver for applying the Laplace stencil.
out = - kappa * A * in
where A is the gauge laplace linear operator.
If x is defined, the operation is given by out = x - kappa * A in. This operator can be applied to both single parity (checker-boarded) fields, or to full fields.
- Parameters
-
[out] out The output result field [in] in The input field [in] U The gauge field used for the gauge Laplace [in] kappa Scale factor applied [in] x Vector field we accumulate onto to
Definition at line 210 of file laplace.cu.
References arg(), in, kappa, laplace(), out, parity, and x.
Referenced by quda::GaugeLaplace::Dslash(), and quda::GaugeLaplace::DslashXpay().

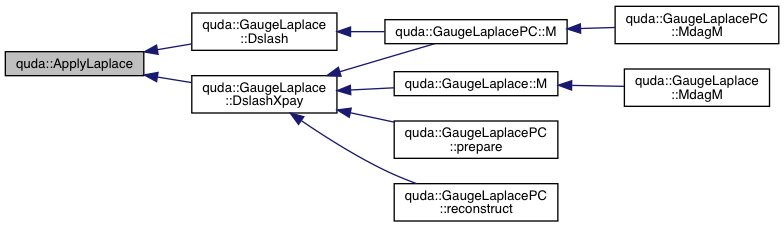
◆ applyLaplace()
|
inline |
Applies the off-diagonal part of the Laplace operator
- Parameters
-
[out] out The out result field [in] U The gauge field [in] kappa Kappa value [in] in The input field [in] parity The site parity [in] x_cb The checkerboarded site index
Definition at line 59 of file laplace.cu.
References arg(), conj(), coord, d, getCoords(), in, linkIndexM1(), linkIndexP1(), nColor, out, and parity.
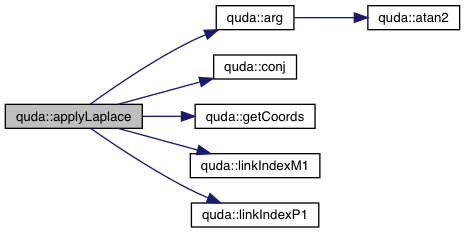
◆ applyT()
|
static |
Definition at line 18 of file inv_mpcg_quda.cpp.
References gamma(), and fused_exterior_ndeg_tm_dslash_cuda_gen::i.
Referenced by applyThirdTerm().


◆ applyThirdTerm()
|
static |
Definition at line 57 of file inv_mpcg_quda.cpp.
References applyB(), applyT(), dim, gamma(), fused_exterior_ndeg_tm_dslash_cuda_gen::i, s, and zero().
Referenced by computeCoeffs().

◆ ApplyTwistClover()
| void quda::ApplyTwistClover | ( | ColorSpinorField & | out, |
| const ColorSpinorField & | in, | ||
| const CloverField & | clover, | ||
| double | kappa, | ||
| double | mu, | ||
| double | epsilon, | ||
| int | parity, | ||
| int | dagger, | ||
| QudaTwistGamma5Type | twist | ||
| ) |
Apply twisted clover-matrix field to a color-spinor field.
- Parameters
-
[out] out Result color-spinor field [in] in Input color-spinor field [in] clover Clover-matrix field [in] kappa kappa parameter [in] mu mu parameter [in] epsilon epsilon parameter [in] Field parity (if color-spinor field is single parity) [in] dagger Whether we are applying the dagger or not [in] twist The type of kernel we are doing if (twist == QUDA_TWIST_GAMMA5_DIRECT) apply (Clover + i*a*gamma_5) to the input spinor else if (twist == QUDA_TWIST_GAMMA5_INVERSE) apply (Clover + i*a*gamma_5)/(Clover^2 + a^2) to the input spinor
Definition at line 708 of file dslash_quda.cu.
References quda::TwistClover< Float, nSpin, nColor, Arg >::apply(), arg(), checkCudaError, dslash_cuda_gen::clover, deg_tm_dslash_cuda_gen::dagger, errorQuda, in, kappa, mu, quda::ColorSpinorField::Nspin(), Nstream, out, parity, QUDA_TWIST_GAMMA5_DIRECT, streams, and deg_tm_dslash_cuda_gen::twist.
Referenced by quda::DiracTwistedClover::twistedCloverApply().

◆ ApplyTwistGamma()
| void quda::ApplyTwistGamma | ( | ColorSpinorField & | out, |
| const ColorSpinorField & | in, | ||
| int | d, | ||
| double | kappa, | ||
| double | mu, | ||
| double | epsilon, | ||
| int | dagger, | ||
| QudaTwistGamma5Type | type | ||
| ) |
Apply the twisted-mass gamma operator to a color-spinor field.
- Parameters
-
[out] out Result color-spinor field [in] in Input color-spinor field [in] d Which gamma matrix we are applying (C counting, so gamma_5 has d=4) [in] kappa kappa parameter [in] mu mu parameter [in] epsilon epsilon parameter [in] dagger Whether we are applying the dagger or not [in] twist The type of kernel we are doing
Definition at line 384 of file dslash_quda.cu.
References arg(), checkCudaError, d, deg_tm_dslash_cuda_gen::dagger, gamma(), in, kappa, mu, Nstream, out, and streams.
Referenced by quda::DiracTwistedMassPC::Dslash(), quda::DiracTwistedMassPC::DslashXpay(), and quda::DiracTwistedMass::twistedApply().

◆ applyU()
| void quda::applyU | ( | GaugeField & | force, |
| GaugeField & | U | ||
| ) |
Left multiply the force field by the gauge field
force = U * force
- Parameters
-
force Force field U Gauge field
Definition at line 340 of file momentum.cu.
References checkCudaError, errorQuda, quda::GaugeField::Order(), quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, and QUDA_FLOAT2_GAUGE_ORDER.
Referenced by computeStaggeredForceQuda().

◆ arg() [1/3]
|
inline |
Returns the phase angle of z.
Definition at line 880 of file complex_quda.h.
Referenced by AddCoarseDiagonalCPU(), AddCoarseDiagonalGPU(), AddCoarseTmDiagonalCPU(), AddCoarseTmDiagonalGPU(), quda::CopyGaugeEx< FloatOut, FloatIn, length, OutOrder, InOrder >::apply(), quda::KSForceComplete< Float, Oprod, Gauge, Mom >::apply(), quda::CopyColorSpinor< FloatOut, FloatIn, Ns, Nc, Arg >::apply(), quda::ExtractGhostEx< Float, length, nDim, dim, Order >::apply(), quda::CopyGauge< FloatOut, FloatIn, length, OutOrder, InOrder, isGhost >::apply(), quda::CopyColorSpinor< FloatOut, FloatIn, 4, Nc, Arg >::apply(), quda::CopySpinorEx< FloatOut, FloatIn, Ns, Nc, OutOrder, InOrder, Basis, extend >::apply(), quda::KSLongLinkForce< Float, Result, Oprod, Gauge >::apply(), ApplyClover(), ApplyGamma(), ApplyLaplace(), applyLaplace(), ApplyTwistClover(), ApplyTwistGamma(), arpack_solve(), blasKernel(), quda::CopyGaugeEx< FloatOut, FloatIn, length, OutOrder, InOrder >::bytes(), quda::CopyColorSpinor< FloatOut, FloatIn, Ns, Nc, Arg >::bytes(), quda::CopyGauge< FloatOut, FloatIn, length, OutOrder, InOrder, isGhost >::bytes(), quda::ExtractGhostEx< Float, length, nDim, dim, Order >::bytes(), quda::CopyColorSpinor< FloatOut, FloatIn, 4, Nc, Arg >::bytes(), quda::CopySpinorEx< FloatOut, FloatIn, Ns, Nc, OutOrder, InOrder, Basis, extend >::bytes(), calculateY(), CalculateYhatCPU(), CalculateYhatGPU(), checkNan(), Checksum(), ChecksumCPU(), cloverApply(), cloverCPU(), cloverGPU(), completeKSForce(), completeKSForceCore(), completeKSForceCPU(), completeKSForceKernel(), compute(), computeAV(), ComputeAVCPU(), ComputeAVGPU(), computeCoarseClover(), ComputeCoarseCloverCPU(), ComputeCoarseCloverGPU(), computeCoarseLocal(), ComputeCoarseLocalCPU(), ComputeCoarseLocalGPU(), computeKSLongLinkForce(), computeKSLongLinkForceCPU(), computeKSLongLinkForceKernel(), computeNeighborSum(), computeOvrImpSTOUTStep(), computeStapleRectangle(), computeTMAV(), ComputeTMAVCPU(), ComputeTMAVGPU(), computeTMCAV(), ComputeTMCAVCPU(), ComputeTMCAVGPU(), computeUV(), ComputeUVCPU(), ComputeUVGPU(), computeVUV(), ComputeVUVCPU(), ComputeVUVGPU(), computeWupperalStep(), computeYhat(), computeYreverse(), ComputeYReverseCPU(), ComputeYReverseGPU(), copyColorSpinor(), quda::CopyColorSpinor< FloatOut, FloatIn, Ns, Nc, Arg >::CopyColorSpinor(), quda::CopyColorSpinor< FloatOut, FloatIn, 4, Nc, Arg >::CopyColorSpinor(), copyColorSpinorKernel(), copyGauge(), quda::CopyGauge< FloatOut, FloatIn, length, OutOrder, InOrder, isGhost >::CopyGauge(), copyGaugeEx(), quda::CopyGaugeEx< FloatOut, FloatIn, length, OutOrder, InOrder >::CopyGaugeEx(), copyGaugeExKernel(), copyGaugeKernel(), copyGhost(), copyGhostKernel(), copyInterior(), copyInteriorKernel(), copyMom(), quda::CopySpinorEx< FloatOut, FloatIn, Ns, Nc, OutOrder, InOrder, Basis, extend >::CopySpinorEx(), copySpinorEx(), extractGhost(), extractGhostEx(), quda::ExtractGhostEx< Float, length, nDim, dim, Order >::ExtractGhostEx(), extractGhostExKernel(), extractGhostKernel(), extractor(), quda::KSForceComplete< Float, Oprod, Gauge, Mom >::flops(), gammaCPU(), gammaGPU(), genericCopyColorSpinor(), GenericPackGhost(), genericPackGhost(), GenericPackGhostKernel(), quda::gauge::Reconstruct< 13, Float >::getPhase(), quda::gauge::Reconstruct< 9, Float >::getPhase(), injector(), kernel_random(), quda::KSForceComplete< Float, Oprod, Gauge, Mom >::KSForceComplete(), quda::KSLongLinkForce< Float, Result, Oprod, Gauge >::KSLongLinkForce(), laplace(), laplaceCPU(), laplaceGPU(), launch_kernel_random(), log(), quda::CopyGaugeEx< FloatOut, FloatIn, length, OutOrder, InOrder >::minThreads(), quda::KSForceComplete< Float, Oprod, Gauge, Mom >::minThreads(), quda::CopySpinorEx< FloatOut, FloatIn, Ns, Nc, OutOrder, InOrder, Basis, extend >::minThreads(), quda::KSLongLinkForce< Float, Result, Oprod, Gauge >::minThreads(), multiblasKernel(), multiplyVUV(), multiReduceKernel(), multiReduceLaunch(), OvrImpSTOUTStep(), packGhost(), projectSU3(), ProjectSU3kernel(), reduce(), reduce2d(), reduceKernel(), reduceLaunch(), reduceRow(), shiftColorSpinorField(), shiftColorSpinorFieldExternalKernel(), shiftColorSpinorFieldKernel(), siteChecksum(), sqrt(), twistCloverApply(), twistCloverCPU(), twistCloverGPU(), twistGammaCPU(), twistGammaGPU(), wuppertalStep(), wuppertalStepCPU(), and wuppertalStepGPU().

◆ arg() [2/3]

◆ arg() [3/3]

◆ arpack_solve()
| void quda::arpack_solve | ( | std::vector< ColorSpinorField *> & | B, |
| void * | evals, | ||
| DiracMatrix & | matEigen, | ||
| QudaPrecision | matPrec, | ||
| QudaPrecision | arpackPrec, | ||
| double | tol, | ||
| int | nev, | ||
| int | ncv, | ||
| char * | target | ||
| ) |
Definition at line 357 of file quda_arpack_interface.cpp.
References arg(), nev, and tol.

◆ arpackSolve()
| void quda::arpackSolve | ( | std::vector< ColorSpinorField *> & | B, |
| void * | evals, | ||
| DiracMatrix & | matEigen, | ||
| QudaPrecision | matPrec, | ||
| QudaPrecision | arpackPrec, | ||
| double | tol, | ||
| int | nev, | ||
| int | ncv, | ||
| char * | target | ||
| ) |
Interface function to the external ARPACK library. This function utilizes ARPACK implemntation of the Implicitly Restarted Arnoldi Method to compute a number of eigenvectors/eigenvalues with user specified features such as those with small real part, small magnitude etc. Parallel version is also supported.
- Parameters
-
[in/out] B Container of eigenvectors [in/out] evals A pointer to eigenvalue array. [in] matEigen Any QUDA implementation of the matrix-vector operation [in] matPrec Precision of the matrix-vector operation [in] arpackPrec Precision of IRAM procedures. [in] tol tolerance for computing eigenvalues with ARPACK [in] nev number of eigenvectors [in] ncv size of the subspace used by IRAM. ncv must satisfy the two inequalities 2 <= ncv-nev and ncv <= *B[0].Length() [in] target eigenvector selection criteria:
'LM' -> want the nev eigenvalues of largest magnitude. 'SM' -> want the nev eigenvalues of smallest magnitude. 'LR' -> want the nev eigenvalues of largest real part. 'SR' -> want the nev eigenvalues of smallest real part. 'LI' -> want the nev eigenvalues of largest imaginary part. 'SI' -> want the nev eigenvalues of smallest imaginary part.
Definition at line 367 of file quda_arpack_interface.cpp.
References errorQuda, nev, QUDA_DOUBLE_PRECISION, and tol.
Referenced by quda::MG::verify().

◆ asin() [1/2]
|
inline |
Definition at line 55 of file complex_quda.h.
Referenced by acos().

◆ asin() [2/2]
|
inline |
Definition at line 1085 of file complex_quda.h.
References asinh(), fused_exterior_ndeg_tm_dslash_cuda_gen::i, and z.
Referenced by asin().
◆ asinh()
|
inline |

◆ assertAllMemFree()
| void quda::assertAllMemFree | ( | ) |
Definition at line 379 of file malloc.cpp.
References alloc, DEVICE, HOST, MAPPED, PINNED, print_alloc(), print_alloc_header(), printfQuda, and warningQuda.
Referenced by endQuda().
◆ asymCloverDslashCuda()
| void quda::asymCloverDslashCuda | ( | cudaColorSpinorField * | out, |
| const cudaGaugeField & | gauge, | ||
| const FullClover & | cloverInv, | ||
| const cudaColorSpinorField * | in, | ||
| const int | oddBit, | ||
| const int | daggerBit, | ||
| const cudaColorSpinorField * | x, | ||
| const double & | k, | ||
| const int * | commDim, | ||
| TimeProfile & | profile | ||
| ) |
Definition at line 156 of file dslash_clover_asym.cu.
References a, dslash_cuda_gen::clover, deg_tm_dslash_cuda_gen::dagger, deg_tm_dslash_cuda_gen::dslash, errorQuda, in, out, parity, QUDA_DOUBLE_PRECISION, QUDA_HALF_PRECISION, QUDA_SINGLE_PRECISION, and x.
Referenced by quda::DiracClover::DslashXpay().

◆ atan() [1/2]
|
inline |

◆ atan() [2/2]
|
inline |
Definition at line 1092 of file complex_quda.h.
References atanh(), fused_exterior_ndeg_tm_dslash_cuda_gen::i, and z.
Referenced by atan().


◆ atan2()
|
inline |
Definition at line 65 of file complex_quda.h.
Referenced by arg(), quda::Trig< isHalf, T >::Atan2(), atanh(), new_save_half(), and polarSu3().
◆ atanh() [1/2]
|
inline |

◆ atanh() [2/2]
◆ ax()
| void quda::ax | ( | const double & | a, |
| GaugeField & | u | ||
| ) |
Scale the gauge field by the scalar a.
- Parameters
-
[in] a scalar multiplier [in] u The gauge field we want to multiply
Definition at line 322 of file gauge_field.cpp.
References a, quda::blas::ax(), b, colorSpinorParam(), and quda::ColorSpinorField::Create().
Referenced by computeHISQForceQuda(), dslashReference_5th(), dslashReference_5th_inv(), and quda::MG::generateNullVectors().
◆ axpy()
|
inline |
Definition at line 76 of file clover_deriv_quda.cu.
References a, deg_tm_dslash_cuda_gen::block(), blockDim, for(), fused_exterior_ndeg_tm_dslash_cuda_gen::i, x, and y.
Referenced by dslashReference_5th_inv(), quda::RitzMat::operator()(), quda::Lanczos::operator()(), quda::PreconCG::operator()(), and quda::SD::operator()().
◆ backSubs()
| void quda::backSubs | ( | const Complex * | alpha, |
| Complex **const | beta, | ||
| const double * | gamma, | ||
| Complex * | delta, | ||
| int | n | ||
| ) |
Definition at line 131 of file inv_gcr_quda.cpp.
References delta, gamma(), and n.
Referenced by updateSolution().


◆ BlockOrthogonalize()
| void quda::BlockOrthogonalize | ( | ColorSpinorField & | V, |
| int | Nvec, | ||
| const int * | geo_bs, | ||
| const int * | fine_to_coarse, | ||
| int | spin_bs | ||
| ) |
Block orthogonnalize the matrix field, where the blocks are defined by lookup tables that map the fine grid points to the coarse grid points, and similarly for the spin degrees of freedom.
- Parameters
-
[in,out] V Matrix field to be orthgonalized [in] Nvec Vector length [in] geo_bs Geometric block size [in] fine_to_coarse Fine-to-coarse lookup table (linear indices) [in] spin_bs Spin block size
Definition at line 664 of file transfer_util.cu.
References errorQuda, QUDA_DOUBLE_PRECISION, QUDA_SINGLE_PRECISION, and V.
Referenced by quda::Transfer::Transfer().

◆ broadcastTuneCache()
|
static |
Distribute the tunecache from node 0 to all other nodes.
Definition at line 270 of file tune.cpp.
References comm_broadcast(), comm_rank(), deserializeTuneCache(), serializeTuneCache(), and size.
Referenced by loadTuneCache(), and tuneLaunch().
◆ calculateY()
| void quda::calculateY | ( | coarseGauge & | Y, |
| coarseGauge & | X, | ||
| coarseGauge & | Xinv, | ||
| Ftmp & | UV, | ||
| F & | AV, | ||
| F & | V, | ||
| fineGauge & | G, | ||
| fineClover & | C, | ||
| fineClover & | Cinv, | ||
| GaugeField & | Y_, | ||
| GaugeField & | X_, | ||
| GaugeField & | Xinv_, | ||
| GaugeField & | Yhat_, | ||
| ColorSpinorField & | av, | ||
| const ColorSpinorField & | v, | ||
| double | kappa, | ||
| double | mu, | ||
| double | mu_factor, | ||
| QudaDiracType | dirac, | ||
| QudaMatPCType | matpc | ||
| ) |
Calculate the coarse-link field, include the clover field, and its inverse, and finally also compute the preconditioned coarse link field.
- Parameters
-
Y[out] Coarse link field accessor X[out] Coarse clover field accessor Xinv[out] Coarse clover inverse field accessor UV[out] Temporary accessor used to store fine link field * null space vectors AV[out] Temporary accessor use to store fine clover inverse * null space vectors (only applicable when fine-grid operator is the preconditioned clover operator else in general this just aliases V V[in] Packed null-space vector accessor G[in] Fine grid link / gauge field accessor C[in] Fine grid clover field accessor Cinv[in] Fine grid clover inverse field accessor Y_[out] Coarse link field X_[out] Coarse clover field Xinv_[out] Coarse clover field Yhat_[out] Preconditioned coarse link field v[in] Packed null-space vectors kappa[in] Kappa parameter mu[in] Twisted-mass parameter matpc[in] The type of preconditioning of the source fine-grid operator
Definition at line 1487 of file coarse_op.cuh.
References quda::CalculateYhat< Float, n, Arg >::apply(), arg(), quda::cublas::BatchInvertMatrix(), bidirectional_debug, quda::LatticeField::bufferIndex, checkCudaError, checkLocation, comm_dim(), comm_dim_partitioned(), COMPUTE_AV, COMPUTE_COARSE_CLOVER, COMPUTE_COARSE_LOCAL, COMPUTE_DIAGONAL, COMPUTE_REVERSE_Y, COMPUTE_TMAV, COMPUTE_TMCAV, COMPUTE_TMDIAGONAL, COMPUTE_UV, COMPUTE_VUV, quda::GaugeField::copy(), d, dirac, errorQuda, quda::GaugeField::exchangeGhost(), quda::ColorSpinorField::exchangeGhost(), quda::blas::flops, quda::cudaGaugeField::Gauge_p(), quda::cpuGaugeField::Gauge_p(), quda::ColorSpinorField::Ghost(), fused_exterior_ndeg_tm_dslash_cuda_gen::i, quda::GaugeField::injectGhost(), kappa, quda::LatticeField::Location(), matpc(), mu, mu_factor, n, quda::GaugeField::Ncolor(), quda::GaugeField::Order(), param, quda::LatticeField::Precision(), printfQuda, QUDA_BACKWARDS, QUDA_CLOVER_DIRAC, QUDA_CLOVERPC_DIRAC, QUDA_COARSE_DIRAC, QUDA_COARSEPC_DIRAC, QUDA_CPU_FIELD_LOCATION, QUDA_CUDA_FIELD_LOCATION, QUDA_FLOAT2_GAUGE_ORDER, QUDA_FORWARDS, QUDA_INVALID_PARITY, QUDA_LINK_BACKWARDS, QUDA_LINK_BIDIRECTIONAL, QUDA_LINK_FORWARDS, QUDA_MATPC_EVEN_EVEN, QUDA_MATPC_EVEN_EVEN_ASYMMETRIC, QUDA_MATPC_ODD_ODD, QUDA_MATPC_ODD_ODD_ASYMMETRIC, QUDA_MAX_DIM, QUDA_MILC_GAUGE_ORDER, QUDA_QDP_GAUGE_ORDER, QUDA_TWISTED_CLOVER_DIRAC, QUDA_TWISTED_CLOVERPC_DIRAC, QUDA_TWISTED_MASS_DIRAC, QUDA_TWISTED_MASSPC_DIRAC, V, quda::LatticeField::Volume(), quda::ColorSpinorField::X(), X, quda::LatticeField::X(), X_h, Xinv_h, and y.
Referenced by CoarseOp().
◆ CalculateYhatCPU()
| void quda::CalculateYhatCPU | ( | Arg & | arg | ) |
Definition at line 1390 of file coarse_op.cuh.
References arg(), d, fused_exterior_ndeg_tm_dslash_cuda_gen::i, and parity.

◆ CalculateYhatGPU()
| __global__ void quda::CalculateYhatGPU | ( | Arg | arg | ) |
Definition at line 1402 of file coarse_op.cuh.
References arg(), blockDim, d, fused_exterior_ndeg_tm_dslash_cuda_gen::i, n, and parity.

◆ canReuseResidentGauge()
| bool quda::canReuseResidentGauge | ( | QudaInvertParam * | inv_param | ) |
Check that the resident gauge field is compatible with the requested inv_param
- Parameters
-
inv_param Contains all metadata regarding host and device storage
Definition at line 1997 of file interface_quda.cpp.
References QudaGaugeParam_s::cuda_prec, gaugePrecise, param, and quda::LatticeField::Precision().

◆ checkMomOrder()
| void quda::checkMomOrder | ( | const GaugeField & | u | ) |
Definition at line 19 of file copy_gauge.cu.
References errorQuda, quda::GaugeField::Order(), QUDA_FLOAT2_GAUGE_ORDER, QUDA_MILC_GAUGE_ORDER, QUDA_MILC_SITE_GAUGE_ORDER, QUDA_RECONSTRUCT_10, QUDA_RECONSTRUCT_NO, QUDA_TIFR_GAUGE_ORDER, QUDA_TIFR_PADDED_GAUGE_ORDER, and quda::GaugeField::Reconstruct().
Referenced by copyGauge().

◆ checkNan()
| void quda::checkNan | ( | Arg | arg | ) |
Check whether the field contains Nans
Definition at line 62 of file copy_gauge_helper.cuh.
References arg(), d, errorQuda, fused_exterior_ndeg_tm_dslash_cuda_gen::i, length, quda::gauge::Ncolor(), parity, and x.

◆ Checksum()
| uint64_t quda::Checksum | ( | const GaugeField & | u, |
| bool | mini = false |
||
| ) |
Compute XOR-based checksum of this gauge field: each gauge field entry is converted to type uint64_t, and compute the cummulative XOR of these values.
- Parameters
-
[in] mini Whether to compute a mini checksum or global checksum. A mini checksum only computes over a subset of the lattice sites and is to be used for online comparisons, e.g., checking a field has changed with a global update algorithm.
- Returns
- checksum value
Definition at line 34 of file checksum.cu.
References arg(), ChecksumCPU(), errorQuda, quda::GaugeField::Order(), QUDA_BQCD_GAUGE_ORDER, QUDA_MILC_GAUGE_ORDER, QUDA_QDP_GAUGE_ORDER, QUDA_QDPJIT_GAUGE_ORDER, QUDA_TIFR_GAUGE_ORDER, and QUDA_TIFR_PADDED_GAUGE_ORDER.
Referenced by quda::GaugeField::checksum().


◆ ChecksumCPU()
| uint64_t quda::ChecksumCPU | ( | const Arg & | arg | ) |
Definition at line 23 of file checksum.cu.
References arg(), d, parity, and siteChecksum().
Referenced by Checksum().


◆ checkUnitary()
| __host__ __device__ int quda::checkUnitary | ( | Matrix< Float2, 3 > & | inv, |
| Matrix< Float2, 3 > | in, | ||
| const Float | tol | ||
| ) |
Check the unitarity of the input matrix to a given tolerance.
- Parameters
-
inv The inverse of the input matrix in The input matrix to which we're reporting its unitarity tol Tolerance to which this check is applied
Definition at line 24 of file su3_project.cuh.
References computeMatrixInverse(), fabs(), fused_exterior_ndeg_tm_dslash_cuda_gen::i, in, tol, x, and y.
Referenced by polarSu3().


◆ checkUnitaryPrint()
| __host__ __device__ int quda::checkUnitaryPrint | ( | Matrix< Float2, 3 > & | inv, |
| Matrix< Float2, 3 > | in | ||
| ) |
Check the unitarity of the input matrix to a given tolerance (1e-14) and print out deviation for each component (used for debugging only).
- Parameters
-
inv The inverse of the input matrix in The input matrix to which we're reporting its unitarity
Definition at line 47 of file su3_project.cuh.
References computeMatrixInverse(), e, fabs(), fused_exterior_ndeg_tm_dslash_cuda_gen::i, in, printf(), x, and y.
◆ cloverApply()

◆ cloverCPU()
| void quda::cloverCPU | ( | Arg & | arg | ) |
Definition at line 505 of file dslash_quda.cu.
References arg(), for(), and parity.
◆ cloverDerivative()
| void quda::cloverDerivative | ( | cudaGaugeField & | force, |
| cudaGaugeField & | gauge, | ||
| cudaGaugeField & | oprod, | ||
| double | coeff, | ||
| QudaParity | parity | ||
| ) |
Compute the derivative of the clover matrix in the direction mu,nu and compute the resulting force given the outer-product field.
- Parameters
-
force The computed force field (read/write update) gauge The input gauge field oprod The input outer-product field (tensor matrix field) coeff Multiplicative coefficient (e.g., clover coefficient) parity The field parity we are working on
Definition at line 519 of file clover_deriv_quda.cu.
References dw_dslash_4D_cuda_gen::coeff(), d, errorQuda, quda::GaugeField::Geometry(), parity, quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, QUDA_EVEN_PARITY, QUDA_SINGLE_PRECISION, QUDA_TENSOR_GEOMETRY, QUDA_VECTOR_GEOMETRY, and quda::LatticeField::X().
Referenced by computeCloverForceQuda().

◆ cloverDslashCuda()
| void quda::cloverDslashCuda | ( | cudaColorSpinorField * | out, |
| const cudaGaugeField & | gauge, | ||
| const FullClover & | cloverInv, | ||
| const cudaColorSpinorField * | in, | ||
| const int | oddBit, | ||
| const int | daggerBit, | ||
| const cudaColorSpinorField * | x, | ||
| const double & | k, | ||
| const int * | commDim, | ||
| TimeProfile & | profile | ||
| ) |
Definition at line 175 of file dslash_clover.cu.
References a, deg_tm_dslash_cuda_gen::dagger, deg_tm_dslash_cuda_gen::dslash, errorQuda, in, out, parity, QUDA_DOUBLE_PRECISION, QUDA_HALF_PRECISION, QUDA_SINGLE_PRECISION, and x.
Referenced by quda::DiracCloverPC::Dslash(), and quda::DiracCloverPC::DslashXpay().

◆ cloverGPU()
| __global__ void quda::cloverGPU | ( | Arg | arg | ) |
◆ cloverInvert()
| void quda::cloverInvert | ( | CloverField & | clover, |
| bool | computeTraceLog, | ||
| QudaFieldLocation | location | ||
| ) |
This function compute the Cholesky decomposition of each clover matrix and stores the clover inverse field.
- Parameters
-
clover The clover field (contains both the field itself and its inverse) computeTraceLog Whether to compute the trace logarithm of the clover term location The location of the field
Definition at line 183 of file clover_invert.cu.
References dslash_cuda_gen::clover, errorQuda, QUDA_DOUBLE_PRECISION, QUDA_HALF_PRECISION, and QUDA_SINGLE_PRECISION.
Referenced by loadCloverQuda().
◆ cloverRho()
| void quda::cloverRho | ( | CloverField & | clover, |
| double | rho | ||
| ) |
This function adds a real scalar onto the clover diagonal (only to the direct field not the inverse)
- Parameters
-
clover The clover field rho Real scalar to be added on
◆ CoarseCoarseOp()
| void quda::CoarseCoarseOp | ( | GaugeField & | Y, |
| GaugeField & | X, | ||
| GaugeField & | Xinv, | ||
| GaugeField & | Yhat, | ||
| const Transfer & | T, | ||
| const GaugeField & | gauge, | ||
| const GaugeField & | clover, | ||
| const GaugeField & | cloverInv, | ||
| double | kappa, | ||
| double | mu, | ||
| double | mu_factor, | ||
| QudaDiracType | dirac, | ||
| QudaMatPCType | matpc | ||
| ) |
Coarse operator construction from an intermediate-grid operator (Coarse)
- Parameters
-
Y[out] Coarse link field X[out] Coarse clover field Xinv[out] Coarse clover inverse field Y[out] Preconditioned coarse link field T[in] Transfer operator that defines the new coarse space gauge[in] Link field from fine grid clover[in] Clover field on fine grid cloverInv[in] Clover inverse field on fine grid kappa[in] Kappa parameter mu[in] Mu parameter (set to non-zero for twisted-mass/twisted-clover) mu_factor[in] Multiplicative factor for the mu parameter matpc[in] The type of even-odd preconditioned fine-grid operator we are constructing the coarse grid operator from. If matpc==QUDA_MATPC_INVALID then we assume the operator is not even-odd preconditioned and we coarsen the full operator.
Definition at line 169 of file coarsecoarse_op.cu.
References checkLocation, dslash_cuda_gen::clover, quda::ColorSpinorParam::create, quda::ColorSpinorField::Create(), dirac, errorQuda, kappa, matpc(), mu, mu_factor, quda::LatticeField::Precision(), QUDA_ZERO_FIELD_CREATE, quda::Transfer::Vectors(), and X.
Referenced by quda::DiracCoarse::createCoarseOp(), and quda::DiracCoarsePC::createCoarseOp().
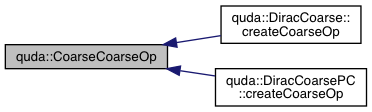
◆ CoarseOp()
| void quda::CoarseOp | ( | GaugeField & | Y, |
| GaugeField & | X, | ||
| GaugeField & | Xinv, | ||
| GaugeField & | Yhat, | ||
| const Transfer & | T, | ||
| const cudaGaugeField & | gauge, | ||
| const cudaCloverField * | clover, | ||
| double | kappa, | ||
| double | mu, | ||
| double | mu_factor, | ||
| QudaDiracType | dirac, | ||
| QudaMatPCType | matpc | ||
| ) |
Coarse operator construction from a fine-grid operator (Wilson / Clover)
- Parameters
-
Y[out] Coarse link field X[out] Coarse clover field Xinv[out] Coarse clover inverse field Yhat[out] Preconditioned coarse link field T[in] Transfer operator that defines the coarse space gauge[in] Gauge field from fine grid clover[in] Clover field on fine grid (optional) kappa[in] Kappa parameter mu[in] Mu parameter (set to non-zero for twisted-mass/twisted-clover) mu_factor[in] Multiplicative factor for the mu parameter matpc[in] The type of even-odd preconditioned fine-grid operator we are constructing the coarse grid operator from. If matpc==QUDA_MATPC_INVALID then we assume the operator is not even-odd preconditioned and we coarsen the full operator.
Definition at line 170 of file coarse_op.cu.
References quda::GaugeField::Anisotropy(), calculateY(), checkLocation, quda::CloverFieldParam::clover, dslash_cuda_gen::clover, quda::CloverFieldParam::cloverInv, quda::GaugeField::copy(), quda::CloverFieldParam::create, quda::ColorSpinorParam::create, quda::ColorSpinorField::Create(), dirac, quda::CloverFieldParam::direct, errorQuda, quda::GaugeField::GaugeFixed(), quda::GaugeField::Geometry(), fused_exterior_ndeg_tm_dslash_cuda_gen::i, quda::CloverFieldParam::inverse, quda::CloverFieldParam::invNorm, kappa, quda::GaugeField::LinkType(), matpc(), mu, mu_factor, quda::LatticeFieldParam::nDim, quda::CloverFieldParam::norm, quda::GaugeFieldParam::order, quda::CloverFieldParam::order, quda::LatticeFieldParam::pad, quda::LatticeFieldParam::precision, quda::LatticeField::Precision(), QUDA_CPU_FIELD_LOCATION, QUDA_CUDA_FIELD_LOCATION, QUDA_FULL_SITE_SUBSET, QUDA_GHOST_EXCHANGE_PAD, QUDA_INVALID_CLOVER_ORDER, QUDA_INVALID_PRECISION, QUDA_MATPC_INVALID, QUDA_NULL_FIELD_CREATE, QUDA_PACKED_CLOVER_ORDER, QUDA_QDP_GAUGE_ORDER, QUDA_RECONSTRUCT_NO, QUDA_TWISTED_MASSPC_DIRAC, QUDA_ZERO_FIELD_CREATE, quda::GaugeFieldParam::reconstruct, quda::GaugeField::Reconstruct(), quda::cudaGaugeField::saveCPUField(), quda::GaugeFieldParam::setPrecision(), quda::LatticeFieldParam::siteSubset, quda::GaugeField::TBoundary(), quda::Transfer::Vectors(), quda::LatticeFieldParam::x, X, and quda::LatticeField::X().
Referenced by quda::DiracWilson::createCoarseOp(), quda::DiracClover::createCoarseOp(), quda::DiracCloverPC::createCoarseOp(), quda::DiracTwistedMass::createCoarseOp(), quda::DiracTwistedMassPC::createCoarseOp(), quda::DiracTwistedClover::createCoarseOp(), and quda::DiracTwistedCloverPC::createCoarseOp().
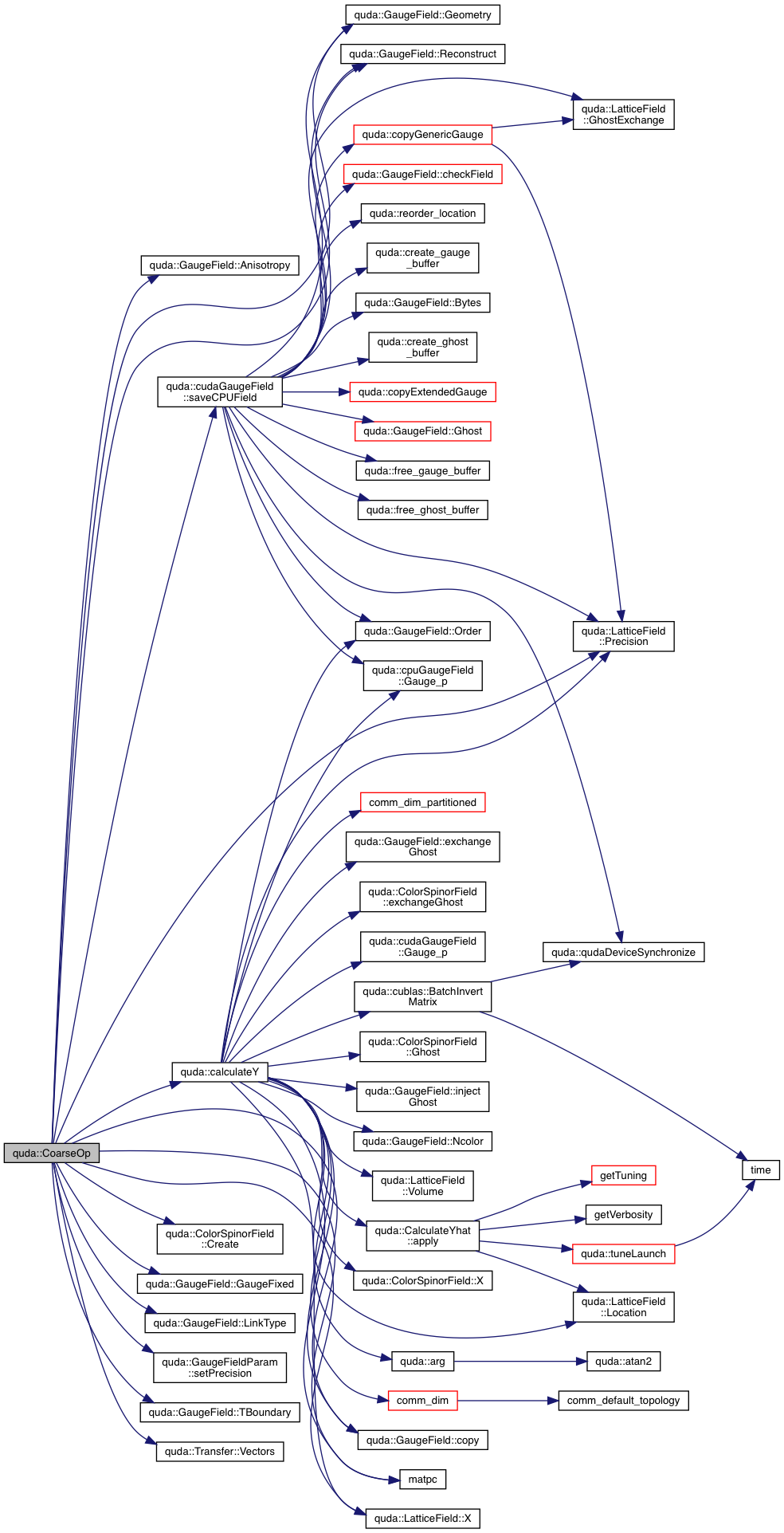
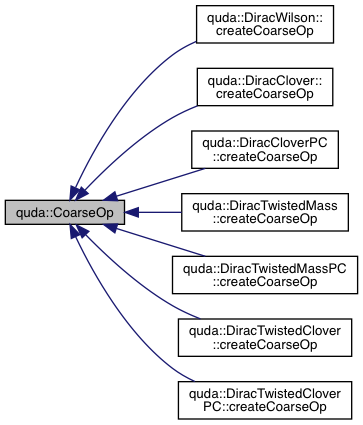
◆ colorSpinorParam() [1/2]
| ColorSpinorParam quda::colorSpinorParam | ( | const GaugeField & | a | ) |
Definition at line 277 of file gauge_field.cpp.
References a, quda::ColorSpinorParam::create, d, errorQuda, quda::ColorSpinorParam::fieldOrder, quda::ColorSpinorParam::gammaBasis, quda::ColorSpinorParam::location, quda::ColorSpinorParam::nColor, quda::LatticeFieldParam::nDim, quda::ColorSpinorParam::nSpin, quda::LatticeFieldParam::pad, quda::LatticeFieldParam::precision, QUDA_COARSE_LINKS, QUDA_DOUBLE_PRECISION, QUDA_EVEN_ODD_SITE_ORDER, QUDA_FLOAT2_FIELD_ORDER, QUDA_FLOAT4_FIELD_ORDER, QUDA_FULL_SITE_SUBSET, QUDA_HALF_PRECISION, QUDA_QDP_GAUGE_ORDER, QUDA_QDPJIT_GAUGE_ORDER, QUDA_REFERENCE_FIELD_CREATE, QUDA_UKQCD_GAMMA_BASIS, quda::ColorSpinorParam::siteOrder, quda::LatticeFieldParam::siteSubset, quda::ColorSpinorParam::v, and quda::LatticeFieldParam::x.
◆ colorSpinorParam() [2/2]
| ColorSpinorParam quda::colorSpinorParam | ( | const CloverField & | a, |
| bool | inverse | ||
| ) |
Definition at line 422 of file clover_field.cpp.
References a, quda::ColorSpinorParam::create, d, errorQuda, quda::ColorSpinorParam::fieldOrder, quda::ColorSpinorParam::gammaBasis, quda::ColorSpinorParam::location, quda::ColorSpinorParam::nColor, quda::LatticeFieldParam::nDim, quda::ColorSpinorParam::nSpin, quda::LatticeFieldParam::pad, quda::LatticeFieldParam::precision, QUDA_DOUBLE_PRECISION, QUDA_EVEN_ODD_SITE_ORDER, QUDA_FLOAT2_FIELD_ORDER, QUDA_FLOAT4_FIELD_ORDER, QUDA_FULL_SITE_SUBSET, QUDA_HALF_PRECISION, QUDA_REFERENCE_FIELD_CREATE, QUDA_UKQCD_GAMMA_BASIS, quda::ColorSpinorParam::siteOrder, quda::LatticeFieldParam::siteSubset, quda::ColorSpinorParam::v, and quda::LatticeFieldParam::x.
Referenced by ax(), norm1(), and norm2().
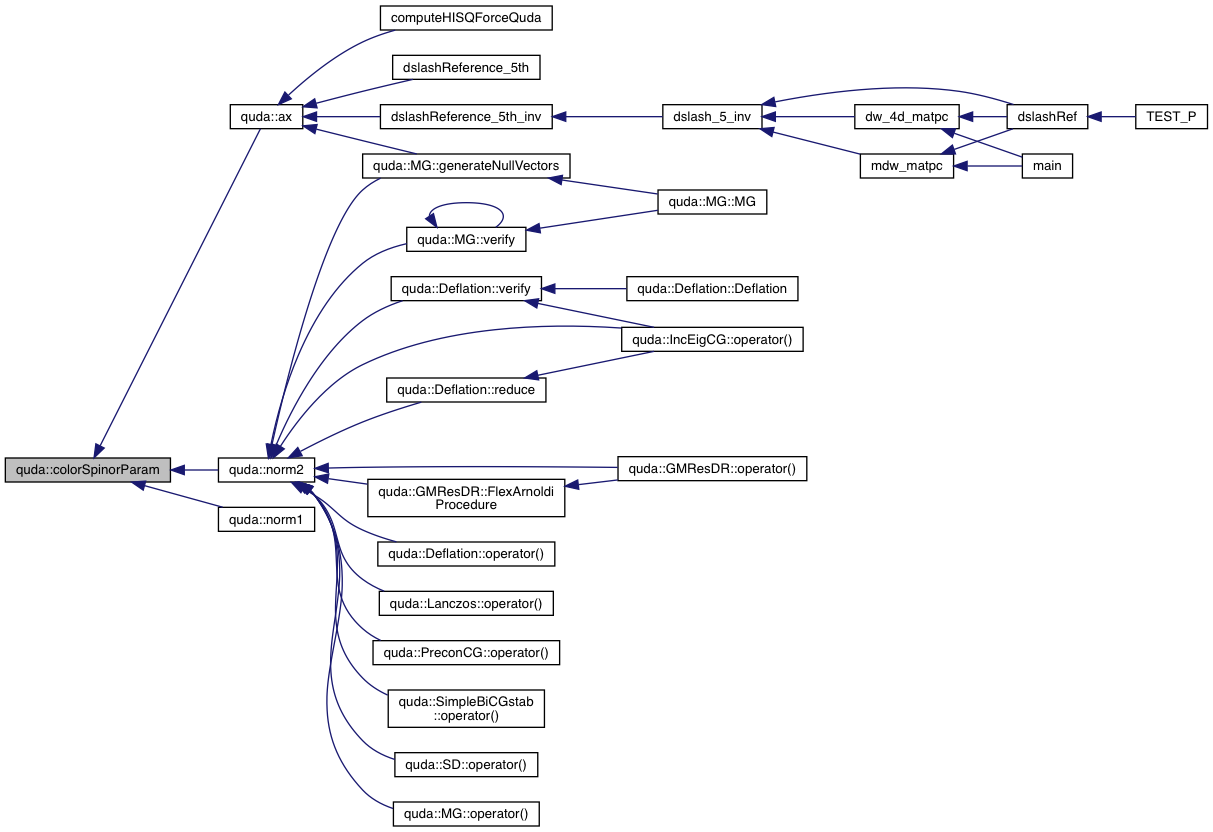
◆ compareSpinor()
Definition at line 147 of file color_spinor_util.cu.
References c, comm_allreduce_int(), comm_size(), e, f, fabs(), fused_exterior_ndeg_tm_dslash_cuda_gen::i, parity, pow(), printfQuda, s, tol, total, and z.
Referenced by genericCompare().


◆ completeKSForce() [1/2]
| void quda::completeKSForce | ( | GaugeField & | mom, |
| const GaugeField & | oprod, | ||
| const GaugeField & | gauge, | ||
| QudaFieldLocation | location, | ||
| long long * | flops = NULL |
||
| ) |
Definition at line 177 of file ks_force_quda.cu.
References errorQuda, quda::blas::flops, QUDA_CUDA_FIELD_LOCATION, QUDA_RECONSTRUCT_10, QUDA_RECONSTRUCT_NO, quda::GaugeField::Reconstruct(), and quda::LatticeField::X().

◆ completeKSForce() [2/2]
| void quda::completeKSForce | ( | Oprod | oprod, |
| Gauge | gauge, | ||
| Mom | mom, | ||
| int | dim[4], | ||
| const GaugeField & | meta, | ||
| QudaFieldLocation | location, | ||
| long long * | flops | ||
| ) |
Definition at line 166 of file ks_force_quda.cu.
References quda::KSForceComplete< Float, Oprod, Gauge, Mom >::apply(), arg(), dim, quda::blas::flops, quda::KSForceComplete< Float, Oprod, Gauge, Mom >::flops(), and qudaDeviceSynchronize().
◆ completeKSForceCore()
| __host__ __device__ void quda::completeKSForceCore | ( | KSForceArg< Oprod, Gauge, Mom > & | arg, |
| int | idx | ||
| ) |
Definition at line 44 of file ks_force_quda.cu.
References arg(), quda::Matrix< T, N >::data, getCoords(), getTrace(), idx, linkIndexShift(), parity, sub(), X, and x.
◆ completeKSForceCPU()
| void quda::completeKSForceCPU | ( | KSForceArg< Oprod, Gauge, Mom > & | arg | ) |

◆ completeKSForceKernel()
| __global__ void quda::completeKSForceKernel | ( | KSForceArg< Oprod, Gauge, Mom > | arg | ) |
Definition at line 104 of file ks_force_quda.cu.
References arg(), blockDim, and idx.

◆ computeAV()

◆ ComputeAVCPU()
| void quda::ComputeAVCPU | ( | Arg & | arg | ) |

◆ ComputeAVGPU()
| __global__ void quda::ComputeAVGPU | ( | Arg | arg | ) |
Definition at line 194 of file coarse_op.cuh.
References arg(), blockDim, and parity.

◆ computeBeta()
| void quda::computeBeta | ( | Complex ** | beta, |
| std::vector< ColorSpinorField *> | Ap, | ||
| int | i, | ||
| int | N, | ||
| int | k | ||
| ) |
Definition at line 50 of file inv_gcr_quda.cpp.
References a, b, quda::blas::cDotProduct(), fused_exterior_ndeg_tm_dslash_cuda_gen::i, and printfQuda.
Referenced by orthoDir().


◆ computeClover()
| void quda::computeClover | ( | CloverField & | clover, |
| const GaugeField & | gauge, | ||
| double | coeff, | ||
| QudaFieldLocation | location | ||
| ) |
Definition at line 204 of file clover_quda.cu.
References dslash_cuda_gen::clover, errorQuda, f, QUDA_DOUBLE_PRECISION, and QUDA_SINGLE_PRECISION.
Referenced by quda::cudaCloverField::compute(), and createCloverQuda().

◆ computeCloverForce()
| void quda::computeCloverForce | ( | GaugeField & | force, |
| const GaugeField & | U, | ||
| std::vector< ColorSpinorField *> & | x, | ||
| std::vector< ColorSpinorField *> & | p, | ||
| std::vector< double > & | coeff | ||
| ) |
Compute the force contribution from the solver solution fields.
Force(x, mu) = U(x, mu) * sum_i=1^nvec ( P_mu^+ x(x+mu) p(x)^ + P_mu^- p(x+mu) x(x)^ )
M = A_even - kappa^2 * Dslash * A_odd^{-1} * Dslash x(even) = M^{-1} b(even) x(odd) = A_odd^{-1} * Dslash * x(even) p(even) = M * x(even) p(odd) = A_odd^{-1} * Dslash^dag * M * x(even).
- Parameters
-
force[out,in] The resulting force field U The input gauge field x Solution field (both parities) p Intermediate vectors (both parities) coeff Multiplicative coefficient (e.g., dt * residue)
Definition at line 468 of file clover_outer_product.cu.
References checkCudaError, dw_dslash_4D_cuda_gen::coeff(), errorQuda, quda::ColorSpinorField::GhostFace(), fused_exterior_ndeg_tm_dslash_cuda_gen::i, quda::GaugeField::Order(), p, parity, quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, QUDA_FLOAT2_GAUGE_ORDER, QUDA_RECONSTRUCT_12, QUDA_RECONSTRUCT_NO, QUDA_SINGLE_PRECISION, quda::GaugeField::Reconstruct(), and x.
Referenced by computeCloverForceQuda().

◆ computeCloverSigmaOprod()
| void quda::computeCloverSigmaOprod | ( | GaugeField & | oprod, |
| std::vector< ColorSpinorField *> & | x, | ||
| std::vector< ColorSpinorField *> & | p, | ||
| std::vector< std::vector< double > > & | coeff | ||
| ) |
Compute the outer product from the solver solution fields arising from the diagonal term of the fermion bilinear in direction mu,nu and sum to outer product field.
- Parameters
-
oprod[out,in] Computed outer product field (tensor matrix field) x[in] Solution field (both parities) p[in] Intermediate vectors (both parities) coeff[in] Multiplicative coefficient (e.g., dt * residiue), one for each parity
Definition at line 178 of file clover_sigma_outer_product.cu.
References checkCudaError, dw_dslash_4D_cuda_gen::coeff(), errorQuda, fused_exterior_ndeg_tm_dslash_cuda_gen::i, quda::GaugeField::Order(), p, quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, QUDA_FLOAT2_GAUGE_ORDER, Spinor< RegType, StoreType, N, write, tex_id >::set(), and x.
Referenced by computeCloverForceQuda().

◆ computeCloverSigmaTrace()
| void quda::computeCloverSigmaTrace | ( | GaugeField & | output, |
| const CloverField & | clover, | ||
| double | coeff | ||
| ) |
Compute the matrix tensor field necessary for the force calculation from the clover trace action. This computes a tensor field [mu,nu].
- Parameters
-
output The computed matrix field (tensor matrix field) clover The input clover field coeff Scalar coefficient multiplying the result (e.g., stepsize)
Definition at line 242 of file clover_trace_quda.cu.
References dslash_cuda_gen::clover, dw_dslash_4D_cuda_gen::coeff(), errorQuda, QUDA_DOUBLE_PRECISION, and QUDA_SINGLE_PRECISION.
Referenced by computeCloverForceQuda().


◆ computeCoarseClover()
| __device__ __host__ void quda::computeCoarseClover | ( | Arg & | arg, |
| int | parity, | ||
| int | x_cb, | ||
| int | ic_c | ||
| ) |
Definition at line 748 of file coarse_op.cuh.
References arg(), conj(), coord, d, for(), getCoords(), fused_exterior_ndeg_tm_dslash_cuda_gen::i, parity, QUDA_MAX_DIM, s, and X.
◆ ComputeCoarseCloverCPU()
| void quda::ComputeCoarseCloverCPU | ( | Arg & | arg | ) |

◆ ComputeCoarseCloverGPU()
| __global__ void quda::ComputeCoarseCloverGPU | ( | Arg | arg | ) |
Definition at line 833 of file coarse_op.cuh.
References arg(), blockDim, and parity.

◆ computeCoarseLocal()
| __device__ __host__ void quda::computeCoarseLocal | ( | Arg & | arg, |
| int | parity, | ||
| int | x_cb | ||
| ) |
Adds the reverse links to the coarse local term, which is just the conjugate of the existing coarse local term but with plus/minus signs for off-diagonal spin components so multiply by the appropriate factor of -kappa.
Definition at line 686 of file coarse_op.cuh.
References arg(), conj(), nColor, parity, and deg_tm_dslash_cuda_gen::sign().
◆ ComputeCoarseLocalCPU()
| void quda::ComputeCoarseLocalCPU | ( | Arg & | arg | ) |

◆ ComputeCoarseLocalGPU()
| __global__ void quda::ComputeCoarseLocalGPU | ( | Arg | arg | ) |
Definition at line 738 of file coarse_op.cuh.
References arg(), blockDim, and parity.

◆ computeCoeffs()
|
static |
Definition at line 79 of file inv_mpcg_quda.cpp.
References applyThirdTerm(), gamma(), fused_exterior_ndeg_tm_dslash_cuda_gen::i, and s.
Referenced by quda::MPCG::operator()().

◆ ComputeEta()
| void quda::ComputeEta | ( | GMResDRArgs & | args | ) |
Definition at line 157 of file inv_gmresdr_quda.cpp.
References errorQuda.
◆ ComputeEta< libtype::eigen_lib >()
| void quda::ComputeEta< libtype::eigen_lib > | ( | GMResDRArgs & | args | ) |
Definition at line 179 of file inv_gmresdr_quda.cpp.
References args.
◆ ComputeEta< libtype::magma_lib >()
| void quda::ComputeEta< libtype::magma_lib > | ( | GMResDRArgs & | args | ) |
Definition at line 159 of file inv_gmresdr_quda.cpp.
References args, errorQuda, magma_Xgels(), memcpy(), and memset().
◆ computeFmunu()
| void quda::computeFmunu | ( | GaugeField & | Fmunu, |
| const GaugeField & | gauge, | ||
| QudaFieldLocation | location | ||
| ) |
Compute the Fmunu tensor
- Parameters
-
Fmunu The Fmunu tensor gauge The gauge field upon which to compute the Fmnu tensor location The location of where to do the computation
Definition at line 283 of file field_strength_tensor.cu.
References errorQuda, quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, and QUDA_SINGLE_PRECISION.
Referenced by createCloverQuda(), and qChargeCuda().

◆ ComputeHarmonicRitz()
| void quda::ComputeHarmonicRitz | ( | GMResDRArgs & | args | ) |
Definition at line 88 of file inv_gmresdr_quda.cpp.
References errorQuda.
◆ ComputeHarmonicRitz< libtype::eigen_lib >()
| void quda::ComputeHarmonicRitz< libtype::eigen_lib > | ( | GMResDRArgs & | args | ) |
Definition at line 127 of file inv_gmresdr_quda.cpp.
References abs(), args, e, memcpy(), quda::blas::norm(), and quda::SortedEvals::SelectSmall().
◆ ComputeHarmonicRitz< libtype::magma_lib >()
| void quda::ComputeHarmonicRitz< libtype::magma_lib > | ( | GMResDRArgs & | args | ) |
Definition at line 90 of file inv_gmresdr_quda.cpp.
References abs(), args, e, errorQuda, magma_Xgeev(), magma_Xgesv(), memcpy(), quda::blas::norm(), and quda::SortedEvals::SelectSmall().
◆ computeKSLongLinkForce() [1/2]
| void quda::computeKSLongLinkForce | ( | Result | res, |
| Oprod | oprod, | ||
| Gauge | gauge, | ||
| int | dim[4], | ||
| const GaugeField & | meta, | ||
| QudaFieldLocation | location | ||
| ) |
Definition at line 378 of file ks_force_quda.cu.
References quda::KSLongLinkForce< Float, Result, Oprod, Gauge >::apply(), arg(), dim, and qudaDeviceSynchronize().

◆ computeKSLongLinkForce() [2/2]
| void quda::computeKSLongLinkForce | ( | GaugeField & | result, |
| const GaugeField & | oprod, | ||
| const GaugeField & | gauge, | ||
| QudaFieldLocation | location | ||
| ) |
Definition at line 387 of file ks_force_quda.cu.
References errorQuda, QUDA_CUDA_FIELD_LOCATION, QUDA_RECONSTRUCT_10, QUDA_RECONSTRUCT_NO, quda::GaugeField::Reconstruct(), and quda::LatticeField::X().

◆ computeKSLongLinkForceCore()
| __host__ __device__ void quda::computeKSLongLinkForceCore | ( | KSLongLinkArg< Result, Oprod, Gauge > & | arg, |
| int | idx | ||
| ) |
Definition at line 247 of file ks_force_quda.cu.
◆ computeKSLongLinkForceCPU()
| void quda::computeKSLongLinkForceCPU | ( | KSLongLinkArg< Result, Oprod, Gauge > & | arg | ) |

◆ computeKSLongLinkForceKernel()
| __global__ void quda::computeKSLongLinkForceKernel | ( | KSLongLinkArg< Result, Oprod, Gauge > | arg | ) |
Definition at line 311 of file ks_force_quda.cu.
References arg(), blockDim, and idx.

◆ computeLinkInverse()
|
inline |
Definition at line 913 of file quda_matrix.h.
References getDeterminant().

◆ computeMatrixInverse()
|
inline |
Definition at line 501 of file quda_matrix.h.
References getDeterminant().
Referenced by checkUnitary(), checkUnitaryPrint(), computeOvrImpSTOUTStep(), and polarSu3().

◆ computeMomAction()
| double quda::computeMomAction | ( | const GaugeField & | mom | ) |
Compute and return global the momentum action 1/2 mom^2.
- Parameters
-
mom Momentum field
- Returns
- Momentum action contribution
Definition at line 113 of file momentum.cu.
References errorQuda, quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, and QUDA_SINGLE_PRECISION.
Referenced by momActionQuda().


◆ computeNeighborSum()
|
inline |
Computes out = sum_mu U_mu(x)in(x+d) + U^(x-d)in(x-d)
- Parameters
-
[out] out The out result field [in] U The gauge field [in] in The input field [in] x_cb The checkerboarded site index [in] parity The site parity
Definition at line 52 of file color_spinor_wuppertal.cu.
References arg(), conj(), coord, getCoords(), in, linkIndexM1(), linkIndexP1(), out, and parity.
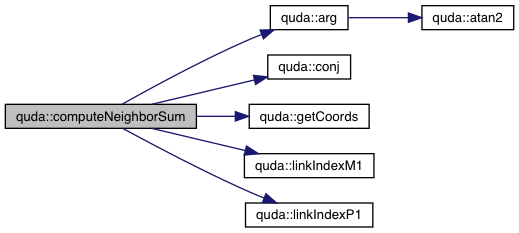
◆ computeOvrImpSTOUTStep()
| __global__ void quda::computeOvrImpSTOUTStep | ( | GaugeOvrImpSTOUTArg< Float, GaugeOr, GaugeDs > | arg | ) |
Definition at line 598 of file gauge_stout.cu.
References arg(), blockDim, computeMatrixInverse(), conj(), ErrorSU3(), exponentiate_iQ(), getCoords(), getTrace(), idx, linkIndexShift(), parity, printf(), setIdentity(), X, and x.
Referenced by quda::GaugeOvrImpSTOUT< Float, GaugeOr, GaugeDs >::apply().
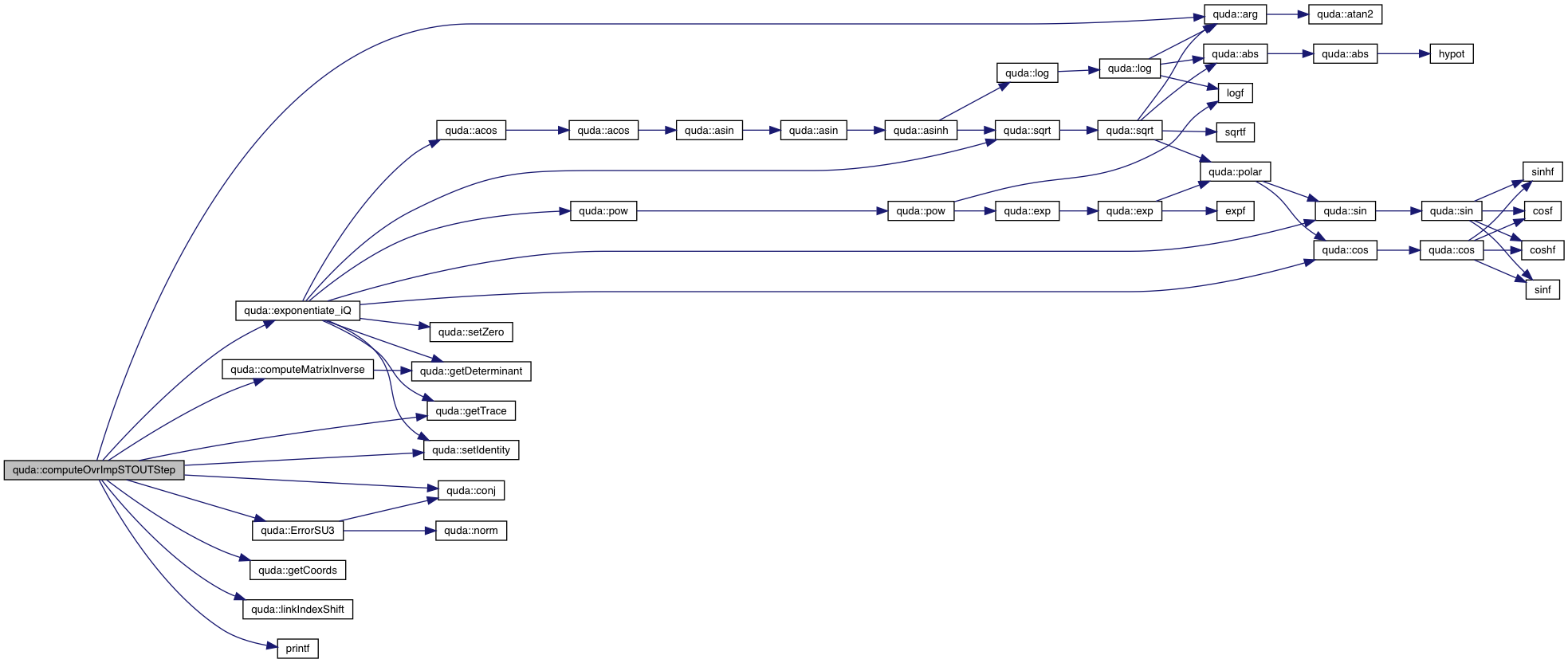

◆ computeQCharge()
| double quda::computeQCharge | ( | GaugeField & | Fmunu, |
| QudaFieldLocation | location | ||
| ) |
Compute the topological charge
- Parameters
-
Fmunu The Fmunu tensor, usually calculated from a smeared configuration location The location of where to do the computation, currently supports only the GPU
Definition at line 143 of file qcharge_quda.cu.
References errorQuda, quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, and QUDA_SINGLE_PRECISION.
Referenced by qChargeCuda().

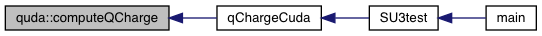
◆ ComputeRitz()
| void quda::ComputeRitz | ( | EigCGArgs & | args | ) |
Definition at line 133 of file inv_eigcg_quda.cpp.
References errorQuda.
◆ ComputeRitz< libtype::eigen_lib >()
| void quda::ComputeRitz< libtype::eigen_lib > | ( | EigCGArgs & | args | ) |
Definition at line 136 of file inv_eigcg_quda.cpp.
References args.
◆ ComputeRitz< libtype::magma_lib >()
| void quda::ComputeRitz< libtype::magma_lib > | ( | EigCGArgs & | args | ) |
Definition at line 164 of file inv_eigcg_quda.cpp.
References args, errorQuda, magma_Xheev(), and memcpy().

◆ computeStaggeredOprod() [1/2]
| void quda::computeStaggeredOprod | ( | GaugeField * | out[], |
| ColorSpinorField & | in, | ||
| const double | coeff[], | ||
| int | nFace | ||
| ) |
Compute the outer-product field between the staggered quark field's one and (for HISQ and ASQTAD) three hop sites. E.g.,.
out[0][d](x) = (in(x+1_d) x conj(in(x))) out[1][d](x) = (in(x+3_d) x conj(in(x)))
where 1_d and 3_d represent a relative shift of magnitude 1 and 3 in dimension d, respectively
Note out[1] is only computed if nFace=3
- Parameters
-
[out] out Array of nFace outer-product matrix fields [in] in Input quark field [in] coeff Coefficient [in] nFace Number of faces (1 or 3)
Definition at line 451 of file staggered_oprod.cu.
References dw_dslash_4D_cuda_gen::coeff(), errorQuda, quda::ColorSpinorField::Even(), in, quda::ColorSpinorField::Odd(), and out.
Referenced by computeHISQForceQuda(), and computeStaggeredForceQuda().
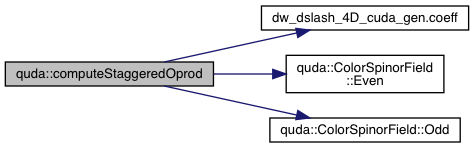

◆ computeStaggeredOprod() [2/2]
| void quda::computeStaggeredOprod | ( | GaugeField & | outA, |
| GaugeField & | outB, | ||
| ColorSpinorField & | inEven, | ||
| ColorSpinorField & | inOdd, | ||
| const unsigned int | parity, | ||
| const double | coeff[2], | ||
| int | nFace | ||
| ) |
Definition at line 408 of file staggered_oprod.cu.
References quda::cudaColorSpinorField::allocateGhostBuffer(), dw_dslash_4D_cuda_gen::coeff(), errorQuda, quda::GaugeField::Order(), parity, quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, QUDA_FLOAT2_GAUGE_ORDER, and QUDA_SINGLE_PRECISION.
◆ computeStapleRectangle()
| __host__ __device__ void quda::computeStapleRectangle | ( | GaugeOvrImpSTOUTArg< Float, GaugeOr, GaugeDs > & | arg, |
| int | idx, | ||
| int | parity, | ||
| int | dir, | ||
| Matrix< Float2, 3 > & | staple, | ||
| Matrix< Float2, 3 > & | rectangle | ||
| ) |
Definition at line 362 of file gauge_stout.cu.
References arg(), conj(), getCoords(), idx, linkIndexShift(), mu, parity, setZero(), X, and x.
◆ computeTMAV()

◆ ComputeTMAVCPU()
| void quda::ComputeTMAVCPU | ( | Arg & | arg | ) |

◆ ComputeTMAVGPU()
| __global__ void quda::ComputeTMAVGPU | ( | Arg | arg | ) |
Definition at line 239 of file coarse_op.cuh.
References arg(), blockDim, and parity.

◆ computeTMCAV()

◆ ComputeTMCAVCPU()
| void quda::ComputeTMCAVCPU | ( | Arg & | arg | ) |

◆ ComputeTMCAVGPU()
| __global__ void quda::ComputeTMCAVGPU | ( | Arg | arg | ) |
Definition at line 474 of file coarse_op.cuh.
References arg(), blockDim, and parity.

◆ computeUV()
|
inline |
Calculates the matrix UV^{s,c'}_mu(x) = U^{c}_mu(x) * V^{s,c}_mu(x+mu) Where: mu = dir, s = fine spin, c' = coarse color, c = fine color
Definition at line 62 of file coarse_op.cuh.
References arg(), c, coord, dim, getCoords(), linkIndexP1(), parity, QUDA_FORWARDS, and s.
◆ ComputeUVCPU()
| void quda::ComputeUVCPU | ( | Arg & | arg | ) |

◆ ComputeUVGPU()
| __global__ void quda::ComputeUVGPU | ( | Arg | arg | ) |
Definition at line 142 of file coarse_op.cuh.
References arg(), blockDim, and parity.

◆ computeVUV()
| __device__ __host__ void quda::computeVUV | ( | Arg & | arg, |
| int | parity, | ||
| int | x_cb, | ||
| int | c_row | ||
| ) |
Definition at line 570 of file coarse_op.cuh.
References arg(), coord, d, dim, getCoords(), parity, QUDA_BACKWARDS, and QUDA_MAX_DIM.

◆ ComputeVUVCPU()
| void quda::ComputeVUVCPU | ( | Arg | arg | ) |

◆ ComputeVUVGPU()
| __global__ void quda::ComputeVUVGPU | ( | Arg | arg | ) |
Definition at line 624 of file coarse_op.cuh.
References arg(), blockDim, and parity.

◆ computeWupperalStep()

◆ computeYhat()
| __device__ __host__ void quda::computeYhat | ( | Arg & | arg, |
| int | d, | ||
| int | x_cb, | ||
| int | parity, | ||
| int | i | ||
| ) |
Definition at line 1349 of file coarse_op.cuh.
References arg(), conj(), coord, d, getCoords(), fused_exterior_ndeg_tm_dslash_cuda_gen::i, linkIndexM1(), n, and parity.
◆ computeYreverse()
| __device__ __host__ void quda::computeYreverse | ( | Arg & | arg, |
| int | parity, | ||
| int | x_cb | ||
| ) |
Compute the forward links from backwards links by flipping the sign of the spin projector
Definition at line 639 of file coarse_op.cuh.
References arg(), d, nColor, parity, and deg_tm_dslash_cuda_gen::sign().

◆ ComputeYReverseCPU()
| void quda::ComputeYReverseCPU | ( | Arg & | arg | ) |

◆ ComputeYReverseGPU()
| __global__ void quda::ComputeYReverseGPU | ( | Arg | arg | ) |
Definition at line 670 of file coarse_op.cuh.
References arg(), blockDim, and parity.

◆ conj() [1/3]
|
inline |
Definition at line 115 of file complex_quda.h.
References x.
Referenced by applyLaplace(), quda::blas::cDotProduct(), computeCoarseClover(), computeCoarseLocal(), computeNeighborSum(), computeOvrImpSTOUTStep(), computeStapleRectangle(), computeYhat(), conj(), ErrorSU3(), quda::GMResDR::FlexArnoldiProcedure(), quda::gauge::Reconstruct< 13, Float >::getPhase(), quda::gauge::Reconstruct< 9, Float >::getPhase(), quda::blas::hDotProduct(), quda::blas::hDotProduct_Anorm(), quda::Deflation::increment(), isUnitary(), makeAntiHerm(), multiplyVUV(), quda::BiCGstab::operator()(), quda::SimpleBiCGstab::operator()(), quda::MPBiCGstab::operator()(), outerProd(), polarSu3(), solve(), quda::CG::solve(), quda::gauge::Reconstruct< 12, Float >::Unpack(), quda::gauge::Reconstruct< 13, Float >::Unpack(), and quda::gauge::Reconstruct< 8, Float >::Unpack().
◆ conj() [2/3]
|
inline |
◆ conj() [3/3]
|
inline |
Definition at line 486 of file quda_matrix.h.
References conj(), and fused_exterior_ndeg_tm_dslash_cuda_gen::i.

◆ constant()
Set all space-time real elements at spin s and color c of the field equal to k
Definition at line 37 of file color_spinor_util.cu.
References c, parity, s, and t.
Referenced by genericSource().

◆ contractCuda() [1/2]
| void quda::contractCuda | ( | const cudaColorSpinorField & | x, |
| const cudaColorSpinorField & | y, | ||
| void * | result, | ||
| const QudaContractType | contract_type, | ||
| const QudaParity | parity, | ||
| TimeProfile & | profile | ||
| ) |
Contracts the x and y spinors (x is daggered) and stores the result in the array result. One must specify the contract type (time-sliced or volumed contract, and whether we should include a gamma5 in the middle), as well as the time-slice (see overloaded version of the same function) in case we don't want a volume contraction. The function works only with parity spinors, and the parity must be specified.
Definition at line 202 of file contract.cu.
References checkCudaError, contract(), errorQuda, Nstream, parity, QUDA_CONTRACT_TSLICE, QUDA_CONTRACT_TSLICE_MINUS, QUDA_CONTRACT_TSLICE_PLUS, QUDA_DOUBLE_PRECISION, QUDA_HALF_PRECISION, QUDA_PROFILE_COMPUTE, QUDA_PROFILE_EPILOGUE, QUDA_PROFILE_INIT, QUDA_PROFILE_TOTAL, QUDA_SINGLE_PRECISION, qudaStreamSynchronize(), streams, x, and y.
Referenced by contract().

◆ contractCuda() [2/2]
| void quda::contractCuda | ( | const cudaColorSpinorField & | x, |
| const cudaColorSpinorField & | y, | ||
| void * | result, | ||
| const QudaContractType | contract_type, | ||
| const int | nTSlice, | ||
| const QudaParity | parity, | ||
| TimeProfile & | profile | ||
| ) |
Contracts the x and y spinors (x is daggered) and stores the result in the array result. One must specify the contract type (time-sliced or volumed contract, and whether we should include a gamma5 in the middle), as well as the time-slice in case we don't want a volume contraction. The function works only with parity spinors, and the parity must be specified.
Definition at line 248 of file contract.cu.
References checkCudaError, contract(), errorQuda, Nstream, parity, QUDA_CONTRACT_TSLICE, QUDA_CONTRACT_TSLICE_MINUS, QUDA_CONTRACT_TSLICE_PLUS, QUDA_DOUBLE_PRECISION, QUDA_HALF_PRECISION, QUDA_PROFILE_COMPUTE, QUDA_PROFILE_EPILOGUE, QUDA_PROFILE_INIT, QUDA_PROFILE_TOTAL, QUDA_SINGLE_PRECISION, qudaStreamSynchronize(), streams, x, and y.

◆ copy() [1/9]
|
inline |
Definition at line 114 of file register_traits.h.
Referenced by computeCloverForceQuda(), genericCopyColorSpinor(), quda::colorspinor::FloatNOrder< Float, Ns, Nc, N, huge_alloc >::load(), quda::gauge::FloatNOrder< Float, length, N, reconLenParam, stag_phase, huge_alloc >::load(), quda::colorspinor::FloatNOrder< Float, Ns, Nc, N, huge_alloc >::loadGhost(), quda::gauge::FloatNOrder< Float, length, N, reconLenParam, stag_phase, huge_alloc >::loadGhost(), quda::gauge::FloatNOrder< Float, length, N, reconLenParam, stag_phase, huge_alloc >::loadGhostEx(), new_load_half(), new_save_half(), old_load_half(), old_save_half(), quda::PreconCG::operator()(), qudaMemcpy_(), quda::colorspinor::FloatNOrder< Float, Ns, Nc, N, huge_alloc >::save(), quda::gauge::FloatNOrder< Float, length, N, reconLenParam, stag_phase, huge_alloc >::save(), quda::colorspinor::FloatNOrder< Float, Ns, Nc, N, huge_alloc >::saveGhost(), quda::gauge::FloatNOrder< Float, length, N, reconLenParam, stag_phase, huge_alloc >::saveGhost(), and quda::gauge::FloatNOrder< Float, length, N, reconLenParam, stag_phase, huge_alloc >::saveGhostEx().
◆ copy() [2/9]
|
inline |
Definition at line 116 of file register_traits.h.
◆ copy() [3/9]
|
inline |
Definition at line 124 of file register_traits.h.
◆ copy() [4/9]
|
inline |

◆ copy() [5/9]
|
inline |

◆ copy() [6/9]
|
inline |

◆ copy() [7/9]
|
inline |

◆ copy() [8/9]
|
inline |

◆ copy() [9/9]
|
inline |

◆ copyArrayToLink() [1/2]
Definition at line 951 of file quda_matrix.h.
References array, fused_exterior_ndeg_tm_dslash_cuda_gen::i, x, and y.
◆ copyArrayToLink() [2/2]
|
inline |
Definition at line 964 of file quda_matrix.h.
References array, fused_exterior_ndeg_tm_dslash_cuda_gen::i, x, and y.
◆ copyColorSpinor()
| void quda::copyColorSpinor | ( | Arg & | arg, |
| const Basis & | basis | ||
| ) |

◆ copyColorSpinorKernel()
| __global__ void quda::copyColorSpinorKernel | ( | Arg | arg, |
| Basis | basis | ||
| ) |

◆ copyColumn()
|
inline |
Definition at line 683 of file quda_matrix.h.
References c, and fused_exterior_ndeg_tm_dslash_cuda_gen::i.
Referenced by getRealBidiagMatrix().

◆ copyExtendedColorSpinor() [1/2]
| void quda::copyExtendedColorSpinor | ( | ColorSpinorField & | dst, |
| const ColorSpinorField & | src, | ||
| const int | parity, | ||
| const QudaFieldLocation | location, | ||
| dstFloat * | Dst, | ||
| srcFloat * | Src, | ||
| float * | dstNorm, | ||
| float * | srcNorm | ||
| ) |
Definition at line 368 of file extended_color_spinor_utilities.cu.
References quda::ColorSpinorField::Bytes(), errorQuda, quda::ColorSpinorField::FieldOrder(), quda::ColorSpinorField::Ncolor(), quda::ColorSpinorField::Ndim(), quda::ColorSpinorField::Norm(), quda::ColorSpinorField::NormBytes(), parity, QUDA_EVEN_ODD_SITE_ORDER, QUDA_FULL_SITE_SUBSET, QUDA_LEXICOGRAPHIC_SITE_ORDER, QUDA_ODD_EVEN_SITE_ORDER, QUDA_QDPJIT_FIELD_ORDER, quda::ColorSpinorField::SiteOrder(), quda::ColorSpinorField::SiteSubset(), src, and quda::ColorSpinorField::V().
◆ CopyExtendedColorSpinor()
| void quda::CopyExtendedColorSpinor | ( | ColorSpinorField & | dst, |
| const ColorSpinorField & | src, | ||
| const int | parity, | ||
| const QudaFieldLocation | location, | ||
| dstFloat * | Dst, | ||
| srcFloat * | Src, | ||
| float * | dstNorm = 0, |
||
| float * | srcNorm = 0 |
||
| ) |
Definition at line 436 of file extended_color_spinor_utilities.cu.
References errorQuda, quda::ColorSpinorField::Nspin(), parity, and src.
Referenced by copyExtendedColorSpinor().

◆ copyExtendedColorSpinor() [2/2]
| void quda::copyExtendedColorSpinor | ( | ColorSpinorField & | dst, |
| const ColorSpinorField & | src, | ||
| QudaFieldLocation | location, | ||
| const int | parity, | ||
| void * | Dst, | ||
| void * | Src, | ||
| void * | dstNorm, | ||
| void * | srcNorm | ||
| ) |
Definition at line 462 of file extended_color_spinor_utilities.cu.
References CopyExtendedColorSpinor(), errorQuda, parity, quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, QUDA_HALF_PRECISION, QUDA_SINGLE_PRECISION, and src.
Referenced by quda::XSD::operator()().


◆ copyExtendedGauge()
| void quda::copyExtendedGauge | ( | GaugeField & | out, |
| const GaugeField & | in, | ||
| QudaFieldLocation | location, | ||
| void * | Out = 0, |
||
| void * | In = 0 |
||
| ) |
This function is used for copying the gauge field into an extended gauge field. Defined in copy_extended_gauge.cu.
- Parameters
-
out The extended output field to which we are copying in The input field from which we are copying location The location of where we are doing the copying (CPU or CUDA) Out The output buffer (optional) In The input buffer (optional)
Definition at line 321 of file copy_gauge_extended.cu.
References copyGaugeEx(), d, errorQuda, in, out, QUDA_DOUBLE_PRECISION, and QUDA_SINGLE_PRECISION.
Referenced by computeGaugeFixingOVRQuda(), computeHISQForceQuda(), quda::cudaGaugeField::copy(), quda::cpuGaugeField::copy(), createExtendedGauge(), hisq_force_init(), main(), performWuppertalnStep(), quda::cudaGaugeField::saveCPUField(), and saveGaugeQuda().

◆ copyGauge() [1/5]
| void quda::copyGauge | ( | const InOrder & | inOrder, |
| const GaugeField & | out, | ||
| const GaugeField & | in, | ||
| QudaFieldLocation | location, | ||
| FloatOut * | Out, | ||
| FloatOut ** | outGhost, | ||
| int | type | ||
| ) |
Definition at line 7 of file copy_gauge_inc.cu.
References errorQuda, fused_exterior_ndeg_tm_dslash_cuda_gen::i, in, quda::ColorSpinorField::isNative(), quda::ColorSpinorField::Ndim(), out, QUDA_ASQTAD_FAT_LINKS, QUDA_BQCD_GAUGE_ORDER, QUDA_CPS_WILSON_GAUGE_ORDER, QUDA_MAX_DIM, QUDA_MILC_GAUGE_ORDER, QUDA_MILC_SITE_GAUGE_ORDER, QUDA_QDP_GAUGE_ORDER, QUDA_QDPJIT_GAUGE_ORDER, QUDA_RECONSTRUCT_12, QUDA_RECONSTRUCT_13, QUDA_RECONSTRUCT_8, QUDA_RECONSTRUCT_9, QUDA_RECONSTRUCT_NO, QUDA_TIFR_GAUGE_ORDER, QUDA_TIFR_PADDED_GAUGE_ORDER, quda::LatticeField::SurfaceCB(), and quda::ColorSpinorField::Volume().
◆ copyGauge() [2/5]
| void quda::copyGauge | ( | CopyGaugeArg< OutOrder, InOrder > | arg | ) |
Generic CPU gauge reordering and packing
Definition at line 32 of file copy_gauge_helper.cuh.
References arg(), d, fused_exterior_ndeg_tm_dslash_cuda_gen::i, in, length, quda::gauge::Ncolor(), out, parity, and x.
Referenced by copyGenericGaugeDoubleOut(), copyGenericGaugeHalfOut(), and copyGenericGaugeSingleOut().

◆ copyGauge() [3/5]
| void quda::copyGauge | ( | GaugeField & | out, |
| const GaugeField & | in, | ||
| QudaFieldLocation | location, | ||
| FloatOut * | Out, | ||
| FloatIn * | In, | ||
| FloatOut ** | outGhost, | ||
| FloatIn ** | inGhost, | ||
| int | type | ||
| ) |
Definition at line 140 of file copy_gauge_inc.cu.
References errorQuda, in, quda::ColorSpinorField::isNative(), out, QUDA_ASQTAD_FAT_LINKS, QUDA_BQCD_GAUGE_ORDER, QUDA_CPS_WILSON_GAUGE_ORDER, QUDA_MILC_GAUGE_ORDER, QUDA_MILC_SITE_GAUGE_ORDER, QUDA_QDP_GAUGE_ORDER, QUDA_QDPJIT_GAUGE_ORDER, QUDA_RECONSTRUCT_12, QUDA_RECONSTRUCT_13, QUDA_RECONSTRUCT_8, QUDA_RECONSTRUCT_9, QUDA_RECONSTRUCT_NO, QUDA_TIFR_GAUGE_ORDER, and QUDA_TIFR_PADDED_GAUGE_ORDER.

◆ copyGauge() [4/5]
| void quda::copyGauge | ( | OutOrder && | outOrder, |
| const InOrder & | inOrder, | ||
| int | volume, | ||
| const int * | faceVolumeCB, | ||
| int | nDim, | ||
| int | geometry, | ||
| const GaugeField & | out, | ||
| const GaugeField & | in, | ||
| QudaFieldLocation | location, | ||
| int | type | ||
| ) |
Definition at line 253 of file copy_gauge_helper.cuh.
References quda::CopyGauge< FloatOut, FloatIn, length, OutOrder, InOrder, isGhost >::apply(), arg(), errorQuda, in, out, QUDA_COARSE_GEOMETRY, QUDA_CPU_FIELD_LOCATION, QUDA_CUDA_FIELD_LOCATION, and QUDA_VECTOR_GEOMETRY.
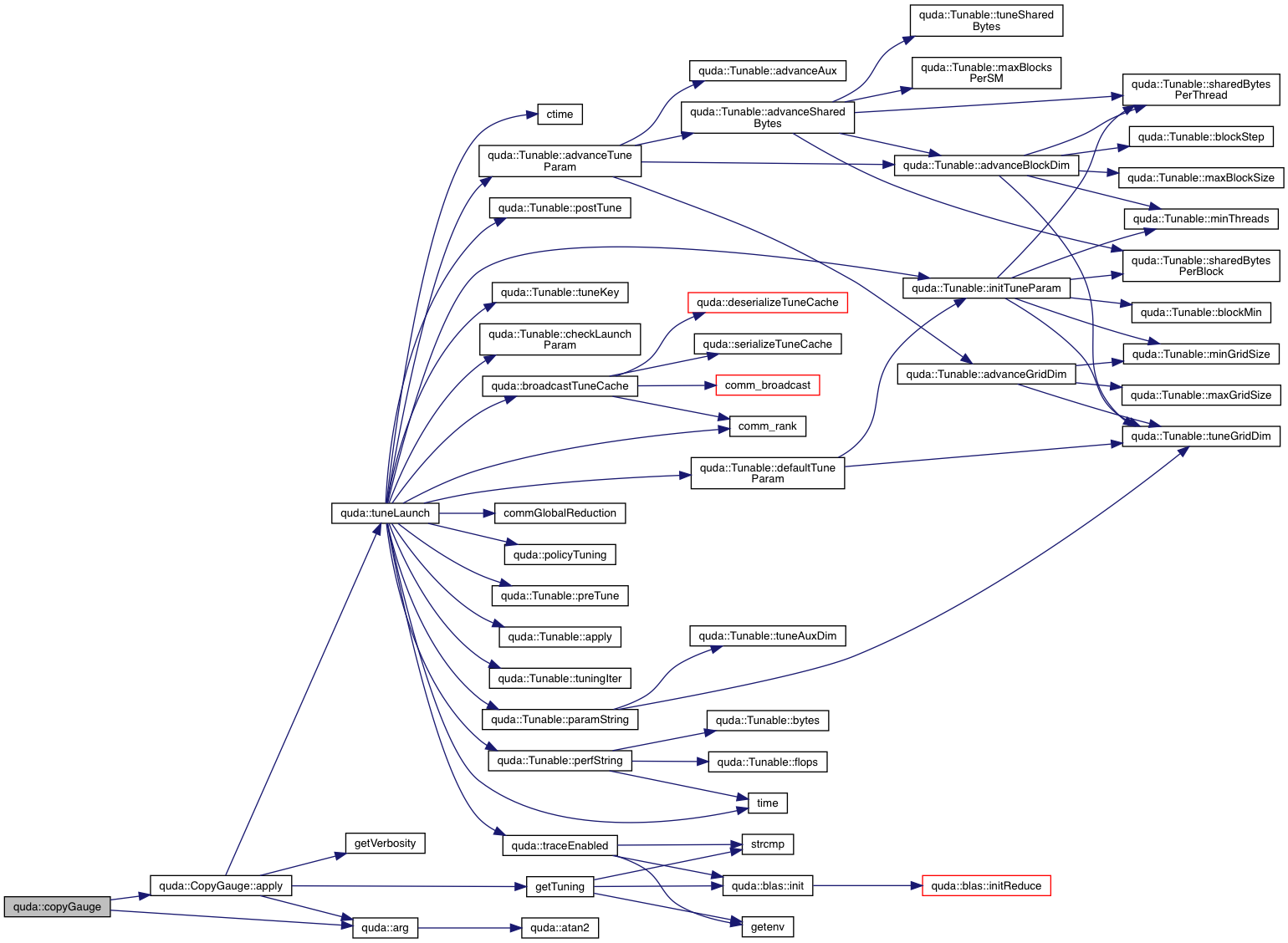
◆ copyGauge() [5/5]
| void quda::copyGauge | ( | GaugeField & | out, |
| const GaugeField & | in, | ||
| QudaFieldLocation | location, | ||
| FloatOut * | Out, | ||
| FloatIn * | In, | ||
| FloatOut ** | outGhost, | ||
| FloatIn ** | inGhost, | ||
| int | type | ||
| ) |
Definition at line 271 of file copy_gauge_inc.cu.
References arg(), checkMomOrder(), d, errorQuda, in, quda::ColorSpinorField::Ncolor(), quda::ColorSpinorField::Ndim(), out, QUDA_ASQTAD_MOM_LINKS, QUDA_FLOAT2_GAUGE_ORDER, QUDA_MAX_DIM, QUDA_MILC_GAUGE_ORDER, QUDA_MILC_SITE_GAUGE_ORDER, QUDA_TIFR_GAUGE_ORDER, QUDA_TIFR_PADDED_GAUGE_ORDER, QUDA_VECTOR_GEOMETRY, quda::LatticeField::SurfaceCB(), and quda::ColorSpinorField::Volume().
◆ copyGaugeEx() [1/6]
| __device__ __host__ void quda::copyGaugeEx | ( | CopyGaugeExArg< OutOrder, InOrder > & | arg, |
| int | X, | ||
| int | parity | ||
| ) |
Copy a regular/extended gauge field into an extended/regular gauge field
Definition at line 48 of file copy_gauge_extended.cu.
References arg(), d, fused_exterior_ndeg_tm_dslash_cuda_gen::i, in, length, out, parity, R, X, x, x0h, za, and zb.
Referenced by copyExtendedGauge().

◆ copyGaugeEx() [2/6]
| void quda::copyGaugeEx | ( | CopyGaugeExArg< OutOrder, InOrder > | arg | ) |
Definition at line 92 of file copy_gauge_extended.cu.
References arg(), parity, and X.

◆ copyGaugeEx() [3/6]
| void quda::copyGaugeEx | ( | OutOrder | outOrder, |
| const InOrder | inOrder, | ||
| const int * | E, | ||
| const int * | X, | ||
| const int * | faceVolumeCB, | ||
| const GaugeField & | meta, | ||
| QudaFieldLocation | location | ||
| ) |
Definition at line 157 of file copy_gauge_extended.cu.
References arg(), checkCudaError, E, quda::GaugeField::Geometry(), quda::LatticeField::Ndim(), QUDA_CUDA_FIELD_LOCATION, and X.
◆ copyGaugeEx() [4/6]
| void quda::copyGaugeEx | ( | const InOrder & | inOrder, |
| const int * | X, | ||
| GaugeField & | out, | ||
| QudaFieldLocation | location, | ||
| FloatOut * | Out | ||
| ) |
Definition at line 168 of file copy_gauge_extended.cu.
References errorQuda, fused_exterior_ndeg_tm_dslash_cuda_gen::i, out, QUDA_ASQTAD_FAT_LINKS, QUDA_MAX_DIM, QUDA_MILC_GAUGE_ORDER, QUDA_QDP_GAUGE_ORDER, QUDA_RECONSTRUCT_12, QUDA_RECONSTRUCT_13, QUDA_RECONSTRUCT_8, QUDA_RECONSTRUCT_9, QUDA_RECONSTRUCT_NO, QUDA_TIFR_GAUGE_ORDER, and X.
◆ copyGaugeEx() [5/6]
| void quda::copyGaugeEx | ( | GaugeField & | out, |
| const GaugeField & | in, | ||
| QudaFieldLocation | location, | ||
| FloatOut * | Out, | ||
| FloatIn * | In | ||
| ) |
Definition at line 239 of file copy_gauge_extended.cu.
References errorQuda, in, out, QUDA_ASQTAD_FAT_LINKS, QUDA_MILC_GAUGE_ORDER, QUDA_QDP_GAUGE_ORDER, QUDA_RECONSTRUCT_12, QUDA_RECONSTRUCT_13, QUDA_RECONSTRUCT_8, QUDA_RECONSTRUCT_9, QUDA_RECONSTRUCT_NO, and QUDA_TIFR_GAUGE_ORDER.
◆ copyGaugeEx() [6/6]
| void quda::copyGaugeEx | ( | GaugeField & | out, |
| const GaugeField & | in, | ||
| QudaFieldLocation | location, | ||
| FloatOut * | Out, | ||
| FloatIn * | In | ||
| ) |
Definition at line 302 of file copy_gauge_extended.cu.
References errorQuda, in, out, and QUDA_ASQTAD_MOM_LINKS.
◆ copyGaugeExKernel()
| __global__ void quda::copyGaugeExKernel | ( | CopyGaugeExArg< OutOrder, InOrder > | arg | ) |

◆ copyGaugeKernel()
| __global__ void quda::copyGaugeKernel | ( | CopyGaugeArg< OutOrder, InOrder > | arg | ) |
Generic CUDA gauge reordering and packing. Adopts a similar form as the CPU version, using the same inlined functions.
Definition at line 96 of file copy_gauge_helper.cuh.
References arg(), blockDim, d, fused_exterior_ndeg_tm_dslash_cuda_gen::i, in, length, quda::gauge::Ncolor(), out, parity, and x.

◆ copyGaugeMG() [1/3]
| void quda::copyGaugeMG | ( | const InOrder & | inOrder, |
| GaugeField & | out, | ||
| const GaugeField & | in, | ||
| QudaFieldLocation | location, | ||
| FloatOut * | Out, | ||
| FloatOut ** | outGhost, | ||
| int | type | ||
| ) |
Definition at line 10 of file copy_gauge_mg.cu.
References errorQuda, fused_exterior_ndeg_tm_dslash_cuda_gen::i, in, quda::ColorSpinorField::isNative(), quda::ColorSpinorField::Ndim(), out, QUDA_MAX_DIM, QUDA_MILC_GAUGE_ORDER, QUDA_QDP_GAUGE_ORDER, QUDA_RECONSTRUCT_NO, quda::LatticeField::SurfaceCB(), and quda::ColorSpinorField::Volume().
Referenced by copyGenericGaugeMG().
◆ copyGaugeMG() [2/3]
| void quda::copyGaugeMG | ( | GaugeField & | out, |
| const GaugeField & | in, | ||
| QudaFieldLocation | location, | ||
| FloatOut * | Out, | ||
| FloatIn * | In, | ||
| FloatOut ** | outGhost, | ||
| FloatIn ** | inGhost, | ||
| int | type | ||
| ) |
Definition at line 67 of file copy_gauge_mg.cu.
References errorQuda, in, quda::ColorSpinorField::isNative(), out, QUDA_MILC_GAUGE_ORDER, QUDA_QDP_GAUGE_ORDER, and QUDA_RECONSTRUCT_NO.

◆ copyGaugeMG() [3/3]
| void quda::copyGaugeMG | ( | GaugeField & | out, |
| const GaugeField & | in, | ||
| QudaFieldLocation | location, | ||
| FloatOut * | Out, | ||
| FloatIn * | In, | ||
| FloatOut ** | outGhost, | ||
| FloatIn ** | inGhost, | ||
| int | type | ||
| ) |
Definition at line 114 of file copy_gauge_mg.cu.
References errorQuda, in, quda::ColorSpinorField::Ncolor(), and out.

◆ copyGenericClover()
| void quda::copyGenericClover | ( | CloverField & | out, |
| const CloverField & | in, | ||
| bool | inverse, | ||
| QudaFieldLocation | location, | ||
| void * | Out = 0, |
||
| void * | In = 0, |
||
| void * | outNorm = 0, |
||
| void * | inNorm = 0 |
||
| ) |
This generic function is used for copying the clover field where in the input and output can be in any order and location.
- Parameters
-
out The output field to which we are copying in The input field from which we are copying inverse Whether we are copying the inverse term or not location The location of where we are doing the copying (CPU or CUDA) Out The output buffer (optional) In The input buffer (optional) outNorm The output norm buffer (optional) inNorm The input norm buffer (optional)
Definition at line 175 of file copy_clover.cu.
References errorQuda, in, out, QUDA_DOUBLE_PRECISION, QUDA_HALF_PRECISION, and QUDA_SINGLE_PRECISION.
Referenced by quda::cudaCloverField::copy(), and quda::cudaCloverField::saveCPUField().
◆ copyGenericColorSpinor() [1/3]
| void quda::copyGenericColorSpinor | ( | ColorSpinorField & | dst, |
| const ColorSpinorField & | src, | ||
| QudaFieldLocation | location, | ||
| dstFloat * | Dst, | ||
| srcFloat * | Src | ||
| ) |
Definition at line 130 of file copy_color_spinor_mg.cuh.
References quda::ColorSpinorField::Bytes(), errorQuda, quda::ColorSpinorField::FieldOrder(), quda::ColorSpinorField::Ndim(), QUDA_EVEN_ODD_SITE_ORDER, QUDA_FULL_SITE_SUBSET, QUDA_LEXICOGRAPHIC_SITE_ORDER, QUDA_ODD_EVEN_SITE_ORDER, QUDA_QDPJIT_FIELD_ORDER, quda::ColorSpinorField::SiteOrder(), quda::ColorSpinorField::SiteSubset(), src, quda::ColorSpinorField::V(), and quda::ColorSpinorField::Volume().
◆ CopyGenericColorSpinor() [1/2]
| void quda::CopyGenericColorSpinor | ( | ColorSpinorField & | dst, |
| const ColorSpinorField & | src, | ||
| QudaFieldLocation | location, | ||
| dstFloat * | Dst, | ||
| srcFloat * | Src | ||
| ) |
Definition at line 184 of file copy_color_spinor_mg.cuh.
References errorQuda, quda::ColorSpinorField::Nspin(), and src.

◆ copyGenericColorSpinor() [2/3]
| void quda::copyGenericColorSpinor | ( | ColorSpinorField & | dst, |
| const ColorSpinorField & | src, | ||
| QudaFieldLocation | location, | ||
| dstFloat * | Dst, | ||
| srcFloat * | Src, | ||
| float * | dstNorm, | ||
| float * | srcNorm | ||
| ) |
Definition at line 376 of file copy_color_spinor.cuh.
References errorQuda, quda::ColorSpinorField::FieldOrder(), quda::ColorSpinorField::Ndim(), QUDA_EVEN_ODD_SITE_ORDER, QUDA_FULL_SITE_SUBSET, QUDA_LEXICOGRAPHIC_SITE_ORDER, QUDA_ODD_EVEN_SITE_ORDER, QUDA_QDPJIT_FIELD_ORDER, quda::ColorSpinorField::SiteOrder(), quda::ColorSpinorField::SiteSubset(), src, and quda::ColorSpinorField::Volume().
◆ CopyGenericColorSpinor() [2/2]
| void quda::CopyGenericColorSpinor | ( | ColorSpinorField & | dst, |
| const ColorSpinorField & | src, | ||
| QudaFieldLocation | location, | ||
| dstFloat * | Dst, | ||
| srcFloat * | Src, | ||
| float * | dstNorm = 0, |
||
| float * | srcNorm = 0 |
||
| ) |
Definition at line 411 of file copy_color_spinor.cuh.
References errorQuda, quda::ColorSpinorField::Nspin(), and src.

◆ copyGenericColorSpinor() [3/3]
| void quda::copyGenericColorSpinor | ( | ColorSpinorField & | dst, |
| const ColorSpinorField & | src, | ||
| QudaFieldLocation | location, | ||
| void * | Dst = 0, |
||
| void * | Src = 0, |
||
| void * | dstNorm = 0, |
||
| void * | srcNorm = 0 |
||
| ) |
Definition at line 23 of file copy_color_spinor.cu.
References copyGenericColorSpinorDD(), copyGenericColorSpinorDH(), copyGenericColorSpinorDS(), copyGenericColorSpinorHD(), copyGenericColorSpinorHH(), copyGenericColorSpinorHS(), copyGenericColorSpinorMGDD(), copyGenericColorSpinorMGDS(), copyGenericColorSpinorMGSD(), copyGenericColorSpinorMGSS(), copyGenericColorSpinorSD(), copyGenericColorSpinorSH(), copyGenericColorSpinorSS(), errorQuda, quda::ColorSpinorField::Ncolor(), quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, QUDA_HALF_PRECISION, QUDA_SINGLE_PRECISION, quda::ColorSpinorField::SiteSubset(), and src.
Referenced by quda::cpuColorSpinorField::copy(), quda::cudaColorSpinorField::copySpinorField(), quda::cudaColorSpinorField::loadSpinorField(), and quda::cudaColorSpinorField::saveSpinorField().
◆ copyGenericColorSpinorDD()
| void quda::copyGenericColorSpinorDD | ( | ColorSpinorField & | dst, |
| const ColorSpinorField & | src, | ||
| QudaFieldLocation | location, | ||
| void * | Dst, | ||
| void * | Src, | ||
| void * | a = 0, |
||
| void * | b = 0 |
||
| ) |
Definition at line 5 of file copy_color_spinor_dd.cu.
References src.
Referenced by copyGenericColorSpinor().

◆ copyGenericColorSpinorDH()
| void quda::copyGenericColorSpinorDH | ( | ColorSpinorField & | dst, |
| const ColorSpinorField & | src, | ||
| QudaFieldLocation | location, | ||
| void * | Dst, | ||
| void * | Src, | ||
| void * | a = 0, |
||
| void * | b = 0 |
||
| ) |
Definition at line 5 of file copy_color_spinor_dh.cu.
References src.
Referenced by copyGenericColorSpinor().

◆ copyGenericColorSpinorDS()
| void quda::copyGenericColorSpinorDS | ( | ColorSpinorField & | dst, |
| const ColorSpinorField & | src, | ||
| QudaFieldLocation | location, | ||
| void * | Dst, | ||
| void * | Src, | ||
| void * | a = 0, |
||
| void * | b = 0 |
||
| ) |
Definition at line 5 of file copy_color_spinor_ds.cu.
References src.
Referenced by copyGenericColorSpinor().

◆ copyGenericColorSpinorHD()
| void quda::copyGenericColorSpinorHD | ( | ColorSpinorField & | dst, |
| const ColorSpinorField & | src, | ||
| QudaFieldLocation | location, | ||
| void * | Dst, | ||
| void * | Src, | ||
| void * | a = 0, |
||
| void * | b = 0 |
||
| ) |
Definition at line 5 of file copy_color_spinor_hd.cu.
References src.
Referenced by copyGenericColorSpinor().

◆ copyGenericColorSpinorHH()
| void quda::copyGenericColorSpinorHH | ( | ColorSpinorField & | dst, |
| const ColorSpinorField & | src, | ||
| QudaFieldLocation | location, | ||
| void * | Dst, | ||
| void * | Src, | ||
| void * | a = 0, |
||
| void * | b = 0 |
||
| ) |
Definition at line 5 of file copy_color_spinor_hh.cu.
References src.
Referenced by copyGenericColorSpinor().

◆ copyGenericColorSpinorHS()
| void quda::copyGenericColorSpinorHS | ( | ColorSpinorField & | dst, |
| const ColorSpinorField & | src, | ||
| QudaFieldLocation | location, | ||
| void * | Dst, | ||
| void * | Src, | ||
| void * | a = 0, |
||
| void * | b = 0 |
||
| ) |
Definition at line 5 of file copy_color_spinor_hs.cu.
References src.
Referenced by copyGenericColorSpinor().

◆ copyGenericColorSpinorMGDD()
| void quda::copyGenericColorSpinorMGDD | ( | ColorSpinorField & | dst, |
| const ColorSpinorField & | src, | ||
| QudaFieldLocation | location, | ||
| void * | Dst, | ||
| void * | Src, | ||
| void * | a = 0, |
||
| void * | b = 0 |
||
| ) |
Definition at line 5 of file copy_color_spinor_mg_dd.cu.
References errorQuda, and INSTANTIATE_COLOR.
Referenced by copyGenericColorSpinor().

◆ copyGenericColorSpinorMGDS()
| void quda::copyGenericColorSpinorMGDS | ( | ColorSpinorField & | dst, |
| const ColorSpinorField & | src, | ||
| QudaFieldLocation | location, | ||
| void * | Dst, | ||
| void * | Src, | ||
| void * | a = 0, |
||
| void * | b = 0 |
||
| ) |
Definition at line 5 of file copy_color_spinor_mg_ds.cu.
References errorQuda, and INSTANTIATE_COLOR.
Referenced by copyGenericColorSpinor().

◆ copyGenericColorSpinorMGSD()
| void quda::copyGenericColorSpinorMGSD | ( | ColorSpinorField & | dst, |
| const ColorSpinorField & | src, | ||
| QudaFieldLocation | location, | ||
| void * | Dst, | ||
| void * | Src, | ||
| void * | a = 0, |
||
| void * | b = 0 |
||
| ) |
Definition at line 5 of file copy_color_spinor_mg_sd.cu.
References errorQuda, and INSTANTIATE_COLOR.
Referenced by copyGenericColorSpinor().

◆ copyGenericColorSpinorMGSS()
| void quda::copyGenericColorSpinorMGSS | ( | ColorSpinorField & | dst, |
| const ColorSpinorField & | src, | ||
| QudaFieldLocation | location, | ||
| void * | Dst, | ||
| void * | Src, | ||
| void * | a = 0, |
||
| void * | b = 0 |
||
| ) |
Definition at line 5 of file copy_color_spinor_mg_ss.cu.
References errorQuda, and INSTANTIATE_COLOR.
Referenced by copyGenericColorSpinor().

◆ copyGenericColorSpinorSD()
| void quda::copyGenericColorSpinorSD | ( | ColorSpinorField & | dst, |
| const ColorSpinorField & | src, | ||
| QudaFieldLocation | location, | ||
| void * | Dst, | ||
| void * | Src, | ||
| void * | a = 0, |
||
| void * | b = 0 |
||
| ) |
Definition at line 5 of file copy_color_spinor_sd.cu.
References src.
Referenced by copyGenericColorSpinor().

◆ copyGenericColorSpinorSH()
| void quda::copyGenericColorSpinorSH | ( | ColorSpinorField & | dst, |
| const ColorSpinorField & | src, | ||
| QudaFieldLocation | location, | ||
| void * | Dst, | ||
| void * | Src, | ||
| void * | a = 0, |
||
| void * | b = 0 |
||
| ) |
Definition at line 5 of file copy_color_spinor_sh.cu.
References src.
Referenced by copyGenericColorSpinor().

◆ copyGenericColorSpinorSS()
| void quda::copyGenericColorSpinorSS | ( | ColorSpinorField & | dst, |
| const ColorSpinorField & | src, | ||
| QudaFieldLocation | location, | ||
| void * | Dst, | ||
| void * | Src, | ||
| void * | a = 0, |
||
| void * | b = 0 |
||
| ) |
Definition at line 5 of file copy_color_spinor_ss.cu.
References src.
Referenced by copyGenericColorSpinor().

◆ copyGenericGauge()
| void quda::copyGenericGauge | ( | GaugeField & | out, |
| const GaugeField & | in, | ||
| QudaFieldLocation | location, | ||
| void * | Out = 0, |
||
| void * | In = 0, |
||
| void ** | ghostOut = 0, |
||
| void ** | ghostIn = 0, |
||
| int | type = 0 |
||
| ) |
This function is used for extracting the gauge ghost zone from a gauge field array. Defined in copy_gauge.cu.
- Parameters
-
out The output field to which we are copying in The input field from which we are copying location The location of where we are doing the copying (CPU or CUDA) Out The output buffer (optional) In The input buffer (optional) ghostOut The output ghost buffer (optional) ghostIn The input ghost buffer (optional) type The type of copy we doing (0 body and ghost else ghost only)
Definition at line 38 of file copy_gauge.cu.
References copyGenericGaugeDoubleOut(), copyGenericGaugeHalfOut(), copyGenericGaugeMG(), copyGenericGaugeSingleOut(), errorQuda, quda::LatticeField::GhostExchange(), in, quda::ColorSpinorField::Ncolor(), out, quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, QUDA_GHOST_EXCHANGE_PAD, QUDA_HALF_PRECISION, and QUDA_SINGLE_PRECISION.
Referenced by quda::cudaGaugeField::copy(), quda::cpuGaugeField::copy(), quda::cudaGaugeField::exchangeGhost(), quda::cudaGaugeField::injectGhost(), and quda::cudaGaugeField::saveCPUField().
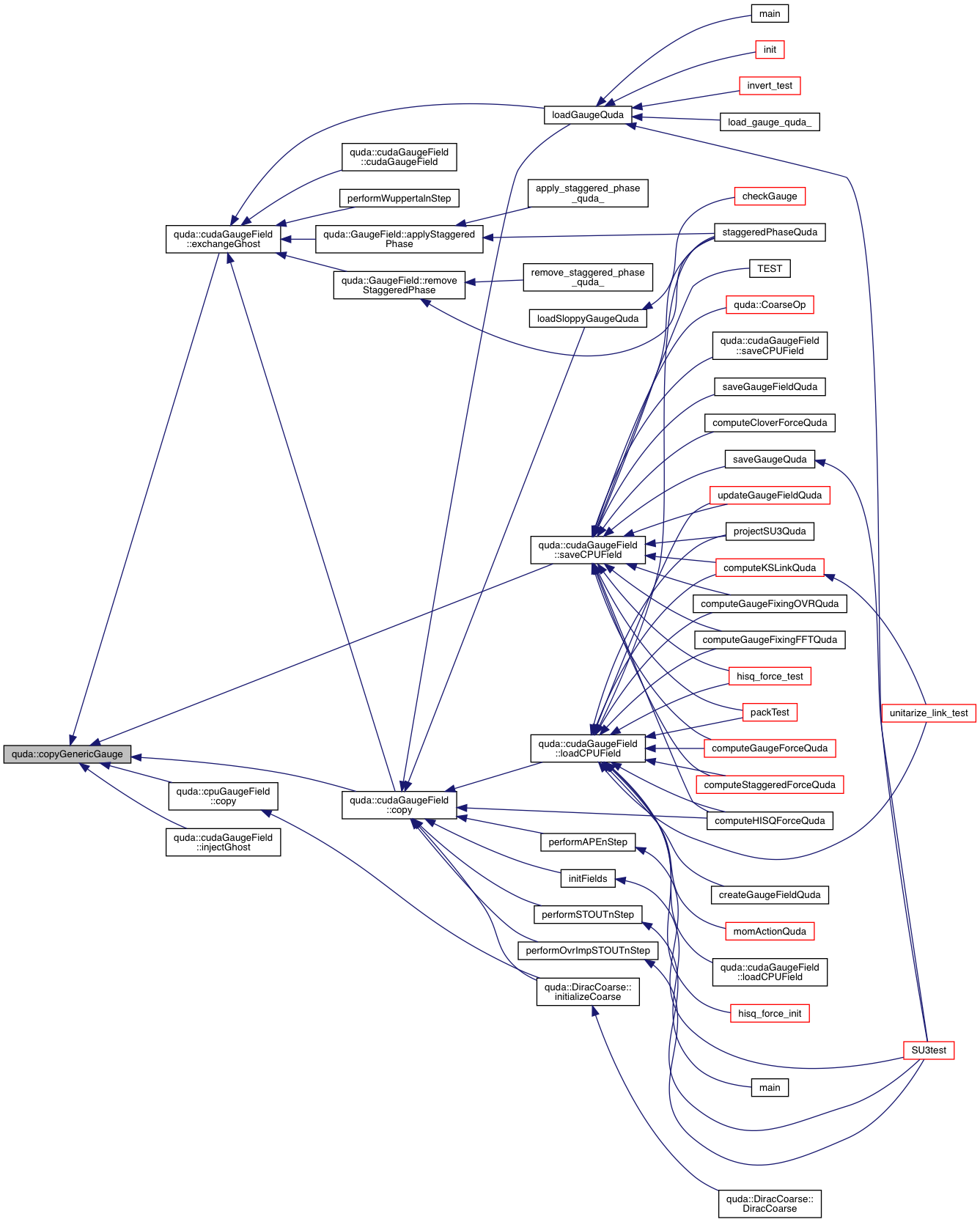
◆ copyGenericGaugeDoubleOut()
| void quda::copyGenericGaugeDoubleOut | ( | GaugeField & | out, |
| const GaugeField & | in, | ||
| QudaFieldLocation | location, | ||
| void * | Out, | ||
| void * | In, | ||
| void ** | ghostOut, | ||
| void ** | ghostIn, | ||
| int | type | ||
| ) |
Definition at line 5 of file copy_gauge_double.cu.
References copyGauge(), errorQuda, in, out, quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, QUDA_HALF_PRECISION, and QUDA_SINGLE_PRECISION.
Referenced by copyGenericGauge().

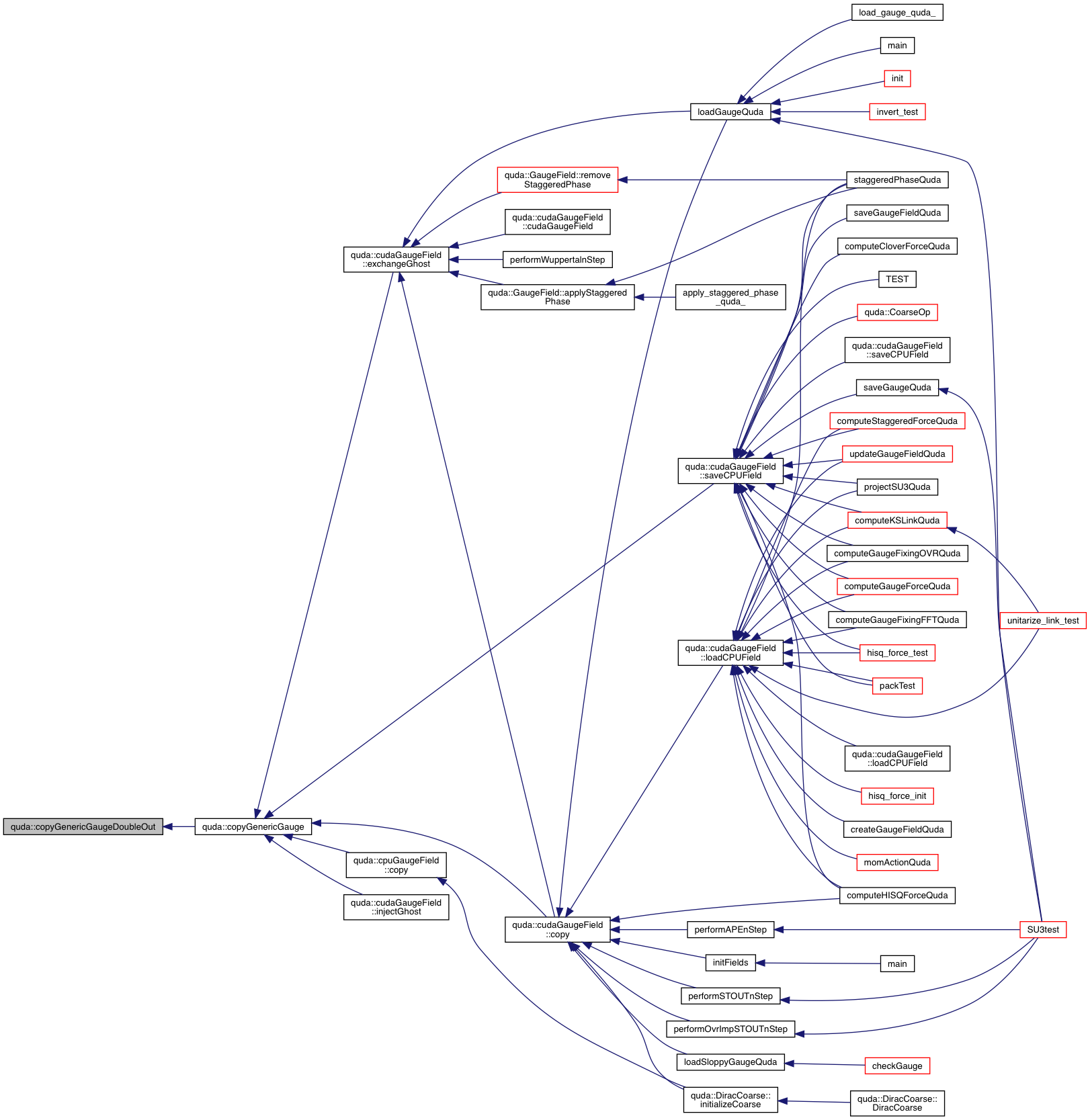
◆ copyGenericGaugeHalfOut()
| void quda::copyGenericGaugeHalfOut | ( | GaugeField & | out, |
| const GaugeField & | in, | ||
| QudaFieldLocation | location, | ||
| void * | Out, | ||
| void * | In, | ||
| void ** | ghostOut, | ||
| void ** | ghostIn, | ||
| int | type | ||
| ) |
Definition at line 5 of file copy_gauge_half.cu.
References copyGauge(), errorQuda, in, out, quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, QUDA_HALF_PRECISION, and QUDA_SINGLE_PRECISION.
Referenced by copyGenericGauge().

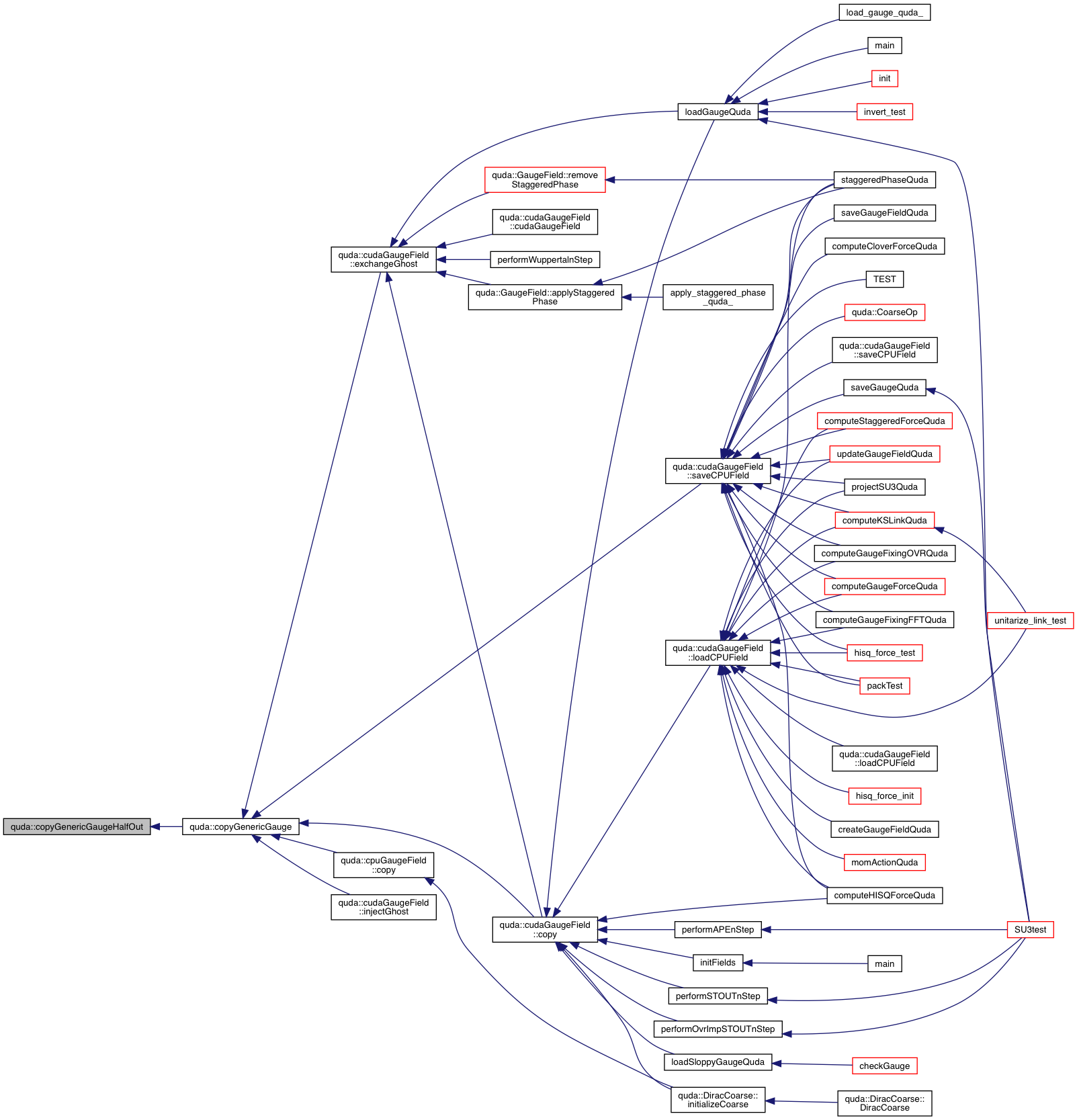
◆ copyGenericGaugeMG()
| void quda::copyGenericGaugeMG | ( | GaugeField & | out, |
| const GaugeField & | in, | ||
| QudaFieldLocation | location, | ||
| void * | Out, | ||
| void * | In, | ||
| void ** | ghostOut, | ||
| void ** | ghostIn, | ||
| int | type | ||
| ) |
Definition at line 153 of file copy_gauge_mg.cu.
References copyGaugeMG(), errorQuda, in, out, quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, and QUDA_SINGLE_PRECISION.
Referenced by copyGenericGauge().
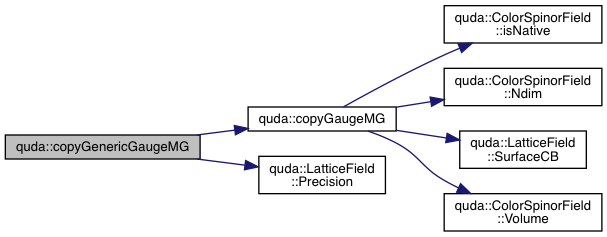
◆ copyGenericGaugeSingleOut()
| void quda::copyGenericGaugeSingleOut | ( | GaugeField & | out, |
| const GaugeField & | in, | ||
| QudaFieldLocation | location, | ||
| void * | Out, | ||
| void * | In, | ||
| void ** | ghostOut, | ||
| void ** | ghostIn, | ||
| int | type | ||
| ) |
Definition at line 5 of file copy_gauge_single.cu.
References copyGauge(), errorQuda, in, out, quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, QUDA_HALF_PRECISION, and QUDA_SINGLE_PRECISION.
Referenced by copyGenericGauge().

◆ copyGhost()
| void quda::copyGhost | ( | CopyGaugeArg< OutOrder, InOrder > | arg | ) |
Generic CPU gauge ghost reordering and packing
Definition at line 124 of file copy_gauge_helper.cuh.
References arg(), d, fused_exterior_ndeg_tm_dslash_cuda_gen::i, in, length, quda::gauge::Ncolor(), out, parity, and x.

◆ copyGhostKernel()
| __global__ void quda::copyGhostKernel | ( | CopyGaugeArg< OutOrder, InOrder > | arg | ) |
Generic CUDA kernel for copying the ghost zone. Adopts a similar form as the CPU version, using the same inlined functions.
Definition at line 154 of file copy_gauge_helper.cuh.
References arg(), blockDim, d, fused_exterior_ndeg_tm_dslash_cuda_gen::i, in, length, quda::gauge::Ncolor(), out, parity, and x.

◆ copyInterior() [1/2]
| __device__ __host__ void quda::copyInterior | ( | CopySpinorExArg< OutOrder, InOrder, Basis > & | arg, |
| int | X | ||
| ) |

◆ copyInterior() [2/2]
| void quda::copyInterior | ( | CopySpinorExArg< OutOrder, InOrder, Basis > & | arg | ) |
Definition at line 225 of file extended_color_spinor_utilities.cu.
References arg().

◆ copyInteriorKernel()
| __global__ void quda::copyInteriorKernel | ( | CopySpinorExArg< OutOrder, InOrder, Basis > | arg | ) |
Definition at line 211 of file extended_color_spinor_utilities.cu.
References arg(), blockDim, and gridDim.

◆ copyLinkToArray() [1/2]
Definition at line 978 of file quda_matrix.h.
References array, and fused_exterior_ndeg_tm_dslash_cuda_gen::i.
◆ copyLinkToArray() [2/2]
|
inline |
Definition at line 992 of file quda_matrix.h.
References array, and fused_exterior_ndeg_tm_dslash_cuda_gen::i.
◆ copyMom()
| void quda::copyMom | ( | Arg & | arg, |
| const GaugeField & | out, | ||
| const GaugeField & | in, | ||
| QudaFieldLocation | location | ||
| ) |
Definition at line 257 of file copy_gauge_inc.cu.
References quda::CopyGauge< FloatOut, FloatIn, length, OutOrder, InOrder, isGhost >::apply(), arg(), errorQuda, in, out, QUDA_CPU_FIELD_LOCATION, and QUDA_CUDA_FIELD_LOCATION.
◆ copySpinorEx() [1/2]
| void quda::copySpinorEx | ( | OutOrder | outOrder, |
| const InOrder | inOrder, | ||
| const Basis | basis, | ||
| const int * | E, | ||
| const int * | X, | ||
| const int | parity, | ||
| const bool | extend, | ||
| const ColorSpinorField & | meta, | ||
| QudaFieldLocation | location | ||
| ) |
Definition at line 279 of file extended_color_spinor_utilities.cu.
References quda::CopySpinorEx< FloatOut, FloatIn, Ns, Nc, OutOrder, InOrder, Basis, extend >::apply(), arg(), checkCudaError, E, parity, QUDA_CUDA_FIELD_LOCATION, and X.
◆ copySpinorEx() [2/2]
| void quda::copySpinorEx | ( | OutOrder | outOrder, |
| InOrder | inOrder, | ||
| const QudaGammaBasis | outBasis, | ||
| const QudaGammaBasis | inBasis, | ||
| const int * | E, | ||
| const int * | X, | ||
| const int | parity, | ||
| const bool | extend, | ||
| const ColorSpinorField & | meta, | ||
| QudaFieldLocation | location | ||
| ) |
Definition at line 294 of file extended_color_spinor_utilities.cu.
References E, errorQuda, parity, QUDA_DEGRAND_ROSSI_GAMMA_BASIS, QUDA_UKQCD_GAMMA_BASIS, and X.
◆ cos() [1/3]
|
inline |
Definition at line 35 of file complex_quda.h.
Referenced by quda::Trig< isHalf, T >::Cos(), cos(), cosh(), exponentiate_iQ(), genGauss(), new_load_half(), polar(), polarSu3(), sin(), quda::Trig< isHalf, T >::SinCos(), sinh(), and tan().
◆ cos() [2/3]
|
inline |
◆ cos() [3/3]
◆ cosh() [1/3]
|
inline |
◆ cosh() [2/3]
|
inline |
◆ cosh() [3/3]
◆ covDev()
| void quda::covDev | ( | cudaColorSpinorField * | out, |
| cudaGaugeField & | gauge, | ||
| const cudaColorSpinorField * | in, | ||
| const int | parity, | ||
| const int | mu, | ||
| TimeProfile & | profile | ||
| ) |

◆ create_gauge_buffer()
| void * quda::create_gauge_buffer | ( | size_t | bytes, |
| QudaGaugeFieldOrder | order, | ||
| QudaFieldGeometry | geometry | ||
| ) |
Definition at line 548 of file cuda_gauge_field.cu.
References quda::blas::bytes, d, pool_device_malloc, and QUDA_QDP_GAUGE_ORDER.
Referenced by quda::cudaGaugeField::copy(), quda::cpuGaugeField::copy(), and quda::cudaGaugeField::saveCPUField().
◆ create_ghost_buffer()
| void ** quda::create_ghost_buffer | ( | size_t | bytes[], |
| QudaGaugeFieldOrder | order, | ||
| QudaFieldGeometry | geometry | ||
| ) |
Definition at line 559 of file cuda_gauge_field.cu.
References quda::blas::bytes, d, and pool_device_malloc.
Referenced by quda::cudaGaugeField::copy(), quda::cpuGaugeField::copy(), and quda::cudaGaugeField::saveCPUField().
◆ createDirac()
| void quda::createDirac | ( | Dirac *& | d, |
| Dirac *& | dSloppy, | ||
| Dirac *& | dPre, | ||
| QudaInvertParam & | param, | ||
| const bool | pc_solve | ||
| ) |
Definition at line 1513 of file interface_quda.cpp.
References quda::Dirac::create(), d, param, QUDA_INC_EIGCG_INVERTER, setDiracParam(), setDiracPreParam(), and setDiracSloppyParam().
Referenced by invertMultiShiftQuda(), invertMultiSrcQuda(), and invertQuda().
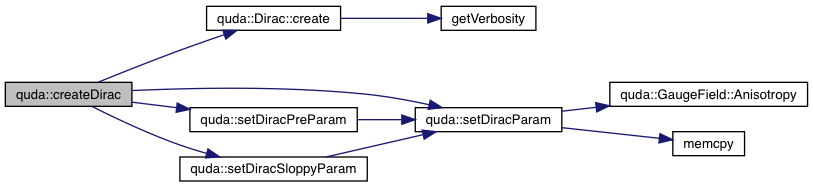
◆ createDslashEvents()
| void quda::createDslashEvents | ( | ) |
Definition at line 86 of file dslash_quda.cu.
References quda::dslash::aux_worker, checkCudaError, dslash::commsEnd_d, dslash::commsEnd_h, quda::dslash::dslashStart, quda::dslash::gatherEnd, quda::dslash::gatherStart, fused_exterior_ndeg_tm_dslash_cuda_gen::i, mapped_malloc, Nstream, quda::dslash::packEnd, quda::dslash::scatterEnd, and quda::dslash::scatterStart.
Referenced by initQudaMemory().
◆ d2i()
Definition at line 147 of file register_traits.h.
References d.
◆ deserializeTuneCache()
|
static |
Deserialize tunecache from an istream, useful for reading a file or receiving from other nodes.
Definition at line 116 of file tune.cpp.
References a, quda::TuneKey::aux, quda::TuneKey::aux_n, errorQuda, getline(), in, n, quda::TuneKey::name, quda::TuneKey::name_n, param, snprintf(), tunecache, quda::TuneKey::volume, and quda::TuneKey::volume_n.
Referenced by broadcastTuneCache(), and loadTuneCache().
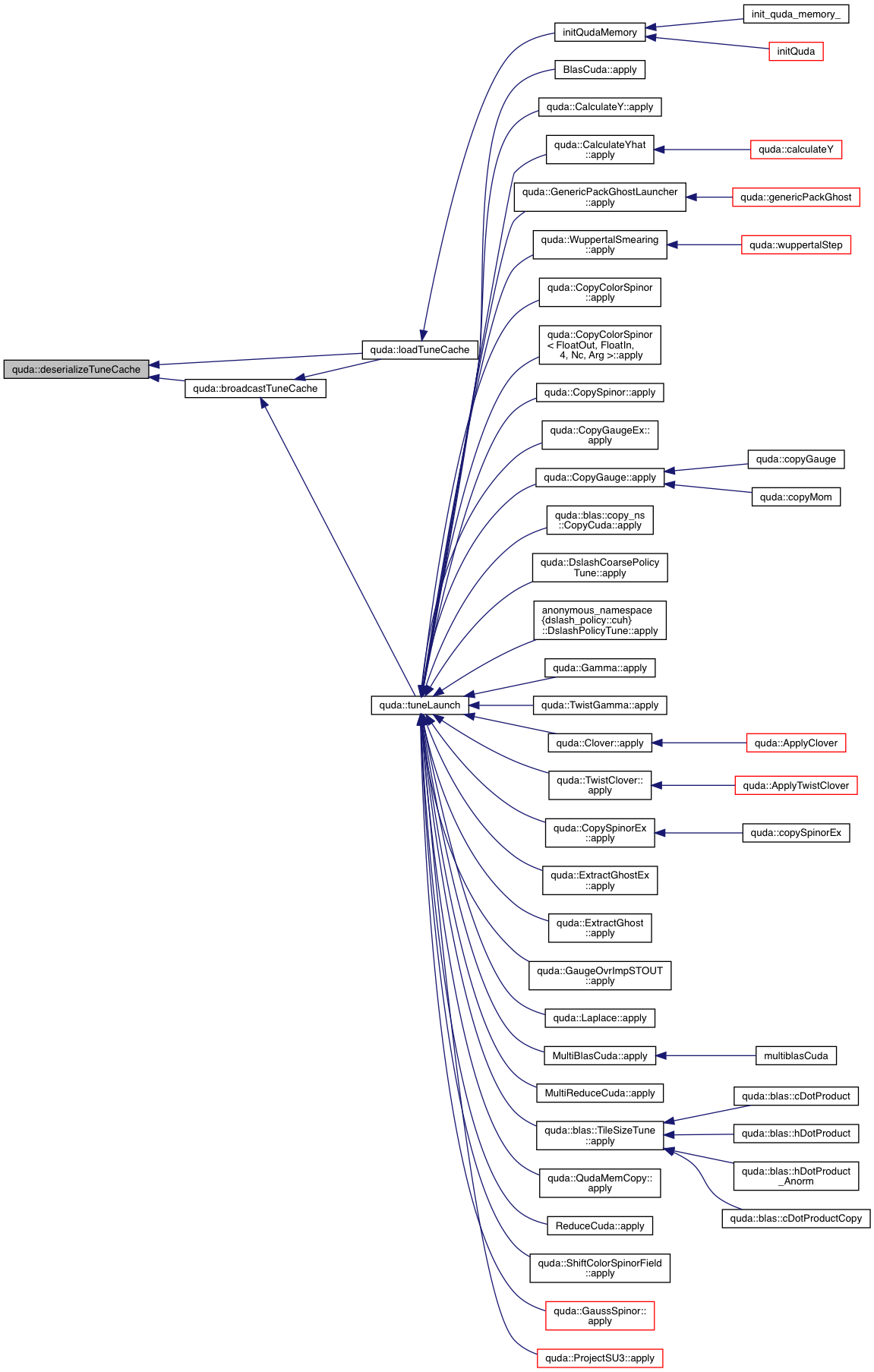
◆ destroyDslashEvents()
| void quda::destroyDslashEvents | ( | ) |
Definition at line 118 of file dslash_quda.cu.
References checkCudaError, dslash::commsEnd_h, quda::dslash::dslashStart, quda::dslash::gatherEnd, quda::dslash::gatherStart, host_free, fused_exterior_ndeg_tm_dslash_cuda_gen::i, Nstream, quda::dslash::packEnd, quda::dslash::scatterEnd, and quda::dslash::scatterStart.
Referenced by endQuda().
◆ device_allocated_peak()
| long quda::device_allocated_peak | ( | ) |
- Returns
- peak device memory allocated
Definition at line 57 of file malloc.cpp.
References DEVICE, and max_total_bytes.
◆ device_free_()
| void quda::device_free_ | ( | const char * | func, |
| const char * | file, | ||
| int | line, | ||
| void * | ptr | ||
| ) |
Free device memory allocated with device_malloc(). This function should only be called via the device_free() macro, defined in malloc_quda.h
Definition at line 292 of file malloc.cpp.
References alloc, count, DEVICE, err, errorQuda, func, printfQuda, ptr, and track_free().
Referenced by quda::pool::device_free_(), and quda::pool::device_malloc_().

◆ device_malloc_()
Perform a standard cudaMalloc() with error-checking. This function should only be called via the device_malloc() macro, defined in malloc_quda.h
Definition at line 167 of file malloc.cpp.
References a, DEVICE, err, errorQuda, func, printfQuda, ptr, size, and track_malloc().
Referenced by quda::pool::device_malloc_().


◆ device_pinned_free_()
| void quda::device_pinned_free_ | ( | const char * | func, |
| const char * | file, | ||
| int | line, | ||
| void * | ptr | ||
| ) |
Free device memory allocated with device_pinned malloc(). This function should only be called via the device_pinned_free() macro, defined in malloc_quda.h
Definition at line 316 of file malloc.cpp.
References alloc, count, DEVICE, err, errorQuda, func, printfQuda, ptr, and track_free().

◆ device_pinned_malloc_()
Perform a cuMemAlloc with error-checking. This function is to guarantee a unique memory allocation on the device, since cudaMalloc can be redirected (as is the case with QDPJIT). This should only be called via the device_pinned_malloc() macro, defined in malloc_quda.h.
Definition at line 194 of file malloc.cpp.
References a, DEVICE, err, errorQuda, func, printfQuda, ptr, size, and track_malloc().

◆ disableProfileCount()
| void quda::disableProfileCount | ( | ) |
Definition at line 107 of file tune.cpp.
References profile_count.
Referenced by quda::DslashCoarsePolicyTune::DslashCoarsePolicyTune(), anonymous_namespace{dslash_policy.cuh}::DslashPolicyTune::DslashPolicyTune(), and quda::blas::TileSizeTune< ReducerDiagonal, writeDiagonal, ReducerOffDiagonal, writeOffDiagonal >::TileSizeTune().
◆ domainWallDslashCuda() [1/2]
| void quda::domainWallDslashCuda | ( | cudaColorSpinorField * | out, |
| const cudaGaugeField & | gauge, | ||
| const cudaColorSpinorField * | in, | ||
| const int | parity, | ||
| const int | dagger, | ||
| const cudaColorSpinorField * | x, | ||
| const double & | m_f, | ||
| const double & | k, | ||
| const int * | commDim, | ||
| TimeProfile & | profile | ||
| ) |
Definition at line 203 of file dslash_domain_wall.cu.
References deg_tm_dslash_cuda_gen::dagger, deg_tm_dslash_cuda_gen::dslash, errorQuda, fused_exterior_ndeg_tm_dslash_cuda_gen::i, in, out, parity, QUDA_DOUBLE_PRECISION, QUDA_HALF_PRECISION, QUDA_MAX_DIM, QUDA_SINGLE_PRECISION, and x.
Referenced by quda::DiracDomainWall::Dslash(), quda::DiracDomainWall4DPC::Dslash4(), quda::DiracDomainWall4DPC::Dslash4Xpay(), quda::DiracDomainWall4DPC::Dslash5(), quda::DiracDomainWall4DPC::Dslash5inv(), quda::DiracDomainWall4DPC::Dslash5invXpay(), quda::DiracDomainWall4DPC::Dslash5Xpay(), and quda::DiracDomainWall::DslashXpay().
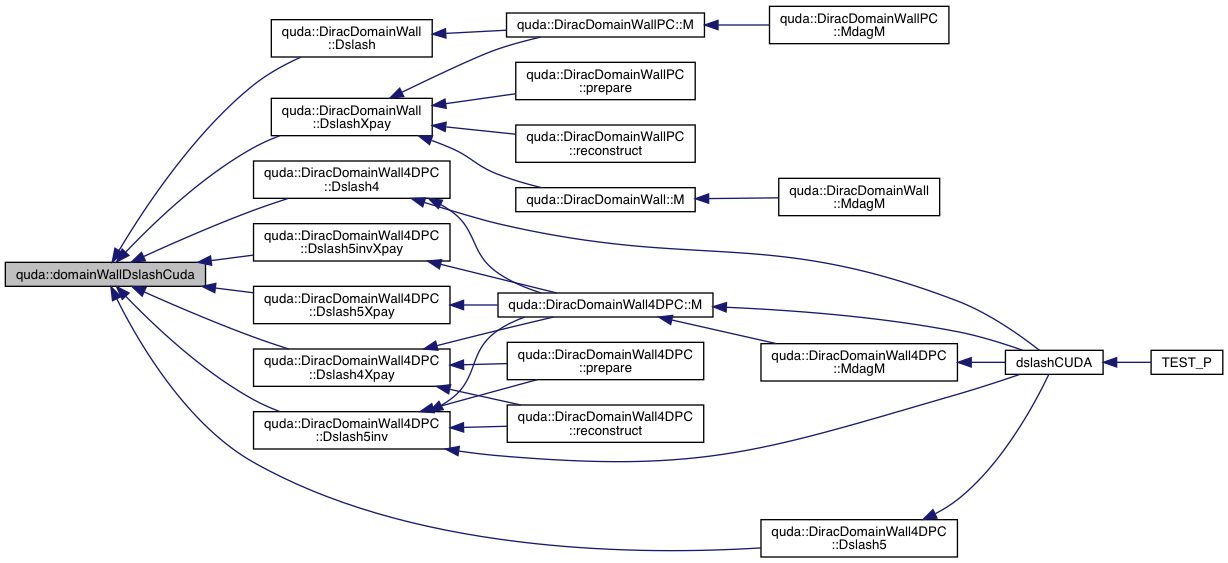
◆ domainWallDslashCuda() [2/2]
| void quda::domainWallDslashCuda | ( | cudaColorSpinorField * | out, |
| const cudaGaugeField & | gauge, | ||
| const cudaColorSpinorField * | in, | ||
| const int | parity, | ||
| const int | dagger, | ||
| const cudaColorSpinorField * | x, | ||
| const double & | m_f, | ||
| const double & | a, | ||
| const double & | b, | ||
| const int * | commDim, | ||
| const int | DS_type, | ||
| TimeProfile & | profile | ||
| ) |
Definition at line 252 of file dslash_domain_wall_4d.cu.
References a, b, deg_tm_dslash_cuda_gen::dagger, deg_tm_dslash_cuda_gen::dslash, errorQuda, fused_exterior_ndeg_tm_dslash_cuda_gen::i, in, out, parity, QUDA_DOUBLE_PRECISION, QUDA_HALF_PRECISION, QUDA_MAX_DIM, QUDA_SINGLE_PRECISION, and x.
◆ enableProfileCount()
| void quda::enableProfileCount | ( | ) |
Definition at line 108 of file tune.cpp.
References profile_count.
Referenced by quda::DslashCoarsePolicyTune::DslashCoarsePolicyTune(), anonymous_namespace{dslash_policy.cuh}::DslashPolicyTune::DslashPolicyTune(), and quda::blas::TileSizeTune< ReducerDiagonal, writeDiagonal, ReducerOffDiagonal, writeOffDiagonal >::TileSizeTune().
◆ ErrorSU3()
| __device__ __host__ double quda::ErrorSU3 | ( | const Matrix< Cmplx, 3 > & | matrix | ) |
Definition at line 1083 of file quda_matrix.h.
References conj(), fused_exterior_ndeg_tm_dslash_cuda_gen::i, and norm().
Referenced by computeOvrImpSTOUTStep().
◆ exchangeExtendedGhost()
| void quda::exchangeExtendedGhost | ( | cudaColorSpinorField * | spinor, |
| int | R[], | ||
| int | parity, | ||
| cudaStream_t * | stream_p | ||
| ) |
Definition at line 25 of file extended_color_spinor_utilities.cu.
References commDim(), deg_tm_dslash_cuda_gen::dagger, dim, dslash::gatherEnd, fused_exterior_ndeg_tm_dslash_cuda_gen::i, parity, qudaDeviceSynchronize(), qudaEventRecord(), R, spinor, and streams.
Referenced by gaussGaugeQuda(), and quda::XSD::operator()().

◆ exp() [1/3]
|
inline |
◆ exp() [2/3]
|
inline |
Definition at line 954 of file complex_quda.h.
References exp(), polar(), and z.
◆ exp() [3/3]
◆ exponentiate_iQ()
|
inline |
Definition at line 1110 of file quda_matrix.h.
References acos(), cos(), getDeterminant(), getTrace(), parity, pow(), setIdentity(), setZero(), sin(), sqrt(), and x.
Referenced by computeOvrImpSTOUTStep().

◆ extendedCopyColorSpinor() [1/2]
| void quda::extendedCopyColorSpinor | ( | InOrder & | inOrder, |
| ColorSpinorField & | out, | ||
| QudaGammaBasis | inBasis, | ||
| const int * | E, | ||
| const int * | X, | ||
| const int | parity, | ||
| const bool | extend, | ||
| QudaFieldLocation | location, | ||
| FloatOut * | Out, | ||
| float * | outNorm | ||
| ) |
◆ extendedCopyColorSpinor() [2/2]
| void quda::extendedCopyColorSpinor | ( | ColorSpinorField & | out, |
| const ColorSpinorField & | in, | ||
| const int | parity, | ||
| const QudaFieldLocation | location, | ||
| FloatOut * | Out, | ||
| FloatIn * | In, | ||
| float * | outNorm, | ||
| float * | inNorm | ||
| ) |
◆ extractExtendedGaugeGhost()
| void quda::extractExtendedGaugeGhost | ( | const GaugeField & | u, |
| int | dim, | ||
| const int * | R, | ||
| void ** | ghost, | ||
| bool | extract | ||
| ) |
This function is used for extracting the gauge ghost zone from a gauge field array. Defined in extract_gauge_ghost.cu.
- Parameters
-
u The gauge field from which we want to extract/pack the ghost zone dim The dimension in which we are packing/unpacking ghost The array where we want to pack/unpack the ghost zone into/from extract Whether we are extracting into ghost or injecting from ghost
Definition at line 422 of file extract_gauge_ghost_extended.cu.
References dim, errorQuda, extractGhostEx(), quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, QUDA_HALF_PRECISION, QUDA_SINGLE_PRECISION, and R.
Referenced by quda::cudaGaugeField::exchangeExtendedGhost(), and quda::cpuGaugeField::exchangeExtendedGhost().

◆ extractGaugeGhost()
| void quda::extractGaugeGhost | ( | const GaugeField & | u, |
| void ** | ghost, | ||
| bool | extract = true, |
||
| int | offset = 0 |
||
| ) |
This function is used for extracting the gauge ghost zone from a gauge field array. Defined in extract_gauge_ghost.cu.
- Parameters
-
u The gauge field from which we want to extract the ghost zone ghost The array where we want to pack the ghost zone into extract Where we are extracting into ghost or injecting from ghost offset By default we exchange the nDim site-vector of links in the first nDim dimensions; offset allows us to instead exchange the links in nDim+offset dimensions. This is used to faciliate sending bi-directional links which is needed for the coarse links.
Definition at line 103 of file extract_gauge_ghost.cu.
References errorQuda, extractGaugeGhostMG(), extractGhost(), quda::GaugeField::Ncolor(), offset, quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, QUDA_HALF_PRECISION, and QUDA_SINGLE_PRECISION.
Referenced by quda::cudaGaugeField::exchangeGhost(), quda::cpuGaugeField::exchangeGhost(), quda::cudaGaugeField::injectGhost(), and quda::cpuGaugeField::injectGhost().
◆ extractGaugeGhostMG()
| void quda::extractGaugeGhostMG | ( | const GaugeField & | u, |
| void ** | ghost, | ||
| bool | extract, | ||
| int | offset | ||
| ) |
Definition at line 74 of file extract_gauge_ghost_mg.cu.
References errorQuda, extractGhostMG(), offset, quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, and QUDA_SINGLE_PRECISION.
Referenced by extractGaugeGhost().
◆ extractGhost() [1/3]
| void quda::extractGhost | ( | const GaugeField & | u, |
| Float ** | Ghost, | ||
| bool | extract, | ||
| int | offset | ||
| ) |
This is the template driver for extractGhost
Definition at line 10 of file extract_gauge_ghost.cu.
References errorQuda, quda::GaugeField::isNative(), length, quda::GaugeField::LinkType(), offset, quda::GaugeField::Order(), QUDA_ASQTAD_FAT_LINKS, QUDA_BQCD_GAUGE_ORDER, QUDA_CPS_WILSON_GAUGE_ORDER, QUDA_CPU_FIELD_LOCATION, QUDA_CUDA_FIELD_LOCATION, QUDA_MILC_GAUGE_ORDER, QUDA_QDP_GAUGE_ORDER, QUDA_QDPJIT_GAUGE_ORDER, QUDA_RECONSTRUCT_12, QUDA_RECONSTRUCT_13, QUDA_RECONSTRUCT_8, QUDA_RECONSTRUCT_9, QUDA_RECONSTRUCT_NO, QUDA_TIFR_GAUGE_ORDER, QUDA_TIFR_PADDED_GAUGE_ORDER, and quda::GaugeField::Reconstruct().
Referenced by extractGaugeGhost().
◆ extractGhost() [2/3]
| void quda::extractGhost | ( | ExtractGhostArg< Order, nDim > | arg | ) |
Generic CPU gauge ghost extraction and packing NB This routines is specialized to four dimensions
Definition at line 39 of file extract_gauge_ghost_helper.cuh.
References a, arg(), b, c, d, dim, fused_exterior_ndeg_tm_dslash_cuda_gen::i, length, quda::gauge::Ncolor(), and parity.

◆ extractGhost() [3/3]
| void quda::extractGhost | ( | Order | order, |
| const GaugeField & | u, | ||
| QudaFieldLocation | location, | ||
| bool | extract, | ||
| int | offset | ||
| ) |
Generic gauge ghost extraction and packing (or the converse) NB This routines is specialized to four dimensions
Definition at line 229 of file extract_gauge_ghost_helper.cuh.
References arg(), commDim(), dim, extractor(), f, quda::GaugeField::Nface(), offset, X, and quda::LatticeField::X().
◆ extractGhostEx() [1/3]
| void quda::extractGhostEx | ( | ExtractGhostExArg< Order, nDim, dim > | arg | ) |
Generic CPU gauge ghost extraction and packing NB This routines is specialized to four dimensions
Definition at line 96 of file extract_gauge_ghost_extended.cu.
References a, arg(), b, c, d, dim, and parity.
Referenced by extractExtendedGaugeGhost().

◆ extractGhostEx() [2/3]
| void quda::extractGhostEx | ( | Order | order, |
| const int | dim, | ||
| const int * | surfaceCB, | ||
| const int * | E, | ||
| const int * | R, | ||
| bool | extract, | ||
| const GaugeField & | u, | ||
| QudaFieldLocation | location | ||
| ) |
Generic CPU gauge ghost extraction and packing NB This routines is specialized to four dimensions
- Parameters
-
E the extended gauge dimensions R array holding the radius of the extended region extract Whether we are extracting or injecting the ghost zone
Definition at line 256 of file extract_gauge_ghost_extended.cu.
References arg(), C0, C1, checkCudaError, commDim(), d, dim, E, errorQuda, extractor(), R, and X.
◆ extractGhostEx() [3/3]
| void quda::extractGhostEx | ( | const GaugeField & | u, |
| int | dim, | ||
| const int * | R, | ||
| Float ** | Ghost, | ||
| bool | extract | ||
| ) |
This is the template driver for extractGhost
Definition at line 328 of file extract_gauge_ghost_extended.cu.
References dim, errorQuda, quda::GaugeField::isNative(), length, quda::GaugeField::LinkType(), quda::GaugeField::Order(), QUDA_ASQTAD_FAT_LINKS, QUDA_BQCD_GAUGE_ORDER, QUDA_CPS_WILSON_GAUGE_ORDER, QUDA_CPU_FIELD_LOCATION, QUDA_CUDA_FIELD_LOCATION, QUDA_MILC_GAUGE_ORDER, QUDA_QDP_GAUGE_ORDER, QUDA_QDPJIT_GAUGE_ORDER, QUDA_RECONSTRUCT_12, QUDA_RECONSTRUCT_13, QUDA_RECONSTRUCT_8, QUDA_RECONSTRUCT_9, QUDA_RECONSTRUCT_NO, QUDA_TIFR_GAUGE_ORDER, R, quda::GaugeField::Reconstruct(), quda::LatticeField::SurfaceCB(), and quda::LatticeField::X().
◆ extractGhostExKernel()
| __global__ void quda::extractGhostExKernel | ( | ExtractGhostExArg< Order, nDim, dim > | arg | ) |
Generic GPU gauge ghost extraction and packing NB This routines is specialized to four dimensions FIXME this implementation will have two-way warp divergence Generic CPU gauge ghost extraction and packing NB This routines is specialized to four dimensions
Definition at line 141 of file extract_gauge_ghost_extended.cu.
References a, arg(), b, blockDim, c, d, dim, parity, and X.

◆ extractGhostKernel()
| __global__ void quda::extractGhostKernel | ( | ExtractGhostArg< Order, nDim > | arg | ) |
Generic GPU gauge ghost extraction and packing NB This routines is specialized to four dimensions FIXME this implementation will have two-way warp divergence
Definition at line 106 of file extract_gauge_ghost_helper.cuh.
References a, arg(), b, blockDim, c, d, dim, fused_exterior_ndeg_tm_dslash_cuda_gen::i, length, quda::gauge::Ncolor(), parity, and X.

◆ extractGhostMG() [1/2]
| void quda::extractGhostMG | ( | const GaugeField & | u, |
| Float ** | Ghost, | ||
| bool | extract, | ||
| int | offset | ||
| ) |
This is the template driver for extractGhost
Definition at line 15 of file extract_gauge_ghost_mg.cu.
References errorQuda, quda::GaugeField::isNative(), length, offset, quda::GaugeField::Order(), QUDA_CPU_FIELD_LOCATION, QUDA_CUDA_FIELD_LOCATION, QUDA_QDP_GAUGE_ORDER, QUDA_RECONSTRUCT_NO, and quda::GaugeField::Reconstruct().
Referenced by extractGaugeGhostMG().
◆ extractGhostMG() [2/2]
| void quda::extractGhostMG | ( | const GaugeField & | u, |
| Float ** | Ghost, | ||
| bool | extract, | ||
| int | offset | ||
| ) |
This is the template driver for extractGhost
Definition at line 53 of file extract_gauge_ghost_mg.cu.
References errorQuda, quda::GaugeField::LinkType(), quda::GaugeField::Ncolor(), offset, QUDA_COARSE_LINKS, QUDA_RECONSTRUCT_NO, and quda::GaugeField::Reconstruct().
◆ extractor()
| __device__ __host__ void quda::extractor | ( | Arg & | arg, |
| int | dir, | ||
| int | a, | ||
| int | b, | ||
| int | c, | ||
| int | d, | ||
| int | g, | ||
| int | parity | ||
| ) |
Definition at line 54 of file extract_gauge_ghost_extended.cu.
References a, arg(), b, c, d, dim, length, and parity.
Referenced by extractGhost(), and extractGhostEx().

◆ f2i()
Definition at line 138 of file register_traits.h.
References f.
Referenced by copy().

◆ fatLongKSLink()
| void quda::fatLongKSLink | ( | cudaGaugeField * | fat, |
| cudaGaugeField * | lng, | ||
| const cudaGaugeField & | gauge, | ||
| const double * | coeff | ||
| ) |
Compute the fat and long links for an improved staggered (Kogut-Susskind) fermions.
- Parameters
-
fat[out] The computed fat link lng[out] The computed long link (only computed if lng!=0) u[in] The input gauge field coeff[in] Array of path coefficients
Definition at line 524 of file llfat_quda.cu.
References checkCudaError, dw_dslash_4D_cuda_gen::coeff(), quda::GaugeFieldParam::create, errorQuda, fabs(), gParam, MIN_COEFF, quda::LatticeFieldParam::precision, QUDA_NULL_FIELD_CREATE, QUDA_RECONSTRUCT_NO, qudaDeviceSynchronize(), quda::GaugeFieldParam::reconstruct, quda::GaugeField::Reconstruct(), quda::GaugeFieldParam::setPrecision(), and quda::LatticeField::X().
Referenced by computeKSLinkQuda().

◆ file_name()
|
inline |
Definition at line 48 of file malloc_quda.h.
References r_slant(), str_end(), and str_slant().
◆ fillEigCGInnerSolverParam()
|
static |
Definition at line 210 of file inv_eigcg_quda.cpp.
References quda::SolverParam::delta, e, quda::SolverParam::gflops, quda::SolverParam::inv_type, quda::SolverParam::inv_type_precondition, quda::SolverParam::is_preconditioner, quda::SolverParam::iter, quda::SolverParam::maxiter, quda::SolverParam::maxiter_precondition, quda::SolverParam::precision, quda::SolverParam::precision_precondition, quda::SolverParam::precision_sloppy, quda::SolverParam::preserve_source, QUDA_EIGCG_INVERTER, QUDA_INVALID_INVERTER, QUDA_PRESERVE_SOURCE_NO, QUDA_PRESERVE_SOURCE_YES, quda::SolverParam::secs, quda::SolverParam::tol, quda::SolverParam::tol_precondition, and quda::SolverParam::use_sloppy_partial_accumulator.
Referenced by quda::IncEigCG::IncEigCG().

◆ fillFGMResDRInnerSolveParam()
| void quda::fillFGMResDRInnerSolveParam | ( | SolverParam & | inner, |
| const SolverParam & | outer | ||
| ) |
Definition at line 187 of file inv_gmresdr_quda.cpp.
References quda::SolverParam::delta, e, quda::SolverParam::gflops, quda::SolverParam::global_reduction, quda::SolverParam::inv_type, quda::SolverParam::inv_type_precondition, quda::SolverParam::is_preconditioner, quda::SolverParam::iter, quda::SolverParam::maxiter, quda::SolverParam::maxiter_precondition, quda::SolverParam::precision, quda::SolverParam::precision_precondition, quda::SolverParam::precision_sloppy, quda::SolverParam::preserve_source, QUDA_INVALID_INVERTER, QUDA_PRESERVE_SOURCE_NO, QUDA_PRESERVE_SOURCE_YES, quda::SolverParam::secs, quda::SolverParam::tol, quda::SolverParam::tol_precondition, and warningQuda.
Referenced by quda::GMResDR::GMResDR().

◆ fillInitCGSolverParam()
|
static |
Definition at line 233 of file inv_eigcg_quda.cpp.
References quda::SolverParam::delta, quda::SolverParam::gflops, quda::SolverParam::inv_type, quda::SolverParam::iter, quda::SolverParam::maxiter, quda::SolverParam::precision, quda::SolverParam::precision_precondition, quda::SolverParam::precision_sloppy, QUDA_CG_INVERTER, QUDA_USE_INIT_GUESS_YES, quda::SolverParam::secs, quda::SolverParam::tol, quda::SolverParam::tol_restart, quda::SolverParam::use_init_guess, and quda::SolverParam::use_sloppy_partial_accumulator.
Referenced by quda::IncEigCG::IncEigCG().

◆ fillInnerSolveParam()
| void quda::fillInnerSolveParam | ( | SolverParam & | inner, |
| const SolverParam & | outer | ||
| ) |
Definition at line 25 of file inv_gcr_quda.cpp.
References quda::SolverParam::delta, e, quda::SolverParam::gflops, quda::SolverParam::global_reduction, quda::SolverParam::inv_type, quda::SolverParam::inv_type_precondition, quda::SolverParam::is_preconditioner, quda::SolverParam::iter, quda::SolverParam::maxiter, quda::SolverParam::maxiter_precondition, quda::SolverParam::precision, quda::SolverParam::precision_precondition, quda::SolverParam::precision_sloppy, quda::SolverParam::preserve_source, QUDA_GCR_INVERTER, QUDA_INVALID_INVERTER, QUDA_PRESERVE_SOURCE_NO, QUDA_PRESERVE_SOURCE_YES, QUDA_USE_INIT_GUESS_NO, quda::SolverParam::secs, quda::SolverParam::tol, quda::SolverParam::tol_precondition, and quda::SolverParam::use_init_guess.
Referenced by quda::GCR::GCR(), and quda::BiCGstab::operator()().
◆ fillInnerSolverParam()
|
static |
Definition at line 18 of file inv_pcg_quda.cpp.
References quda::SolverParam::delta, e, quda::SolverParam::gflops, quda::SolverParam::inv_type, quda::SolverParam::inv_type_precondition, quda::SolverParam::is_preconditioner, quda::SolverParam::iter, quda::SolverParam::maxiter, quda::SolverParam::maxiter_precondition, quda::SolverParam::precision, quda::SolverParam::precision_precondition, quda::SolverParam::precision_sloppy, quda::SolverParam::preserve_source, QUDA_INVALID_INVERTER, QUDA_PCG_INVERTER, QUDA_PRESERVE_SOURCE_NO, QUDA_PRESERVE_SOURCE_YES, quda::SolverParam::secs, quda::SolverParam::tol, and quda::SolverParam::tol_precondition.
Referenced by quda::PreconCG::PreconCG().

◆ FillV()
| void quda::FillV | ( | ColorSpinorField & | V, |
| const std::vector< ColorSpinorField *> & | B, | ||
| int | Nvec | ||
| ) |
Helper method that takes a vector of ColorSpinorFields and packes them into a single matrix field.
- Parameters
-
[out] V The resulting packed matrix field [in] B Vector of ColorSpinorFields to be packed [in] Nvec Vector length
Definition at line 172 of file transfer_util.cu.
References errorQuda, QUDA_DOUBLE_PRECISION, QUDA_SINGLE_PRECISION, and V.
Referenced by quda::Transfer::fillV().

◆ flushProfile()
| void quda::flushProfile | ( | ) |
Flush profile contents, setting all counts to zero.
Definition at line 462 of file tune.cpp.
References entry, param, and tunecache.
Referenced by newDeflationQuda(), and newMultigridQuda().
◆ free_gauge_buffer()
| void quda::free_gauge_buffer | ( | void * | buffer, |
| QudaGaugeFieldOrder | order, | ||
| QudaFieldGeometry | geometry | ||
| ) |
Definition at line 571 of file cuda_gauge_field.cu.
References d, pool_device_free, and QUDA_QDP_GAUGE_ORDER.
Referenced by quda::cudaGaugeField::copy(), quda::cpuGaugeField::copy(), and quda::cudaGaugeField::saveCPUField().
◆ free_ghost_buffer()
| void quda::free_ghost_buffer | ( | void ** | buffer, |
| QudaGaugeFieldOrder | order, | ||
| QudaFieldGeometry | geometry | ||
| ) |
Definition at line 580 of file cuda_gauge_field.cu.
References d, and pool_device_free.
Referenced by quda::cudaGaugeField::copy(), quda::cpuGaugeField::copy(), and quda::cudaGaugeField::saveCPUField().
◆ gamma5()
| void quda::gamma5 | ( | ColorSpinorField & | out, |
| const ColorSpinorField & | in | ||
| ) |
Applies a gamma5 matrix to a spinor (wrapper to ApplyGamma)
- Parameters
-
[out] out Output field [in] in Input field
Definition at line 427 of file dslash_quda.cu.
References ApplyGamma(), in, and out.
Referenced by computeCloverForceQuda().


◆ gammaCPU()
| void quda::gammaCPU | ( | Arg | arg | ) |
Definition at line 195 of file dslash_quda.cu.
References arg(), in, and parity.

◆ gammaGPU()
| __global__ void quda::gammaGPU | ( | Arg | arg | ) |

◆ GaugeFixHit_AtomicAdd() [1/2]
| __forceinline__ __device__ void quda::GaugeFixHit_AtomicAdd | ( | Matrix< complex< Float >, NCOLORS > & | link, |
| const Float | relax_boost, | ||
| const int | tid | ||
| ) |
Device function to perform gauge fixing with overrelxation. Uses 8 treads per lattice site, the reduction is performed by shared memory without using atomicadd. This implementation needs 8x more shared memory than the implementation using atomicadd
Definition at line 69 of file gauge_fix_ovr_hit_devf.cuh.
References __syncthreads(), deg_tm_dslash_cuda_gen::block(), blockSize, p, x, and y.

◆ GaugeFixHit_AtomicAdd() [2/2]
| __forceinline__ __device__ void quda::GaugeFixHit_AtomicAdd | ( | Matrix< complex< Float >, NCOLORS > & | link, |
| Matrix< complex< Float >, NCOLORS > & | link1, | ||
| const Float | relax_boost, | ||
| const int | tid | ||
| ) |
Device function to perform gauge fixing with overrelxation. Uses 8 treads per lattice site, the reduction is performed by shared memory without using atomicadd. This implementation needs 8x more shared memory than the implementation using atomicadd
Definition at line 392 of file gauge_fix_ovr_hit_devf.cuh.
References __syncthreads(), deg_tm_dslash_cuda_gen::block(), blockSize, p, x, and y.

◆ GaugeFixHit_NoAtomicAdd() [1/2]
| __forceinline__ __device__ void quda::GaugeFixHit_NoAtomicAdd | ( | Matrix< complex< Float >, NCOLORS > & | link, |
| const Float | relax_boost, | ||
| const int | tid | ||
| ) |
Device function to perform gauge fixing with overrelxation. Uses 4 treads per lattice site, the reduction is performed by shared memory using atomicadd.
Definition at line 159 of file gauge_fix_ovr_hit_devf.cuh.
References __syncthreads(), fused_exterior_ndeg_tm_dslash_cuda_gen::a1, fused_exterior_ndeg_tm_dslash_cuda_gen::a2, deg_tm_dslash_cuda_gen::block(), blockSize, fused_exterior_ndeg_tm_dslash_cuda_gen::i, p, and x.

◆ GaugeFixHit_NoAtomicAdd() [2/2]
| __forceinline__ __device__ void quda::GaugeFixHit_NoAtomicAdd | ( | Matrix< complex< Float >, NCOLORS > & | link, |
| Matrix< complex< Float >, NCOLORS > & | link1, | ||
| const Float | relax_boost, | ||
| const int | tid | ||
| ) |
Device function to perform gauge fixing with overrelxation. Uses 4 treads per lattice site, the reduction is performed by shared memory using atomicadd.
Definition at line 486 of file gauge_fix_ovr_hit_devf.cuh.
References __syncthreads(), fused_exterior_ndeg_tm_dslash_cuda_gen::a1, fused_exterior_ndeg_tm_dslash_cuda_gen::a2, deg_tm_dslash_cuda_gen::block(), blockSize, fused_exterior_ndeg_tm_dslash_cuda_gen::i, p, and x.

◆ GaugeFixHit_NoAtomicAdd_LessSM() [1/2]
| __forceinline__ __device__ void quda::GaugeFixHit_NoAtomicAdd_LessSM | ( | Matrix< complex< Float >, NCOLORS > & | link, |
| const Float | relax_boost, | ||
| const int | tid | ||
| ) |
Device function to perform gauge fixing with overrelxation. Uses 8 treads per lattice site, the reduction is performed by shared memory without using atomicadd. This implementation uses the same amount of shared memory as the atomicadd implementation with more thread block synchronization
Definition at line 254 of file gauge_fix_ovr_hit_devf.cuh.
References __syncthreads(), deg_tm_dslash_cuda_gen::block(), blockSize, p, and x.

◆ GaugeFixHit_NoAtomicAdd_LessSM() [2/2]
| __forceinline__ __device__ void quda::GaugeFixHit_NoAtomicAdd_LessSM | ( | Matrix< complex< Float >, NCOLORS > & | link, |
| Matrix< complex< Float >, NCOLORS > & | link1, | ||
| const Float | relax_boost, | ||
| const int | tid | ||
| ) |
Device function to perform gauge fixing with overrelxation. Uses 4 treads per lattice site, the reduction is performed by shared memory without using atomicadd. This implementation uses the same amount of shared memory as the atomicadd implementation with more thread block synchronization
Definition at line 563 of file gauge_fix_ovr_hit_devf.cuh.
References __syncthreads(), deg_tm_dslash_cuda_gen::block(), blockSize, p, and x.

◆ gaugefixingFFT()
| void quda::gaugefixingFFT | ( | cudaGaugeField & | data, |
| const int | gauge_dir, | ||
| const int | Nsteps, | ||
| const int | verbose_interval, | ||
| const double | alpha, | ||
| const int | autotune, | ||
| const double | tolerance, | ||
| const int | stopWtheta | ||
| ) |
Gauge fixing with Steepest descent method with FFTs with support for single GPU only.
- Parameters
-
[in,out] data,quda gauge field [in] gauge_dir,3 for Coulomb gauge fixing, other for Landau gauge fixing [in] Nsteps,maximum number of steps to perform gauge fixing [in] verbose_interval,print gauge fixing info when iteration count is a multiple of this [in] alpha,gauge fixing parameter of the method, most common value is 0.08 [in] autotune,1 to autotune the method, i.e., if the Fg inverts its tendency we decrease the alpha value [in] tolerance,torelance value to stop the method, if this value is zero then the method stops when iteration reachs the maximum number of steps defined by Nsteps [in] stopWtheta,0 for MILC criterium and 1 to use the theta value
Definition at line 1202 of file gauge_fix_fft.cu.
References comm_dim_partitioned(), errorQuda, float, quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, QUDA_HALF_PRECISION, and QUDA_SINGLE_PRECISION.
Referenced by computeGaugeFixingFFTQuda(), and TEST_F().

◆ gaugefixingOVR()
| void quda::gaugefixingOVR | ( | cudaGaugeField & | data, |
| const int | gauge_dir, | ||
| const int | Nsteps, | ||
| const int | verbose_interval, | ||
| const double | relax_boost, | ||
| const double | tolerance, | ||
| const int | reunit_interval, | ||
| const int | stopWtheta | ||
| ) |
Gauge fixing with overrelaxation with support for single and multi GPU.
- Parameters
-
[in,out] data,quda gauge field [in] gauge_dir,3 for Coulomb gauge fixing, other for Landau gauge fixing [in] Nsteps,maximum number of steps to perform gauge fixing [in] verbose_interval,print gauge fixing info when iteration count is a multiple of this [in] relax_boost,gauge fixing parameter of the overrelaxation method, most common value is 1.5 or 1.7. [in] tolerance,torelance value to stop the method, if this value is zero then the method stops when iteration reachs the maximum number of steps defined by Nsteps [in] reunit_interval,reunitarize gauge field when iteration count is a multiple of this [in] stopWtheta,0 for MILC criterium and 1 to use the theta value
Definition at line 1790 of file gauge_fix_ovr.cu.
References errorQuda, float, quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, QUDA_HALF_PRECISION, and QUDA_SINGLE_PRECISION.
Referenced by computeGaugeFixingOVRQuda(), and TEST_F().

◆ gaugeForce()
| void quda::gaugeForce | ( | GaugeField & | mom, |
| const GaugeField & | u, | ||
| double | coeff, | ||
| int *** | input_path, | ||
| int * | length, | ||
| double * | path_coeff, | ||
| int | num_paths, | ||
| int | max_length | ||
| ) |
Compute the gauge-force contribution to the momentum.
- Parameters
-
[out] mom Momentum field [in] u Gauge field (extended when running no multiple GPUs) [in] coeff Step-size coefficient [in] input_path Host-array holding all path contributions for the gauge action [in] length Host array holding the length of all paths [in] path_coeff Coefficient of each path [in] num_paths Numer of paths [in] max_length Maximum length of each path
Definition at line 339 of file gauge_force.cu.
References dw_dslash_4D_cuda_gen::coeff(), errorQuda, length, quda::LatticeField::Location(), quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, and QUDA_SINGLE_PRECISION.
Referenced by computeGaugeForceQuda().

◆ gaugeGauss()
| void quda::gaugeGauss | ( | GaugeField & | dataDs, |
| RNG & | rngstate | ||
| ) |
Generate Gaussian distributed GaugeField
- Parameters
-
dataDs The GaugeField rngstate random states
Definition at line 182 of file gauge_random.cu.
References errorQuda, quda::GaugeField::isNative(), quda::GaugeField::Order(), quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, QUDA_HALF_PRECISION, QUDA_SINGLE_PRECISION, and quda::GaugeField::Reconstruct().
Referenced by gaussGaugeQuda().

◆ gaussSpinor() [1/3]
| void quda::gaussSpinor | ( | InOrder & | inOrder, |
| int | volume, | ||
| RNG | rngstate | ||
| ) |
CPU function to reorder spinor fields.
Definition at line 32 of file spinor_gauss.cu.
References c, s, quda::RNG::State(), and x.

◆ gaussSpinor() [2/3]
| void quda::gaussSpinor | ( | InOrder & | inOrder, |
| const ColorSpinorField & | meta, | ||
| RNG & | rngstate | ||
| ) |
Definition at line 103 of file spinor_gauss.cu.
References quda::GaussSpinor< FloatIn, Ns, Nc, InOrder >::apply().
◆ gaussSpinor() [3/3]
| void quda::gaussSpinor | ( | ColorSpinorField & | in, |
| RNG & | rngstate | ||
| ) |
Decide on the input order
Definition at line 110 of file spinor_gauss.cu.
References errorQuda, in, QUDA_FLOAT2_FIELD_ORDER, and QUDA_SPACE_SPIN_COLOR_FIELD_ORDER.
◆ gaussSpinorKernel()
| __global__ void quda::gaussSpinorKernel | ( | InOrder | inOrder, |
| int | volume, | ||
| RNG | rngstate | ||
| ) |
CUDA kernel to reorder spinor fields. Adopts a similar form as the CPU version, using the same inlined functions.
Definition at line 47 of file spinor_gauss.cu.
References blockDim, c, s, quda::RNG::State(), and x.

◆ genericCompare()
| int quda::genericCompare | ( | const cpuColorSpinorField & | a, |
| const cpuColorSpinorField & | b, | ||
| int | tol | ||
| ) |
Definition at line 204 of file color_spinor_util.cu.
References a, b, compareSpinor(), errorQuda, ret, and tol.
Referenced by quda::cpuColorSpinorField::Compare().

◆ genericCopyColorSpinor() [1/6]
| void quda::genericCopyColorSpinor | ( | OutOrder & | outOrder, |
| const InOrder & | inOrder, | ||
| const ColorSpinorField & | out, | ||
| QudaFieldLocation | location | ||
| ) |

◆ genericCopyColorSpinor() [2/6]
| void quda::genericCopyColorSpinor | ( | InOrder & | inOrder, |
| ColorSpinorField & | out, | ||
| QudaFieldLocation | location, | ||
| FloatOut * | Out | ||
| ) |
Decide on the output order
Definition at line 92 of file copy_color_spinor_mg.cuh.
References errorQuda, out, QUDA_FLOAT2_FIELD_ORDER, and QUDA_SPACE_SPIN_COLOR_FIELD_ORDER.
◆ genericCopyColorSpinor() [3/6]
| void quda::genericCopyColorSpinor | ( | ColorSpinorField & | out, |
| const ColorSpinorField & | in, | ||
| QudaFieldLocation | location, | ||
| FloatOut * | Out, | ||
| FloatIn * | In | ||
| ) |
Decide on the input order
Definition at line 111 of file copy_color_spinor_mg.cuh.
References errorQuda, in, out, QUDA_FLOAT2_FIELD_ORDER, and QUDA_SPACE_SPIN_COLOR_FIELD_ORDER.
◆ genericCopyColorSpinor() [4/6]
| void quda::genericCopyColorSpinor | ( | Out & | outOrder, |
| const In & | inOrder, | ||
| const ColorSpinorField & | out, | ||
| const ColorSpinorField & | in, | ||
| QudaFieldLocation | location | ||
| ) |

◆ genericCopyColorSpinor() [5/6]
| void quda::genericCopyColorSpinor | ( | InOrder & | inOrder, |
| ColorSpinorField & | out, | ||
| const ColorSpinorField & | in, | ||
| QudaFieldLocation | location, | ||
| FloatOut * | Out, | ||
| float * | outNorm | ||
| ) |
Decide on the output order
Definition at line 280 of file copy_color_spinor.cuh.
References errorQuda, in, out, QUDA_FLOAT2_FIELD_ORDER, QUDA_PADDED_SPACE_SPIN_COLOR_FIELD_ORDER, QUDA_QDPJIT_FIELD_ORDER, QUDA_SPACE_COLOR_SPIN_FIELD_ORDER, and QUDA_SPACE_SPIN_COLOR_FIELD_ORDER.
◆ genericCopyColorSpinor() [6/6]
| void quda::genericCopyColorSpinor | ( | ColorSpinorField & | out, |
| const ColorSpinorField & | in, | ||
| QudaFieldLocation | location, | ||
| FloatOut * | Out, | ||
| FloatIn * | In, | ||
| float * | outNorm, | ||
| float * | inNorm | ||
| ) |
Decide on the input order
Definition at line 331 of file copy_color_spinor.cuh.
References errorQuda, in, out, QUDA_FLOAT2_FIELD_ORDER, QUDA_PADDED_SPACE_SPIN_COLOR_FIELD_ORDER, QUDA_QDPJIT_FIELD_ORDER, QUDA_SPACE_COLOR_SPIN_FIELD_ORDER, and QUDA_SPACE_SPIN_COLOR_FIELD_ORDER.
◆ GenericPackGhost()
| void quda::GenericPackGhost | ( | Arg & | arg | ) |
Definition at line 81 of file color_spinor_pack.cu.
References arg(), fused_exterior_ndeg_tm_dslash_cuda_gen::i, and parity.

◆ genericPackGhost()
|
inline |
Generic ghost packing routine.
- Parameters
-
[out] ghost Array of packed ghosts with array ordering [2*dim+dir] [in] a Input field that is being packed [in] parity Which parity are we packing [in] dagger Is for a dagger operator (presently ignored) [in[ location Array specifiying the memory location of each resulting ghost [2*dim+dir]
Definition at line 163 of file color_spinor_pack.cu.
References a, quda::GenericPackGhostLauncher< Float, Ns, Ms, Nc, Mc, Arg >::apply(), arg(), deg_tm_dslash_cuda_gen::dagger, and parity.
Referenced by quda::cudaColorSpinorField::exchangeGhost(), and quda::cpuColorSpinorField::packGhost().

◆ GenericPackGhostKernel()
| __global__ void quda::GenericPackGhostKernel | ( | Arg | arg | ) |
Definition at line 93 of file color_spinor_pack.cu.
References arg(), blockDim, and parity.

◆ genericPrintVector()
| void quda::genericPrintVector | ( | cpuColorSpinorField & | a, |
| unsigned int | x | ||
| ) |
Definition at line 285 of file color_spinor_util.cu.
References a, errorQuda, print_vector(), and x.
Referenced by quda::cpuColorSpinorField::PrintVector().


◆ genericSource()
| void quda::genericSource | ( | cpuColorSpinorField & | a, |
| QudaSourceType | sourceType, | ||
| int | x, | ||
| int | s, | ||
| int | c | ||
| ) |
Definition at line 76 of file color_spinor_util.cu.
References a, c, constant(), errorQuda, point(), QUDA_CONSTANT_SOURCE, QUDA_POINT_SOURCE, QUDA_RANDOM_SOURCE, QUDA_SINUSOIDAL_SOURCE, random(), s, sin(), and x.
Referenced by quda::cpuColorSpinorField::Source().

◆ genGauss()
| __device__ __host__ void quda::genGauss | ( | InOrder & | inOrder, |
| cuRNGState & | localState, | ||
| int | x, | ||
| int | s, | ||
| int | c | ||
| ) |
◆ GetBlockDim()
Definition at line 18 of file random.cu.
References BLOCKSDIVUP, and size.
Referenced by launch_kernel_random().

◆ getCoords()
|
inlinestatic |
Compute the 4-d spatial index from the checkerboarded 1-d index at parity parity
- Parameters
-
x Computed spatial index cb_index 1-d checkerboarded index X Full lattice dimensions parity Site parity
Definition at line 129 of file index_helper.cuh.
References parity, X, x, za, and zb.
Referenced by applyLaplace(), completeKSForceCore(), computeCoarseClover(), computeNeighborSum(), computeOvrImpSTOUTStep(), computeStapleRectangle(), computeUV(), computeVUV(), computeYhat(), quda::colorspinor::PaddedSpaceSpinorColorOrder< Float, Ns, Nc >::getPaddedIndex(), quda::gauge::TIFRPaddedOrder< Float, length >::getPaddedIndex(), kernel_random(), packGhost(), and sin().
◆ getCoords5()
|
inlinestatic |
Compute the 4-d spatial index from the checkerboarded 1-d index at parity parity
- Parameters
-
x Computed spatial index cb_index 1-d checkerboarded index X Full lattice dimensions parity Site parity
Definition at line 181 of file index_helper.cuh.
References parity, QUDA_5D_PC, X, x, za, and zb.
Referenced by packGhost().

◆ getCoordsExtended()
◆ getDeterminant()
|
inline |
Definition at line 312 of file quda_matrix.h.
References a.
Referenced by computeLinkInverse(), computeMatrixInverse(), exponentiate_iQ(), quda::gauge::Reconstruct< 13, Float >::getPhase(), quda::gauge::Reconstruct< 9, Float >::getPhase(), and polarSu3().
◆ getDslashLaunch()
| bool quda::getDslashLaunch | ( | ) |
◆ getIndexFull()
|
inlinestatic |
Compute the 1-d global index from 1-d checkerboard index and parity. This should never be used to index into QUDA fields due to the potential of padding between even and odd regions.
- Parameters
-
cb_index 1-d checkerboard index X lattice dimensions parity Site parity
Definition at line 211 of file index_helper.cuh.
◆ getKernelPackT()
| bool quda::getKernelPackT | ( | ) |
- Returns
- Whether the T dimension is kernel packed or not
Definition at line 61 of file dslash_quda.cu.
References kernelPackT.
Referenced by anonymous_namespace{dslash_policy.cuh}::DslashPolicyTune::apply(), anonymous_namespace{dslash_policy.cuh}::DslashPolicyTune::DslashPolicyTune(), quda::cudaColorSpinorField::exchangeGhost(), anonymous_namespace{dslash_policy.cuh}::issueGather(), anonymous_namespace{dslash_policy.cuh}::issuePack(), anonymous_namespace{dslash_policy.cuh}::DslashBasic::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashPthreads::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashFusedExterior::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashGDRRecv::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashFusedGDRRecv::operator()(), quda::cudaColorSpinorField::sendGhost(), quda::cudaColorSpinorField::sendStart(), and DslashCuda::setParam().
◆ getLinkDeterminant()
| double2 quda::getLinkDeterminant | ( | cudaGaugeField & | data | ) |
Calculate the Determinant.
- Parameters
-
[in] data Gauge field
- Returns
- double2 complex Determinant value
Definition at line 193 of file pgauge_det_trace.cu.
References errorQuda, quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, and QUDA_SINGLE_PRECISION.
Referenced by GaugeAlgTest::TearDown(), and TEST_F().

◆ getLinkTrace()
| double2 quda::getLinkTrace | ( | cudaGaugeField & | data | ) |
Calculate the Trace.
- Parameters
-
[in] data Gauge field
- Returns
- double2 complex trace value
Definition at line 214 of file pgauge_det_trace.cu.
References errorQuda, quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, and QUDA_SINGLE_PRECISION.
Referenced by GaugeAlgTest::TearDown().


◆ getRealTraceUVdagger()

◆ getSubTraceUnit()
|
inline |
Definition at line 1005 of file quda_matrix.h.
References a.
◆ getTrace()
|
inline |
Definition at line 305 of file quda_matrix.h.
References a.
Referenced by completeKSForceCore(), computeOvrImpSTOUTStep(), and exponentiate_iQ().

◆ getTuneCache()
| const map & quda::getTuneCache | ( | ) |
Definition at line 110 of file tune.cpp.
References tunecache.
Referenced by quda::DslashCoarsePolicyTune::DslashCoarsePolicyTune(), anonymous_namespace{dslash_policy.cuh}::DslashPolicyTune::DslashPolicyTune(), and quda::blas::TileSizeTune< ReducerDiagonal, writeDiagonal, ReducerOffDiagonal, writeOffDiagonal >::TileSizeTune().
◆ ghostFaceIndex()
|
inline |
Compute the checkerboarded index into the ghost field corresponding to full (local) site index x[]
- Parameters
-
x local site X local lattice dimensions dim dimension depth of ghost
Definition at line 230 of file index_helper.cuh.
References dim, index(), X, and x.

◆ host_allocated_peak()
| long quda::host_allocated_peak | ( | ) |
- Returns
- peak host memory allocated
Definition at line 63 of file malloc.cpp.
References HOST, and max_total_bytes.
◆ host_free_()
| void quda::host_free_ | ( | const char * | func, |
| const char * | file, | ||
| int | line, | ||
| void * | ptr | ||
| ) |
Free host memory allocated with safe_malloc(), pinned_malloc(), or mapped_malloc(). This function should only be called via the host_free() macro, defined in malloc_quda.h
Definition at line 340 of file malloc.cpp.
References alloc, count, err, errorQuda, free(), func, HOST, MAPPED, PINNED, print_trace(), printfQuda, ptr, and track_free().
Referenced by quda::pool::pinned_free_().

◆ i32toa()
|
inline |
Definition at line 117 of file uint_to_char.h.
References u32toa(), and value.

◆ i64toa()
|
inline |
Definition at line 284 of file uint_to_char.h.
References u64toa(), and value.

◆ improvedStaggeredDslashCuda()
| void quda::improvedStaggeredDslashCuda | ( | cudaColorSpinorField * | out, |
| const cudaGaugeField & | fatGauge, | ||
| const cudaGaugeField & | longGauge, | ||
| const cudaColorSpinorField * | in, | ||
| const int | parity, | ||
| const int | dagger, | ||
| const cudaColorSpinorField * | x, | ||
| const double & | k, | ||
| const int * | commDim, | ||
| TimeProfile & | profile | ||
| ) |
Definition at line 272 of file dslash_improved_staggered.cu.
References deg_tm_dslash_cuda_gen::dagger, deg_tm_dslash_cuda_gen::dslash, errorQuda, fused_exterior_ndeg_tm_dslash_cuda_gen::i, in, out, parity, QUDA_DOUBLE_PRECISION, QUDA_HALF_PRECISION, QUDA_MAX_DIM, QUDA_SINGLE_PRECISION, and x.
Referenced by quda::DiracImprovedStaggered::Dslash(), and quda::DiracImprovedStaggered::DslashXpay().
◆ IndexBlock()
|
inlinestatic |
Retrieve the SU(N) indices for the current block number
- Parameters
-
[in] block,current block number, from 0 to (NCOLORS * (NCOLORS - 1) / 2) [out] p,row index pointing to the SU(N) matrix [out] q,column index pointing to the SU(N) matrix
Definition at line 36 of file gauge_fix_ovr_hit_devf.cuh.
References deg_tm_dslash_cuda_gen::block(), index(), and p.

◆ InitGaugeField() [1/2]
| void quda::InitGaugeField | ( | cudaGaugeField & | data | ) |
Perform a cold start to the gauge field, identity SU(3) matrix, also fills the ghost links in multi-GPU case (no need to exchange data)
- Parameters
-
[in,out] data Gauge field
Referenced by main(), and GaugeAlgTest::SetUp().
◆ InitGaugeField() [2/2]
| void quda::InitGaugeField | ( | cudaGaugeField & | data, |
| RNG & | rngstate | ||
| ) |
Perform a hot start to the gauge field, random SU(3) matrix, followed by reunitarization, also exchange borders links in multi-GPU case.
- Parameters
-
[in,out] data Gauge field [in,out] rngstate state of the CURAND random number generator
Definition at line 459 of file pgauge_init.cu.
References errorQuda, quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, and QUDA_SINGLE_PRECISION.

◆ injector()

◆ isUnitary() [1/2]
| bool quda::isUnitary | ( | const cpuGaugeField & | field, |
| double | max_error | ||
| ) |

◆ isUnitary() [2/2]
| __device__ __host__ bool quda::isUnitary | ( | const Matrix< Cmplx, 3 > & | matrix, |
| double | max_error | ||
| ) |
Definition at line 1054 of file quda_matrix.h.
References conj(), fabs(), fused_exterior_ndeg_tm_dslash_cuda_gen::i, x, and y.
◆ kernel_random() [1/2]
| __global__ void quda::kernel_random | ( | cuRNGState * | state, |
| int | seed, | ||
| int | rng_size, | ||
| int | node_offset | ||
| ) |
CUDA kernel to initialize CURAND RNG states.
- Parameters
-
state CURAND RNG state array seed initial seed for RNG rng_size size of the CURAND RNG state array node_offset this parameter is used to skip ahead the index in the sequence, usefull for multigpu.
Definition at line 45 of file random.cu.
References blockDim.
◆ kernel_random() [2/2]
| __global__ void quda::kernel_random | ( | cuRNGState * | state, |
| int | seed, | ||
| int | rng_size, | ||
| int | node_offset, | ||
| rngArg | arg | ||
| ) |
Definition at line 61 of file random.cu.
References arg(), blockDim, getCoords(), fused_exterior_ndeg_tm_dslash_cuda_gen::i, and x.

◆ laplace()
|
inline |
Definition at line 113 of file laplace.cu.
References arg(), out, parity, and x.
Referenced by ApplyLaplace(), quda::GaugeLaplace::operator=(), and quda::GaugeLaplacePC::operator=().

◆ laplaceCPU()
| void quda::laplaceCPU | ( | Arg | arg | ) |
Definition at line 129 of file laplace.cu.
References arg(), for(), and parity.
◆ laplaceGPU()
| __global__ void quda::laplaceGPU | ( | Arg | arg | ) |
◆ launch_kernel_random()
| void quda::launch_kernel_random | ( | cuRNGState * | state, |
| int | seed, | ||
| int | rng_size, | ||
| int | node_offset, | ||
| int | X[4] | ||
| ) |
Call CUDA kernel to initialize CURAND RNG states.
- Parameters
-
state CURAND RNG state array seed initial seed for RNG rng_size size of the CURAND RNG state array node_offset this parameter is used to skip ahead the index in the sequence, usefull for multigpu.
Definition at line 85 of file random.cu.
References arg(), comm_coord(), comm_dim(), GetBlockDim(), fused_exterior_ndeg_tm_dslash_cuda_gen::i, qudaDeviceSynchronize(), and X.
Referenced by quda::RNG::Init().
◆ linkIndex() [1/2]
|
inlinestatic |
Compute the checkerboard 1-d index from the 4-d coordinate x[]
- Returns
- 1-d checkerboard index
- Parameters
-
x 4-d lattice index X Full lattice dimensions
Definition at line 46 of file index_helper.cuh.
Referenced by quda::colorspinor::PaddedSpaceSpinorColorOrder< Float, Ns, Nc >::getPaddedIndex(), and quda::gauge::TIFRPaddedOrder< Float, length >::getPaddedIndex().
◆ linkIndex() [2/2]
◆ linkIndexM1()
|
inlinestatic |
Compute the checkerboard 1-d index from the 4-d coordinate x[] -1 in the mu direction
- Returns
- 1-d checkerboard index
- Parameters
-
x 4-d lattice index X Full lattice dimensions mu direction in which to subtract 1
Definition at line 75 of file index_helper.cuh.
References fused_exterior_ndeg_tm_dslash_cuda_gen::i, idx, mu, X, x, and y.
Referenced by applyLaplace(), computeNeighborSum(), and computeYhat().
◆ linkIndexP1()
|
inlinestatic |
Compute the checkerboard 1-d index from the 4-d coordinate x[] +1 in the mu direction
- Returns
- 1-d checkerboard index
- Parameters
-
x 4-d lattice index X Full lattice dimensions mu direction in which to add 1
Definition at line 111 of file index_helper.cuh.
References fused_exterior_ndeg_tm_dslash_cuda_gen::i, idx, mu, X, x, and y.
Referenced by applyLaplace(), computeNeighborSum(), and computeUV().
◆ linkIndexShift() [1/2]
|
inlinestatic |
Compute the checkerboard 1-d index from the 4-d coordinate x[] + dx[]
- Returns
- 1-d checkerboard index
- Parameters
-
x 4-d lattice index dx 4-d shift index X Full lattice dimensions
Definition at line 13 of file index_helper.cuh.
References fused_exterior_ndeg_tm_dslash_cuda_gen::i, idx, X, x, and y.
Referenced by completeKSForceCore(), computeOvrImpSTOUTStep(), and computeStapleRectangle().

◆ linkIndexShift() [2/2]
|
inlinestatic |
Compute the checkerboard 1-d index from the 4-d coordinate x[] + dx[]
- Returns
- 1-d checkerboard index
- Parameters
-
y new 4-d lattice index x original 4-d lattice index dx 4-d shift index X Full lattice dimensions
Definition at line 31 of file index_helper.cuh.
References fused_exterior_ndeg_tm_dslash_cuda_gen::i, idx, X, x, and y.
◆ linkNormalIndexP1()
|
inlinestatic |
Compute the full 1-d index from the 4-d coordinate x[] +1 in the mu direction
- Returns
- 1-d checkerboard index
- Parameters
-
x 4-d lattice index X Full lattice dimensions mu direction in which to add 1
Definition at line 93 of file index_helper.cuh.
References fused_exterior_ndeg_tm_dslash_cuda_gen::i, idx, mu, X, x, and y.
◆ load_global_float4()
|
inline |
◆ load_streaming_double2()
|
inline |
◆ load_streaming_float4()
|
inline |
◆ loadLinkVariableFromArray() [1/2]
|
inline |
Definition at line 747 of file quda_matrix.h.
References array, quda::Matrix< T, N >::data, fused_exterior_ndeg_tm_dslash_cuda_gen::i, and idx.
◆ loadLinkVariableFromArray() [2/2]
|
inline |
Definition at line 769 of file quda_matrix.h.
References array, fused_exterior_ndeg_tm_dslash_cuda_gen::i, and idx.
◆ loadMatrixFromArray()
|
inline |
Definition at line 759 of file quda_matrix.h.
References array, fused_exterior_ndeg_tm_dslash_cuda_gen::i, idx, and mat().
◆ loadMomentumFromArray()
|
inline |
Definition at line 845 of file quda_matrix.h.
References array, quda::Matrix< T, N >::data, and idx.
◆ loadTuneCache()
| void quda::loadTuneCache | ( | ) |
Definition at line 302 of file tune.cpp.
References broadcastTuneCache(), comm_rank(), deserializeTuneCache(), errorQuda, getenv(), getline(), getTuning(), getVerbosity(), gitversion, initial_cache_size, printfQuda, quda_hash, QUDA_SUMMARIZE, QUDA_TUNE_NO, quda_version, resource_path, tunecache, and warningQuda.
Referenced by initQudaMemory().
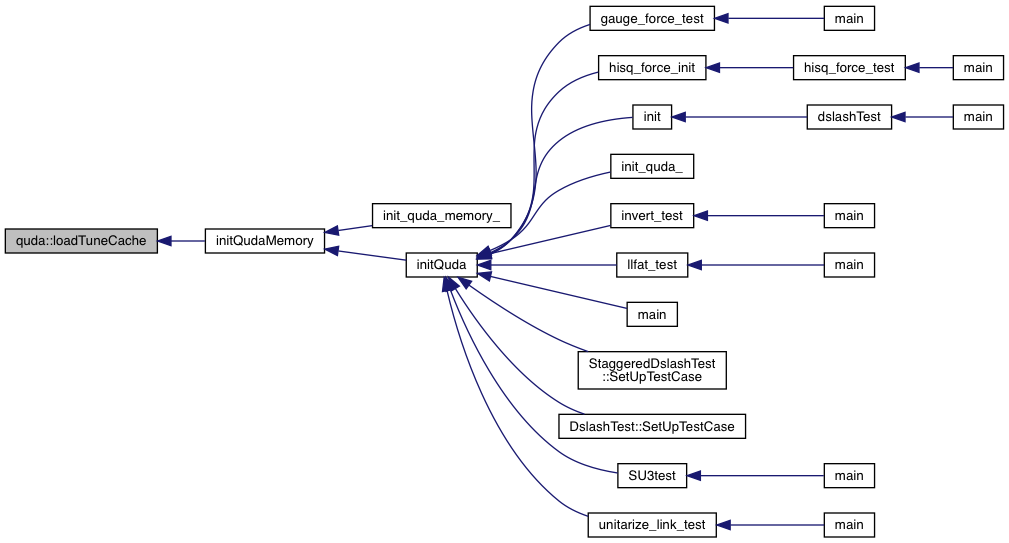
◆ Location_() [1/2]
|
inline |
Helper function for determining if the location of the fields is the same.
- Parameters
-
[in] a Input field [in] b Input field
- Returns
- If location is unique return the location
Definition at line 539 of file lattice_field.h.
References a, b, errorQuda, func, and QUDA_INVALID_FIELD_LOCATION.
Referenced by Location_().

◆ Location_() [2/2]
|
inline |
Helper function for determining if the location of the fields is the same.
- Parameters
-
[in] a Input field [in] b Input field [in] args List of additional fields to check location on
- Returns
- If location is unique return the location
Definition at line 556 of file lattice_field.h.
References a, args, b, func, and Location_().

◆ log() [1/3]
|
inline |
◆ log() [2/3]
|
inline |

◆ log() [3/3]
◆ log10() [1/2]
|
inline |

◆ log10() [2/2]
|
inline |
Definition at line 979 of file complex_quda.h.
Referenced by log10().


◆ make_Complex() [1/2]
|
inline |
Definition at line 278 of file float_vector.h.
References a.
Referenced by genericBlas(), genericMultiBlas(), and genericReduce().
◆ make_Complex() [2/2]
|
inline |
Definition at line 279 of file float_vector.h.
References a.
◆ make_Float2() [1/9]
|
inline |
Definition at line 257 of file float_vector.h.
◆ make_Float2() [2/9]
|
inline |
Definition at line 260 of file float_vector.h.
References a.
◆ make_Float2() [3/9]
|
inline |
Definition at line 262 of file float_vector.h.
References a.
◆ make_Float2() [4/9]
|
inline |
Definition at line 264 of file float_vector.h.
References a.
◆ make_Float2() [5/9]
|
inline |
Definition at line 266 of file float_vector.h.
References a.
◆ make_Float2() [6/9]
|
inline |
Definition at line 269 of file float_vector.h.
References a.
◆ make_Float2() [7/9]
|
inline |
Definition at line 271 of file float_vector.h.
References a.
◆ make_Float2() [8/9]
|
inline |
Definition at line 273 of file float_vector.h.
References a.
◆ make_Float2() [9/9]
|
inline |
Definition at line 275 of file float_vector.h.
References a.
◆ make_FloatN() [1/4]
| __forceinline__ __host__ __device__ float2 quda::make_FloatN | ( | const double2 & | a | ) |
Definition at line 222 of file float_vector.h.
References a.
◆ make_FloatN() [2/4]
| __forceinline__ __host__ __device__ float4 quda::make_FloatN | ( | const double4 & | a | ) |
Definition at line 226 of file float_vector.h.
References a.
◆ make_FloatN() [3/4]
| __forceinline__ __host__ __device__ double2 quda::make_FloatN | ( | const float2 & | a | ) |
Definition at line 230 of file float_vector.h.
References a.
◆ make_FloatN() [4/4]
| __forceinline__ __host__ __device__ double4 quda::make_FloatN | ( | const float4 & | a | ) |
Definition at line 234 of file float_vector.h.
References a.
◆ make_shortN() [1/4]
| __forceinline__ __host__ __device__ short4 quda::make_shortN | ( | const float4 & | a | ) |
Definition at line 238 of file float_vector.h.
References a.
◆ make_shortN() [2/4]
| __forceinline__ __host__ __device__ short2 quda::make_shortN | ( | const float2 & | a | ) |
Definition at line 242 of file float_vector.h.
References a.
◆ make_shortN() [3/4]
| __forceinline__ __host__ __device__ short4 quda::make_shortN | ( | const double4 & | a | ) |
Definition at line 246 of file float_vector.h.
References a.
◆ make_shortN() [4/4]
| __forceinline__ __host__ __device__ short2 quda::make_shortN | ( | const double2 & | a | ) |
Definition at line 250 of file float_vector.h.
References a.
◆ makeAntiHerm()
|
inline |
Definition at line 636 of file quda_matrix.h.
References conj(), and fused_exterior_ndeg_tm_dslash_cuda_gen::i.

◆ mapped_allocated_peak()
| long quda::mapped_allocated_peak | ( | ) |
- Returns
- peak mapped memory allocated
Definition at line 61 of file malloc.cpp.
References MAPPED, and max_total_bytes.
◆ mapped_malloc_()
Allocate page-locked ("pinned") host memory, and map it into the GPU address space. This function should only be called via the mapped_malloc() macro, defined in malloc_quda.h
Definition at line 269 of file malloc.cpp.
References a, aligned_malloc(), err, errorQuda, func, MAPPED, memset(), printfQuda, ptr, size, and track_malloc().
◆ massRescale()
| void quda::massRescale | ( | cudaColorSpinorField & | b, |
| QudaInvertParam & | param | ||
| ) |
Definition at line 1532 of file interface_quda.cpp.
References quda::blas::ax(), b, errorQuda, getVerbosity(), fused_exterior_ndeg_tm_dslash_cuda_gen::i, if(), kappa, kappa5, quda::blas::norm2(), param, pow(), printfQuda, QUDA_ASQTAD_DSLASH, QUDA_ASYMMETRIC_MASS_NORMALIZATION, QUDA_DEBUG_VERBOSE, QUDA_DOMAIN_WALL_4D_DSLASH, QUDA_DOMAIN_WALL_DSLASH, QUDA_KAPPA_NORMALIZATION, QUDA_MASS_NORMALIZATION, QUDA_MAT_SOLUTION, QUDA_MATDAG_MAT_SOLUTION, QUDA_MATPC_SOLUTION, QUDA_MATPCDAG_MATPC_SOLUTION, QUDA_MOBIUS_DWF_DSLASH, QUDA_STAGGERED_DSLASH, and unscaled_shifts.
Referenced by invertMultiShiftQuda(), invertMultiSrcQuda(), and invertQuda().
◆ max_fabs() [1/4]
| __forceinline__ __host__ __device__ float quda::max_fabs | ( | const float4 & | c | ) |
Definition at line 198 of file float_vector.h.
References a, b, c, fabsf(), and fmaxf().
Referenced by store_norm().

◆ max_fabs() [2/4]
| __forceinline__ __host__ __device__ float quda::max_fabs | ( | const float2 & | b | ) |
Definition at line 204 of file float_vector.h.
References b, fabsf(), and fmaxf().
◆ max_fabs() [3/4]
| __forceinline__ __host__ __device__ double quda::max_fabs | ( | const double4 & | c | ) |
◆ max_fabs() [4/4]
| __forceinline__ __host__ __device__ double quda::max_fabs | ( | const double2 & | b | ) |
Definition at line 214 of file float_vector.h.
References b, fabs(), and fmax().
◆ maxGauge() [1/2]
| double quda::maxGauge | ( | const Order | order, |
| int | volume, | ||
| int | nDim | ||
| ) |
Generic CPU function find the gauge maximum
Definition at line 11 of file max_gauge.cu.
References abs(), d, fused_exterior_ndeg_tm_dslash_cuda_gen::i, parity, and x.

◆ maxGauge() [2/2]
| double quda::maxGauge | ( | const GaugeField & | u | ) |
This function is used to calculate the maximum absolute value of a gauge field array. Defined in max_gauge.cu.
- Parameters
-
[in] u The gauge field from which we want to compute the max
Definition at line 31 of file max_gauge.cu.
References errorQuda, quda::GaugeField::Gauge_p(), quda::GaugeField::Ncolor(), quda::GaugeField::Order(), QUDA_BQCD_GAUGE_ORDER, QUDA_CPS_WILSON_GAUGE_ORDER, QUDA_MILC_GAUGE_ORDER, QUDA_QDP_GAUGE_ORDER, QUDA_TIFR_GAUGE_ORDER, and reduceMaxDouble().
Referenced by quda::cpuGaugeField::cpuGaugeField().

◆ MDWFDslashCuda()
| void quda::MDWFDslashCuda | ( | cudaColorSpinorField * | out, |
| const cudaGaugeField & | gauge, | ||
| const cudaColorSpinorField * | in, | ||
| const int | parity, | ||
| const int | dagger, | ||
| const cudaColorSpinorField * | x, | ||
| const double & | m_f, | ||
| const double & | k, | ||
| const double * | b5, | ||
| const double * | c_5, | ||
| const double & | m5, | ||
| const int * | commDim, | ||
| const int | DS_type, | ||
| TimeProfile & | profile | ||
| ) |
Definition at line 273 of file dslash_mobius.cu.
References deg_tm_dslash_cuda_gen::dagger, deg_tm_dslash_cuda_gen::dslash, errorQuda, fused_exterior_ndeg_tm_dslash_cuda_gen::i, in, m5, out, parity, QUDA_DOUBLE_PRECISION, QUDA_HALF_PRECISION, QUDA_MAX_DIM, QUDA_SINGLE_PRECISION, and x.
Referenced by quda::DiracMobius::Dslash4(), quda::DiracMobius::Dslash4pre(), quda::DiracMobius::Dslash4preXpay(), quda::DiracMobius::Dslash4Xpay(), quda::DiracMobius::Dslash5(), quda::DiracMobiusPC::Dslash5inv(), quda::DiracMobiusPC::Dslash5invXpay(), and quda::DiracMobius::Dslash5Xpay().
◆ Monte()
| void quda::Monte | ( | cudaGaugeField & | data, |
| RNG & | rngstate, | ||
| double | Beta, | ||
| int | nhb, | ||
| int | nover | ||
| ) |
Perform heatbath and overrelaxation. Performs nhb heatbath steps followed by nover overrelaxation steps.
- Parameters
-
[in,out] data Gauge field [in,out] rngstate state of the CURAND random number generator [in] Beta inverse of the gauge coupling, beta = 2 Nc / g_0^2 [in] nhb number of heatbath steps [in] nover number of overrelaxation steps
Definition at line 857 of file pgauge_heatbath.cu.
References errorQuda, float, quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, and QUDA_SINGLE_PRECISION.
Referenced by main(), and GaugeAlgTest::SetUp().

◆ multiplyVUV()
|
inline |
Do a single (AV)^ * UV product, where for preconditioned clover, AV correspond to the clover inverse multiplied by the packed null space vectors, else AV is simply the packed null space vectors.
- Parameters
-
[out] vuv Result array [in,out] arg Arg storing the fields and parameters [in] Fine grid parity we're working on [in] x_cb Checkboarded x dimension
Definition at line 494 of file coarse_op.cuh.
References arg(), conj(), gamma(), fused_exterior_ndeg_tm_dslash_cuda_gen::i, parity, QUDA_BACKWARDS, and s.
◆ ndegTwistedMassDslashCuda()
| void quda::ndegTwistedMassDslashCuda | ( | cudaColorSpinorField * | out, |
| const cudaGaugeField & | gauge, | ||
| const cudaColorSpinorField * | in, | ||
| const int | parity, | ||
| const int | dagger, | ||
| const cudaColorSpinorField * | x, | ||
| const QudaTwistDslashType | type, | ||
| const double & | kappa, | ||
| const double & | mu, | ||
| const double & | epsilon, | ||
| const double & | k, | ||
| const int * | commDim, | ||
| TimeProfile & | profile | ||
| ) |
Definition at line 144 of file dslash_ndeg_twisted_mass.cu.
References deg_tm_dslash_cuda_gen::dagger, deg_tm_dslash_cuda_gen::dslash, errorQuda, fused_exterior_ndeg_tm_dslash_cuda_gen::i, in, kappa, mu, out, parity, QUDA_DOUBLE_PRECISION, QUDA_HALF_PRECISION, QUDA_SINGLE_PRECISION, and x.
Referenced by quda::DiracTwistedMass::NdegTwistedDslash(), and quda::DiracTwistedMass::NdegTwistedDslashXpay().
◆ neighborIndex()
| __device__ __forceinline__ int quda::neighborIndex | ( | const unsigned int & | cb_idx, |
| const int(&) | shift[4], | ||
| const bool(&) | partitioned[4], | ||
| const unsigned int & | parity | ||
| ) |
Definition at line 41 of file shift_quark_field.cu.
References coordsFromIndex(), full_idx, idx, parity, shift, t, x, y, and z.
Referenced by gaugeLink(), shiftColorSpinorFieldKernel(), and spinorNeighbor().

◆ norm()
|
inline |
Returns the magnitude of z squared.
Definition at line 896 of file complex_quda.h.
References z.
Referenced by construct_clover_field(), constructCloverField(), ErrorSU3(), quda::GMResDR::FlexArnoldiProcedure(), init(), main(), new_load_half(), new_save_half(), newCopyToFloat(), newCopyToHalf(), quda::gauge::FieldOrder< Float, nColor, nSpinCoarse, order, native_ghost >::norm2(), normalize(), old_load_half(), old_save_half(), oldCopyToFloat(), oldCopyToHalf(), quda::gauge::square< ReduceType, Float >::operator()(), quda::colorspinor::square< ReduceType, Float >::operator()(), quda::GMResDR::operator()(), operator/(), performWuppertalnStep(), quda::ArpackArgs< Float >::save(), store_norm(), and quda::gauge::Reconstruct< 8, Float >::Unpack().
◆ norm1() [1/2]
| double quda::norm1 | ( | const CloverField & | u, |
| bool | inverse = false |
||
| ) |
This is a debugging function, where we cast a clover field into a spinor field so we can compute its L1 norm.
- Parameters
-
a The clover field that we want the norm of
- Returns
- The L1 norm of the gauge field
Definition at line 455 of file clover_field.cpp.
References a, b, colorSpinorParam(), quda::ColorSpinorField::Create(), and quda::blas::norm1().
◆ norm1() [2/2]
| double quda::norm1 | ( | const GaugeField & | u | ) |
This is a debugging function, where we cast a gauge field into a spinor field so we can compute its L1 norm.
- Parameters
-
u The gauge field that we want the norm of
- Returns
- The L1 norm of the gauge field
Definition at line 314 of file gauge_field.cpp.
References a, b, colorSpinorParam(), quda::ColorSpinorField::Create(), and quda::blas::norm1().
◆ norm2() [1/2]
| double quda::norm2 | ( | const CloverField & | a, |
| bool | inverse = false |
||
| ) |
This is a debugging function, where we cast a clover field into a spinor field so we can compute its L2 norm.
- Parameters
-
a The clover field that we want the norm of
- Returns
- The L2 norm squared of the gauge field
Definition at line 447 of file clover_field.cpp.
References a, b, colorSpinorParam(), quda::ColorSpinorField::Create(), and quda::blas::norm2().
Referenced by quda::GMResDR::FlexArnoldiProcedure(), quda::MG::generateNullVectors(), quda::Lanczos::operator()(), quda::Deflation::operator()(), quda::MG::operator()(), quda::PreconCG::operator()(), quda::SimpleBiCGstab::operator()(), quda::SD::operator()(), quda::IncEigCG::operator()(), quda::GMResDR::operator()(), quda::Deflation::reduce(), quda::Deflation::verify(), and quda::MG::verify().
◆ norm2() [2/2]
| double quda::norm2 | ( | const GaugeField & | u | ) |
This is a debugging function, where we cast a gauge field into a spinor field so we can compute its L2 norm.
- Parameters
-
u The gauge field that we want the norm of
- Returns
- The L2 norm squared of the gauge field
Definition at line 306 of file gauge_field.cpp.
References a, b, colorSpinorParam(), quda::ColorSpinorField::Create(), and quda::blas::norm2().
◆ operator!=() [1/3]
|
inline |
Definition at line 839 of file complex_quda.h.
Referenced by std::__1::__attribute(), and std::__1::__attribute__().
◆ operator!=() [2/3]
|
inline |
Definition at line 845 of file complex_quda.h.
◆ operator!=() [3/3]
|
inline |
Definition at line 851 of file complex_quda.h.
◆ operator*() [1/16]
|
inline |
Definition at line 48 of file float_vector.h.
◆ operator*() [2/16]
|
inline |
Definition at line 57 of file float_vector.h.
◆ operator*() [3/16]
|
inline |
Definition at line 64 of file float_vector.h.
◆ operator*() [4/16]
|
inline |
Definition at line 71 of file float_vector.h.
◆ operator*() [5/16]
|
inline |
Definition at line 727 of file complex_quda.h.
◆ operator*() [6/16]
|
inline |
Definition at line 736 of file complex_quda.h.
◆ operator*() [7/16]
|
inline |
Definition at line 743 of file complex_quda.h.
◆ operator*() [8/16]
|
inline |
Definition at line 366 of file quda_matrix.h.
References a, and fused_exterior_ndeg_tm_dslash_cuda_gen::i.
◆ operator*() [9/16]
|
inline |
Definition at line 374 of file quda_matrix.h.
References a.
◆ operator*() [10/16]
|
inline |
Generic implementation of matrix multiplication.
Definition at line 397 of file quda_matrix.h.
References a, b, and fused_exterior_ndeg_tm_dslash_cuda_gen::i.
◆ operator*() [11/16]
|
inline |
Specialization of complex matrix multiplication that will issue optimal fma instructions.
Definition at line 418 of file quda_matrix.h.
References a, b, and fused_exterior_ndeg_tm_dslash_cuda_gen::i.
◆ operator*() [12/16]
|
inline |
Definition at line 453 of file quda_matrix.h.
References a, b, and fused_exterior_ndeg_tm_dslash_cuda_gen::i.
◆ operator*() [13/16]
|
inline |
Definition at line 473 of file quda_matrix.h.
◆ operator*() [14/16]
|
inline |
Compute the scalar-vector product y = a * x.
- Parameters
-
[in] a Input scalar [in] x Input vector
- Returns
- The vector a * x
Definition at line 929 of file color_spinor.h.
References a, fused_exterior_ndeg_tm_dslash_cuda_gen::i, s, x, and y.
◆ operator*() [15/16]
|
inline |
Compute the matrix-vector product y = A * x.
- Parameters
-
[in] A Input matrix [in] x Input vector
- Returns
- The vector A * x
Definition at line 951 of file color_spinor.h.
References fused_exterior_ndeg_tm_dslash_cuda_gen::i, s, x, and y.
◆ operator*() [16/16]
|
inline |
Compute the matrix-vector product y = A * x.
- Parameters
-
[in] A Input Hermitian matrix with dimensions NcxNs x NcxNs [in] x Input vector
- Returns
- The vector A * x
Definition at line 986 of file color_spinor.h.
References fused_exterior_ndeg_tm_dslash_cuda_gen::i, x, and y.
◆ operator*=() [1/7]
|
inline |
Definition at line 151 of file float_vector.h.
◆ operator*=() [2/7]
|
inline |
Definition at line 157 of file float_vector.h.
◆ operator*=() [3/7]
|
inline |
Definition at line 163 of file float_vector.h.
◆ operator*=() [4/7]
|
inline |
Definition at line 171 of file float_vector.h.
◆ operator*=() [5/7]
|
inline |
Definition at line 177 of file float_vector.h.
◆ operator*=() [6/7]
|
inline |
Definition at line 379 of file quda_matrix.h.
References a.
◆ operator*=() [7/7]
|
inline |
Definition at line 442 of file quda_matrix.h.
◆ operator+() [1/13]
|
inline |
Definition at line 24 of file float_vector.h.
◆ operator+() [2/13]
|
inline |
Definition at line 40 of file float_vector.h.
◆ operator+() [3/13]
|
inline |
Definition at line 44 of file float_vector.h.
◆ operator+() [4/13]
|
inline |
Definition at line 80 of file float_vector.h.
◆ operator+() [5/13]
|
inline |
Definition at line 87 of file float_vector.h.
◆ operator+() [6/13]
|
inline |
Definition at line 88 of file cub_helper.cuh.
References a, b, c, fused_exterior_ndeg_tm_dslash_cuda_gen::i, and n.
◆ operator+() [7/13]
|
inline |
Definition at line 679 of file complex_quda.h.
◆ operator+() [8/13]
|
inline |
Definition at line 695 of file complex_quda.h.
◆ operator+() [9/13]
|
inline |
Definition at line 701 of file complex_quda.h.
◆ operator+() [10/13]
|
inline |
Definition at line 800 of file complex_quda.h.
◆ operator+() [11/13]
|
inline |
Definition at line 323 of file quda_matrix.h.
References a, b, and fused_exterior_ndeg_tm_dslash_cuda_gen::i.
◆ operator+() [12/13]
|
inline |
Definition at line 687 of file complex_quda.h.
◆ operator+() [13/13]
|
inline |
ColorSpinor addition operator.
- Parameters
-
[in] x Input vector [in] y Input vector
- Returns
- The vector x + y
Definition at line 885 of file color_spinor.h.
References fused_exterior_ndeg_tm_dslash_cuda_gen::i, s, x, y, and z.
◆ operator+=() [1/8]
|
inline |
Definition at line 86 of file clover_deriv_quda.cu.
References deg_tm_dslash_cuda_gen::block(), blockDim, for(), fused_exterior_ndeg_tm_dslash_cuda_gen::i, x, and y.

◆ operator+=() [2/8]
|
inline |
Definition at line 96 of file float_vector.h.
◆ operator+=() [3/8]
|
inline |
Definition at line 104 of file float_vector.h.
◆ operator+=() [4/8]
|
inline |
Definition at line 110 of file float_vector.h.
◆ operator+=() [5/8]
|
inline |
Definition at line 116 of file float_vector.h.
◆ operator+=() [6/8]
|
inline |
Definition at line 123 of file float_vector.h.
◆ operator+=() [7/8]
|
inline |
Definition at line 333 of file quda_matrix.h.
References a, b, and fused_exterior_ndeg_tm_dslash_cuda_gen::i.
◆ operator+=() [8/8]
|
inline |
Definition at line 341 of file quda_matrix.h.
References a, b, and fused_exterior_ndeg_tm_dslash_cuda_gen::i.
◆ operator-() [1/12]
|
inline |
Definition at line 28 of file float_vector.h.
◆ operator-() [2/12]
|
inline |
Definition at line 32 of file float_vector.h.
◆ operator-() [3/12]
|
inline |
Definition at line 36 of file float_vector.h.
◆ operator-() [4/12]
|
inline |
Definition at line 708 of file complex_quda.h.
◆ operator-() [5/12]
|
inline |
Definition at line 714 of file complex_quda.h.
◆ operator-() [6/12]
|
inline |
Definition at line 185 of file float_vector.h.
References x.
◆ operator-() [7/12]
|
inline |
Definition at line 720 of file complex_quda.h.
◆ operator-() [8/12]
|
inline |
Definition at line 189 of file float_vector.h.
References x.
◆ operator-() [9/12]
|
inline |
Definition at line 805 of file complex_quda.h.
◆ operator-() [10/12]
|
inline |
Definition at line 357 of file quda_matrix.h.
References a, b, and fused_exterior_ndeg_tm_dslash_cuda_gen::i.
◆ operator-() [11/12]
|
inline |
Definition at line 385 of file quda_matrix.h.
References a, and fused_exterior_ndeg_tm_dslash_cuda_gen::i.
◆ operator-() [12/12]
|
inline |
ColorSpinor subtraction operator.
- Parameters
-
[in] x Input vector [in] y Input vector
- Returns
- The vector x + y
Definition at line 907 of file color_spinor.h.
References fused_exterior_ndeg_tm_dslash_cuda_gen::i, s, x, y, and z.
◆ operator-=() [1/5]
|
inline |
Definition at line 97 of file clover_deriv_quda.cu.
References deg_tm_dslash_cuda_gen::block(), blockDim, for(), fused_exterior_ndeg_tm_dslash_cuda_gen::i, x, and y.

◆ operator-=() [2/5]
|
inline |
Definition at line 131 of file float_vector.h.
◆ operator-=() [3/5]
|
inline |
Definition at line 139 of file float_vector.h.
◆ operator-=() [4/5]
|
inline |
Definition at line 145 of file float_vector.h.
◆ operator-=() [5/5]
|
inline |
Definition at line 349 of file quda_matrix.h.
References a, b, and fused_exterior_ndeg_tm_dslash_cuda_gen::i.
◆ operator/() [1/7]
|
inline |
Definition at line 751 of file complex_quda.h.
References norm().

◆ operator/() [2/7]
|
inline |
Definition at line 760 of file complex_quda.h.
◆ operator/() [3/7]
|
inline |
Definition at line 766 of file complex_quda.h.
◆ operator/() [4/7]
|
inline |
Definition at line 772 of file complex_quda.h.
◆ operator/() [5/7]
|
inline |
Definition at line 779 of file complex_quda.h.
References norm().

◆ operator/() [6/7]
|
inline |
Definition at line 787 of file complex_quda.h.
◆ operator/() [7/7]
|
inline |
Definition at line 792 of file complex_quda.h.
◆ operator<<() [1/8]
| std::ostream & quda::operator<< | ( | std::ostream & | output, |
| const CloverFieldParam & | param | ||
| ) |
Definition at line 404 of file clover_field.cpp.
References param.
◆ operator<<() [2/8]
| std::ostream & quda::operator<< | ( | std::ostream & | output, |
| const LatticeFieldParam & | param | ||
| ) |
Definition at line 566 of file lattice_field.cpp.
References fused_exterior_ndeg_tm_dslash_cuda_gen::i, and param.
◆ operator<<() [3/8]
| std::ostream & quda::operator<< | ( | std::ostream & | output, |
| const GaugeFieldParam & | param | ||
| ) |
Definition at line 254 of file gauge_field.cpp.
References QudaGaugeParam_s::anisotropy, param, QUDA_RECONSTRUCT_NO, QudaGaugeParam_s::reconstruct, QudaGaugeParam_s::scale, and QudaGaugeParam_s::t_boundary.
◆ operator<<() [4/8]
| std::basic_ostream< charT, traits > & quda::operator<< | ( | std::basic_ostream< charT, traits > & | os, |
| const complex< ValueType > & | z | ||
| ) |
Definition at line 295 of file complex_quda.h.
References z.
◆ operator<<() [5/8]
| std::ostream& quda::operator<< | ( | std::ostream & | os, |
| const Matrix< T, N > & | m | ||
| ) |
Definition at line 723 of file quda_matrix.h.
References fused_exterior_ndeg_tm_dslash_cuda_gen::i.
◆ operator<<() [6/8]
| std::ostream& quda::operator<< | ( | std::ostream & | os, |
| const Array< T, N > & | a | ||
| ) |
Definition at line 737 of file quda_matrix.h.
References a, and fused_exterior_ndeg_tm_dslash_cuda_gen::i.
◆ operator<<() [7/8]
| std::ostream& quda::operator<< | ( | std::ostream & | out, |
| const ColorSpinorField & | a | ||
| ) |
Definition at line 833 of file color_spinor_field.cpp.
◆ operator<<() [8/8]
| std::ostream& quda::operator<< | ( | std::ostream & | out, |
| const cudaColorSpinorField & | a | ||
| ) |
Definition at line 1446 of file cuda_color_spinor_field.cu.
◆ operator==() [1/3]
|
inline |
Definition at line 812 of file complex_quda.h.
Referenced by std::__1::__attribute(), and std::__1::__attribute__().
◆ operator==() [2/3]
|
inline |
Definition at line 821 of file complex_quda.h.
◆ operator==() [3/3]
|
inline |
Definition at line 829 of file complex_quda.h.
◆ operator>>()
| std::basic_istream< charT, traits > & quda::operator>> | ( | std::basic_istream< charT, traits > & | is, |
| complex< ValueType > & | z | ||
| ) |
Definition at line 303 of file complex_quda.h.
References z.
◆ orthoDir()
| void quda::orthoDir | ( | Complex ** | beta, |
| std::vector< ColorSpinorField *> | Ap, | ||
| int | k, | ||
| int | pipeline | ||
| ) |
Definition at line 83 of file inv_gcr_quda.cpp.
References quda::blas::caxpy(), quda::blas::caxpyDotzy(), quda::blas::cDotProduct(), computeBeta(), errorQuda, fused_exterior_ndeg_tm_dslash_cuda_gen::i, pipeline, and updateAp().
Referenced by quda::GCR::operator()().

◆ outerProd() [1/2]
|
inline |
Definition at line 695 of file quda_matrix.h.
References a, b, conj(), and fused_exterior_ndeg_tm_dslash_cuda_gen::i.
Referenced by constructHHMat().


◆ outerProd() [2/2]
|
inline |
Definition at line 708 of file quda_matrix.h.
References a, b, conj(), and fused_exterior_ndeg_tm_dslash_cuda_gen::i.

◆ outerProdSpinTrace()
|
inline |
Compute the outer product over color and take the spin trace out(j,i) = a(s,j) * conj (b(s,i))
- Parameters
-
a Left-hand side ColorSpinor b Right-hand side ColorSpinor
- Returns
- The spin traced matrix
Definition at line 849 of file color_spinor.h.
References a, b, fused_exterior_ndeg_tm_dslash_cuda_gen::i, out, and s.
◆ OvrImpSTOUTStep() [1/3]
| void quda::OvrImpSTOUTStep | ( | GaugeField & | dataDs, |
| const GaugeField & | dataOr, | ||
| double | rho, | ||
| double | epsilon | ||
| ) |
Apply Over Improved STOUT smearing to the gauge field
- Parameters
-
dataDs Output smeared field dataOr Input gauge field rho smearing parameter epsilon smearing parameter
Definition at line 801 of file gauge_stout.cu.
References errorQuda, float, quda::GaugeField::isNative(), quda::GaugeField::Order(), quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, QUDA_HALF_PRECISION, QUDA_SINGLE_PRECISION, and quda::GaugeField::Reconstruct().
Referenced by OvrImpSTOUTStep(), and performOvrImpSTOUTnStep().

◆ OvrImpSTOUTStep() [2/3]
| void quda::OvrImpSTOUTStep | ( | GaugeOr | origin, |
| GaugeDs | dest, | ||
| const GaugeField & | dataOr, | ||
| Float | rho, | ||
| Float | epsilon | ||
| ) |
Definition at line 740 of file gauge_stout.cu.
References arg(), DOUBLE_TOL, quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, qudaDeviceSynchronize(), and SINGLE_TOL.
◆ OvrImpSTOUTStep() [3/3]
| void quda::OvrImpSTOUTStep | ( | GaugeField & | dataDs, |
| const GaugeField & | dataOr, | ||
| Float | rho, | ||
| Float | epsilon | ||
| ) |
Definition at line 749 of file gauge_stout.cu.
References errorQuda, OvrImpSTOUTStep(), QUDA_RECONSTRUCT_12, QUDA_RECONSTRUCT_8, QUDA_RECONSTRUCT_NO, and quda::GaugeField::Reconstruct().
◆ packFace()
| void quda::packFace | ( | void * | ghost_buf[2 *QUDA_MAX_DIM], |
| cudaColorSpinorField & | in, | ||
| MemoryLocation | location, | ||
| const int | nFace, | ||
| const int | dagger, | ||
| const int | parity, | ||
| const int | dim, | ||
| const int | face_num, | ||
| const cudaStream_t & | stream, | ||
| const double | a = 0.0, |
||
| const double | b = 0.0 |
||
| ) |
Dslash face packing routine.
- Parameters
-
[out] ghost_buf Array of packed halos, order is [2*dim+dir] [in] in Input ColorSpinorField to be packed [in] location Locations where the packed fields are (Device, Host and/or Remote) [in] nFace Depth of halo [in] dagger Whether this is for the dagger operator [in] parity Field parity [in] dim Which dimensions we are packing [in] face_num Are we packing backwards (0), forwards (1) or both directions (2) [in] stream Which stream are we executing in [in] a Packing coefficient (twisted-mass only) [in] b Packing coefficient (twisted-mass only)
Referenced by quda::cudaColorSpinorField::packGhost().
◆ packFaceExtended()
| void quda::packFaceExtended | ( | void * | ghost_buf[2 *QUDA_MAX_DIM], |
| cudaColorSpinorField & | field, | ||
| MemoryLocation | location, | ||
| const int | nFace, | ||
| const int | R[], | ||
| const int | dagger, | ||
| const int | parity, | ||
| const int | dim, | ||
| const int | face_num, | ||
| const cudaStream_t & | stream, | ||
| const bool | unpack = false |
||
| ) |
Referenced by quda::cudaColorSpinorField::packGhostExtended(), and quda::cudaColorSpinorField::unpackGhostExtended().

◆ packGhost()
|
inline |
Definition at line 47 of file color_spinor_pack.cu.
References arg(), c, dim, getCoords(), getCoords5(), parity, s, and x.
◆ packSpinor()
| void quda::packSpinor | ( | OutOrder & | outOrder, |
| const InOrder & | inOrder, | ||
| int | volume | ||
| ) |
CPU function to reorder spinor fields.
Definition at line 22 of file copy_color_spinor_mg.cuh.
◆ packSpinorKernel()
| __global__ void quda::packSpinorKernel | ( | OutOrder | outOrder, |
| const InOrder | inOrder, | ||
| int | volume | ||
| ) |
◆ PGaugeExchange()
| void quda::PGaugeExchange | ( | cudaGaugeField & | data, |
| const int | dir, | ||
| const int | parity | ||
| ) |
Perform heatbath and overrelaxation. Performs nhb heatbath steps followed by nover overrelaxation steps.
- Parameters
-
[in,out] data Gauge field [in,out] rngstate state of the CURAND random number generator [in] Beta inverse of the gauge coupling, beta = 2 Nc / g_0^2 [in] nhb number of heatbath steps [in] nover number of overrelaxation steps
Definition at line 345 of file pgauge_exchange.cu.
References comm_dim_partitioned(), errorQuda, parity, quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, QUDA_HALF_PRECISION, and QUDA_SINGLE_PRECISION.

◆ PGaugeExchangeFree()
| void quda::PGaugeExchangeFree | ( | ) |
Release all allocated memory used to exchange data between nodes.
Referenced by main(), and GaugeAlgTest::TearDown().
◆ pinned_allocated_peak()
| long quda::pinned_allocated_peak | ( | ) |
- Returns
- peak pinned memory allocated
Definition at line 59 of file malloc.cpp.
References max_total_bytes, and PINNED.
◆ pinned_malloc_()
Allocate page-locked ("pinned") host memory. This function should only be called via the pinned_malloc() macro, defined in malloc_quda.h
Note that we do not rely on cudaHostAlloc(), since buffers allocated in this way have been observed to cause problems when shared with MPI via GPU Direct on some systems.
Definition at line 246 of file malloc.cpp.
References a, aligned_malloc(), err, errorQuda, func, memset(), PINNED, printfQuda, ptr, size, and track_malloc().
Referenced by quda::pool::pinned_malloc_().

◆ plaquette()
| double3 quda::plaquette | ( | const GaugeField & | U, |
| QudaFieldLocation | location | ||
| ) |
Compute the plaquette of the gauge field
- Parameters
-
U The gauge field upon which to compute the plaquette location The locaiton where to do the computation
- Returns
- double3 variable returning (plaquette, spatial plaquette, temporal plaquette) site averages normalized such that each plaquette is in the range [0,1]
Definition at line 138 of file gauge_plaq.cu.
References errorQuda, and INSTANTIATE_PRECISION.
Referenced by main(), performAPEnStep(), performOvrImpSTOUTnStep(), performSTOUTnStep(), plaqQuda(), GaugeAlgTest::SetUp(), and TEST_F().
◆ point()
Create a point source at spacetime point x, spin s and colour c
Definition at line 30 of file color_spinor_util.cu.
Referenced by genericSource().

◆ polar() [1/3]
|
inline |
Returns the complex with magnitude m and angle theta in radians.
Definition at line 902 of file complex_quda.h.
Referenced by construct_fat_long_gauge_field(), exp(), and sqrt().
◆ polar() [2/3]
|
inline |
Definition at line 908 of file complex_quda.h.
References cosf(), and sinf().
◆ polar() [3/3]
|
inline |
◆ polarSu3()
| __host__ __device__ void quda::polarSu3 | ( | Matrix< complex< Float >, 3 > & | in, |
| Float | tol | ||
| ) |
Project the input matrix on the SU(3) group. First unitarize the matrix and then project onto the special unitary group.
- Parameters
-
in The input matrix to which we're projecting tol Tolerance to which this check is applied
Definition at line 71 of file su3_project.cuh.
References atan2(), checkUnitary(), computeMatrixInverse(), conj(), cos(), getDeterminant(), in, mod(), out, pow(), sin(), and tol.
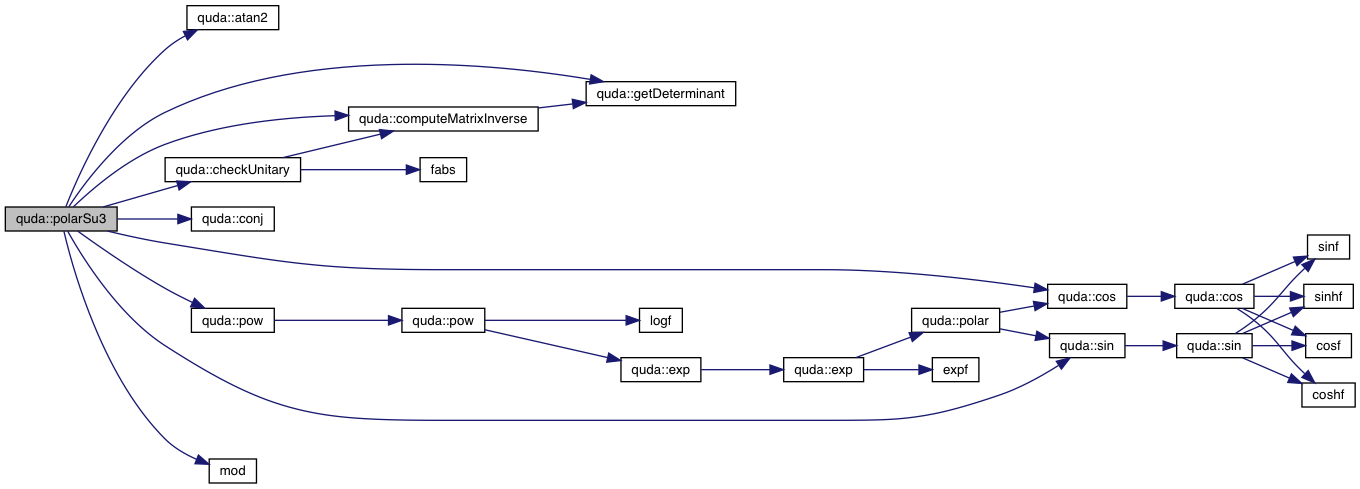
◆ policyTuning()
| bool quda::policyTuning | ( | ) |
Definition at line 453 of file tune.cpp.
References policy_tuning.
Referenced by tuneLaunch().
◆ pow() [1/6]
|
inline |
Definition at line 100 of file complex_quda.h.
Referenced by compareSpinor(), dslashReference_5th_inv(), exponentiate_iQ(), insertNoise(), quda::RitzMat::operator()(), quda::CG::operator()(), quda::MultiShiftCG::operator()(), polarSu3(), TEST(), and TEST_P().

◆ pow() [2/6]
|
inline |
Definition at line 1012 of file complex_quda.h.
References exp(), log(), and z.
◆ pow() [3/6]
|
inline |
Definition at line 988 of file complex_quda.h.
References exp(), log(), and z.
◆ pow() [4/6]
|
inline |
Definition at line 994 of file complex_quda.h.
References exp(), log(), and z.
◆ pow() [5/6]
|
inline |
Definition at line 1000 of file complex_quda.h.
References exp(), log(), and x.
◆ pow() [6/6]
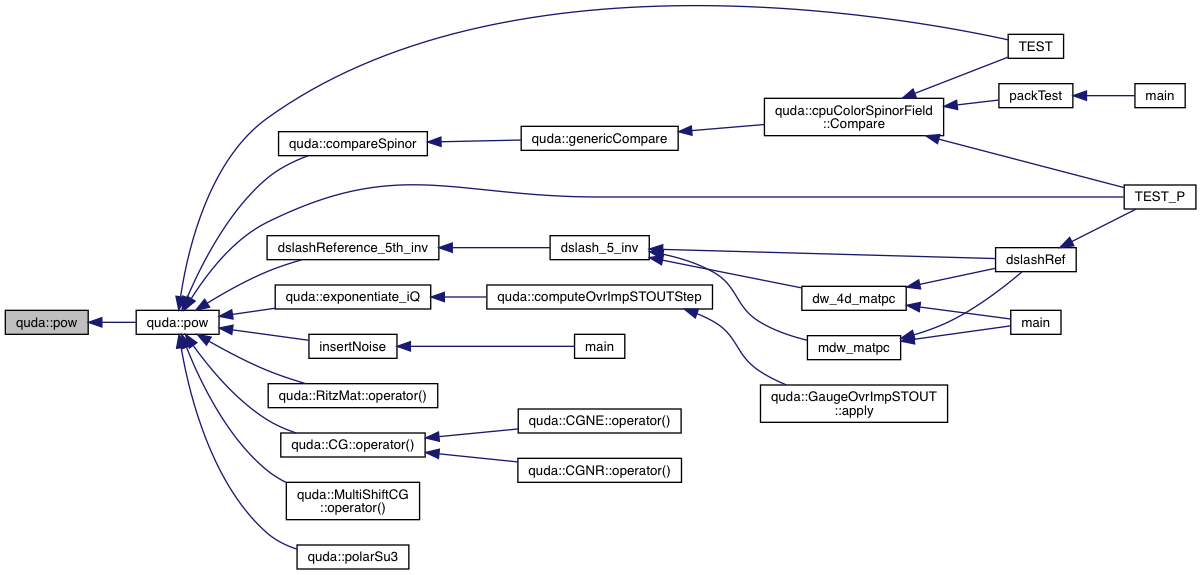
◆ Precision_() [1/2]
|
inline |
Helper function for determining if the precision of the fields is the same.
- Parameters
-
[in] a Input field [in] b Input field
- Returns
- If precision is unique return the precision
Definition at line 569 of file lattice_field.h.
References a, b, errorQuda, func, and QUDA_INVALID_PRECISION.
Referenced by Precision_().

◆ Precision_() [2/2]
|
inline |
Helper function for determining if the precision of the fields is the same.
- Parameters
-
[in] a Input field [in] b Input field [in] args List of additional fields to check precision on
- Returns
- If precision is unique return the precision
Definition at line 586 of file lattice_field.h.
References a, args, b, func, and Precision_().

◆ print()
Definition at line 44 of file inv_mpcg_quda.cpp.
References d, fused_exterior_ndeg_tm_dslash_cuda_gen::i, and n.
◆ print_alloc()
|
static |
Definition at line 83 of file malloc.cpp.
References a, alloc, entry, printfQuda, and ptr.
Referenced by assertAllMemFree().
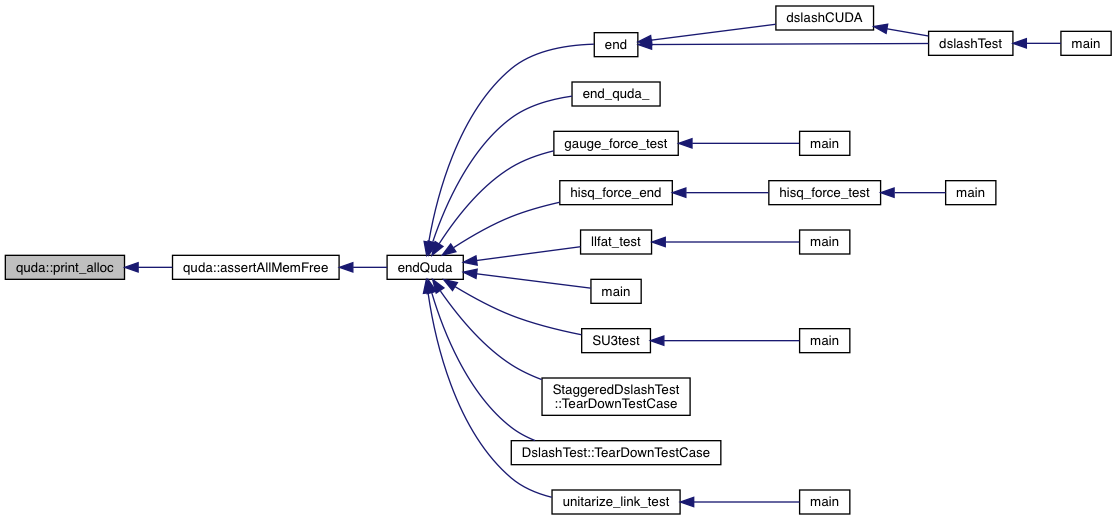
◆ print_alloc_header()
|
static |
Definition at line 76 of file malloc.cpp.
References printfQuda.
Referenced by assertAllMemFree().
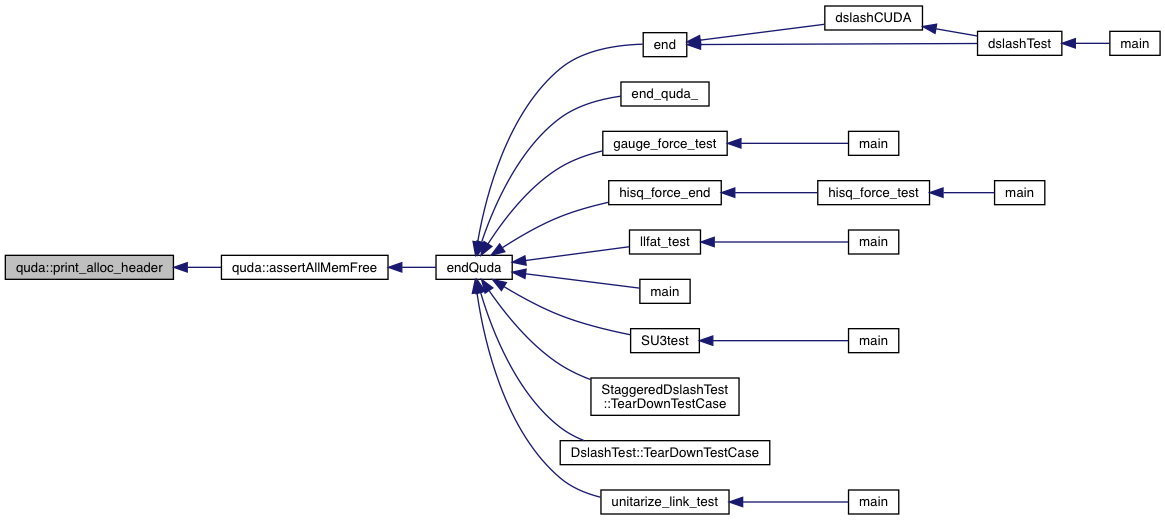
◆ print_trace()
|
static |
Definition at line 65 of file malloc.cpp.
References array, free(), fused_exterior_ndeg_tm_dslash_cuda_gen::i, printfQuda, and size.
Referenced by host_free_().


◆ print_vector()
| void quda::print_vector | ( | const Order & | o, |
| unsigned int | x | ||
| ) |
Definition at line 267 of file color_spinor_util.cu.
References c, parity, s, and x.
Referenced by genericPrintVector().

◆ printAPIProfile()
| void quda::printAPIProfile | ( | ) |
Print out the timer profile for CUDA API calls.
Definition at line 303 of file quda_cuda_api.cpp.
References apiTimer, and quda::TimeProfile::Print().
Referenced by endQuda().

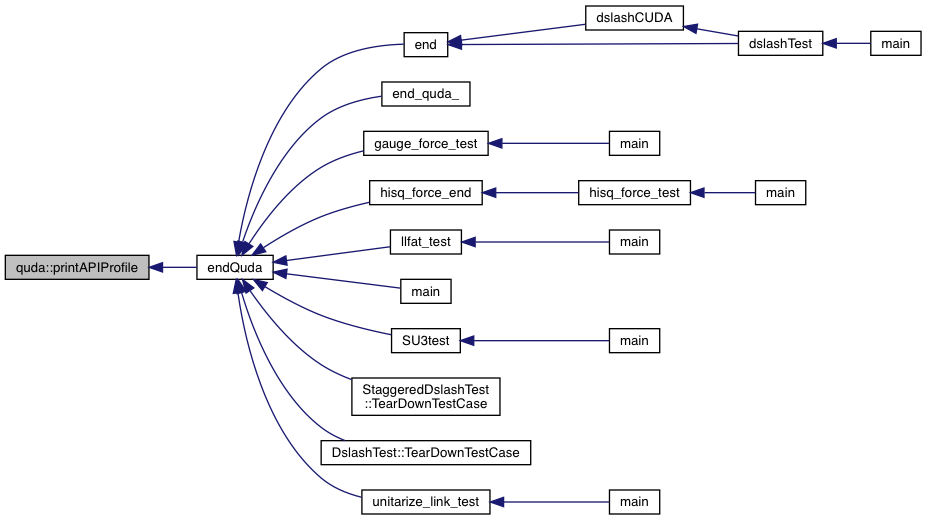
◆ printLaunchTimer()
| void quda::printLaunchTimer | ( | ) |
Definition at line 797 of file tune.cpp.
References launchTimer, and quda::TimeProfile::Print().
Referenced by endQuda().

◆ printLink()
|
inline |
Definition at line 1039 of file quda_matrix.h.
References printf(), x, and y.

◆ printPeakMemUsage()
| void quda::printPeakMemUsage | ( | ) |
Definition at line 371 of file malloc.cpp.
References DEVICE, max_total_bytes, max_total_host_bytes, max_total_pinned_bytes, and printfQuda.
Referenced by endQuda().
◆ projectSU3()
| void quda::projectSU3 | ( | cudaGaugeField & | U, |
| double | tol, | ||
| int * | fails | ||
| ) |
Project the input gauge field onto the SU(3) group. This is a destructive operation. The number of link failures is reported so appropriate action can be taken.
- Parameters
-
U Gauge field that we are projecting onto SU(3) tol Tolerance to which the iterative algorithm works fails Number of link failures (device pointer)
Definition at line 584 of file unitarize_links_quda.cu.
References quda::ProjectSU3< Float, G >::apply(), arg(), checkCudaError, errorQuda, QUDA_RECONSTRUCT_NO, qudaDeviceSynchronize(), quda::GaugeField::Reconstruct(), and tol.
Referenced by projectSU3Quda().

◆ ProjectSU3kernel()
| __global__ void quda::ProjectSU3kernel | ( | ProjectSU3Arg< Float, G > | arg | ) |
Definition at line 532 of file unitarize_links_quda.cu.
References arg(), blockDim, quda::Matrix< T, N >::data, idx, isUnitary(), mu, and parity.

◆ Prolongate()
| void quda::Prolongate | ( | ColorSpinorField & | out, |
| const ColorSpinorField & | in, | ||
| const ColorSpinorField & | v, | ||
| int | Nvec, | ||
| const int * | fine_to_coarse, | ||
| const int * | spin_map, | ||
| int | parity = QUDA_INVALID_PARITY |
||
| ) |
Apply the prolongation operator.
- Parameters
-
[out] out Resulting fine grid field [in] in Input field on coarse grid [in] v Matrix field containing the null-space components [in] Nvec Number of null-space components [in] fine_to_coarse Fine-to-coarse lookup table (linear indices) [in] spin_map Spin blocking lookup table [in] parity of the output fine field (if single parity output field)
Definition at line 284 of file prolongator.cu.
References checkCudaError, checkLocation, checkPrecision, errorQuda, quda::ColorSpinorField::FieldOrder(), in, out, parity, QUDA_CUDA_FIELD_LOCATION, QUDA_DOUBLE_PRECISION, and QUDA_SINGLE_PRECISION.
Referenced by quda::Transfer::P().


◆ qudaDeviceSynchronize()
| cudaError_t quda::qudaDeviceSynchronize | ( | ) |
Wrapper around cudaDeviceSynchronize or cuDeviceSynchronize.
Definition at line 277 of file quda_cuda_api.cpp.
References cudaErrorUnknown, errorQuda, PROFILE, and QUDA_PROFILE_DEVICE_SYNCHRONIZE.
Referenced by quda::cublas::BatchInvertMatrix(), completeKSForce(), computeKSLongLinkForce(), computeStaggeredForceQuda(), quda::cudaGaugeField::exchangeExtendedGhost(), exchangeExtendedGhost(), quda::cudaGaugeField::exchangeGhost(), quda::cudaColorSpinorField::exchangeGhost(), fatLongKSLink(), quda::cudaGaugeField::injectGhost(), launch_kernel_random(), quda::cudaGaugeField::loadCPUField(), OvrImpSTOUTStep(), projectSU3(), quda::Transfer::R(), remove_staggered_phase_quda_(), and quda::cudaGaugeField::saveCPUField().
◆ qudaEventQuery()
| cudaError_t quda::qudaEventQuery | ( | cudaEvent_t & | event | ) |
Wrapper around cudaEventQuery or cuEventQuery.
- Parameters
-
[in] event Event we are querying
- Returns
- Status of event query
Definition at line 190 of file quda_cuda_api.cpp.
References cudaErrorUnknown, errorQuda, event, PROFILE, and QUDA_PROFILE_EVENT_QUERY.
Referenced by multiReduceLaunch(), anonymous_namespace{dslash_policy.cuh}::DslashBasic::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashPthreads::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashFusedExterior::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashGDRRecv::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashFusedGDRRecv::operator()(), and reduceLaunch().
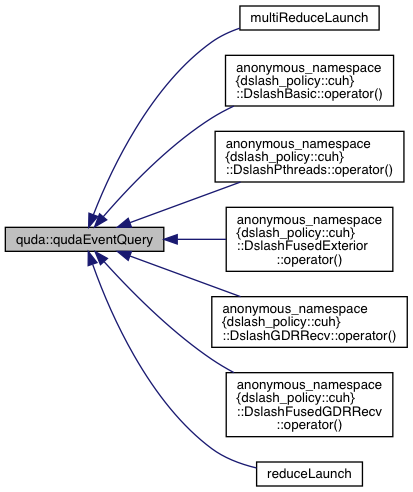
◆ qudaEventRecord()
| cudaError_t quda::qudaEventRecord | ( | cudaEvent_t & | event, |
| cudaStream_t | stream = 0 |
||
| ) |
Wrapper around cudaEventRecord or cuEventRecord.
- Parameters
-
[in,out] event Event we are recording [in,out] stream Stream where to record the event
Definition at line 209 of file quda_cuda_api.cpp.
References cudaErrorUnknown, errorQuda, event, PROFILE, QUDA_PROFILE_EVENT_RECORD, and stream.
Referenced by exchangeExtendedGhost(), anonymous_namespace{dslash_policy.cuh}::issueGather(), anonymous_namespace{dslash_policy.cuh}::issuePack(), multiReduceLaunch(), anonymous_namespace{dslash_policy.cuh}::DslashBasic::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashPthreads::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashFusedExterior::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashGDRRecv::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashFusedGDRRecv::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashZeroCopyPack::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashFusedZeroCopyPack::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashZeroCopyPackGDRRecv::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashFusedZeroCopyPackGDRRecv::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashZeroCopy::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashFusedZeroCopy::operator()(), reduceLaunch(), quda::cudaGaugeField::sendStart(), quda::cudaColorSpinorField::sendStart(), and shiftColorSpinorField().
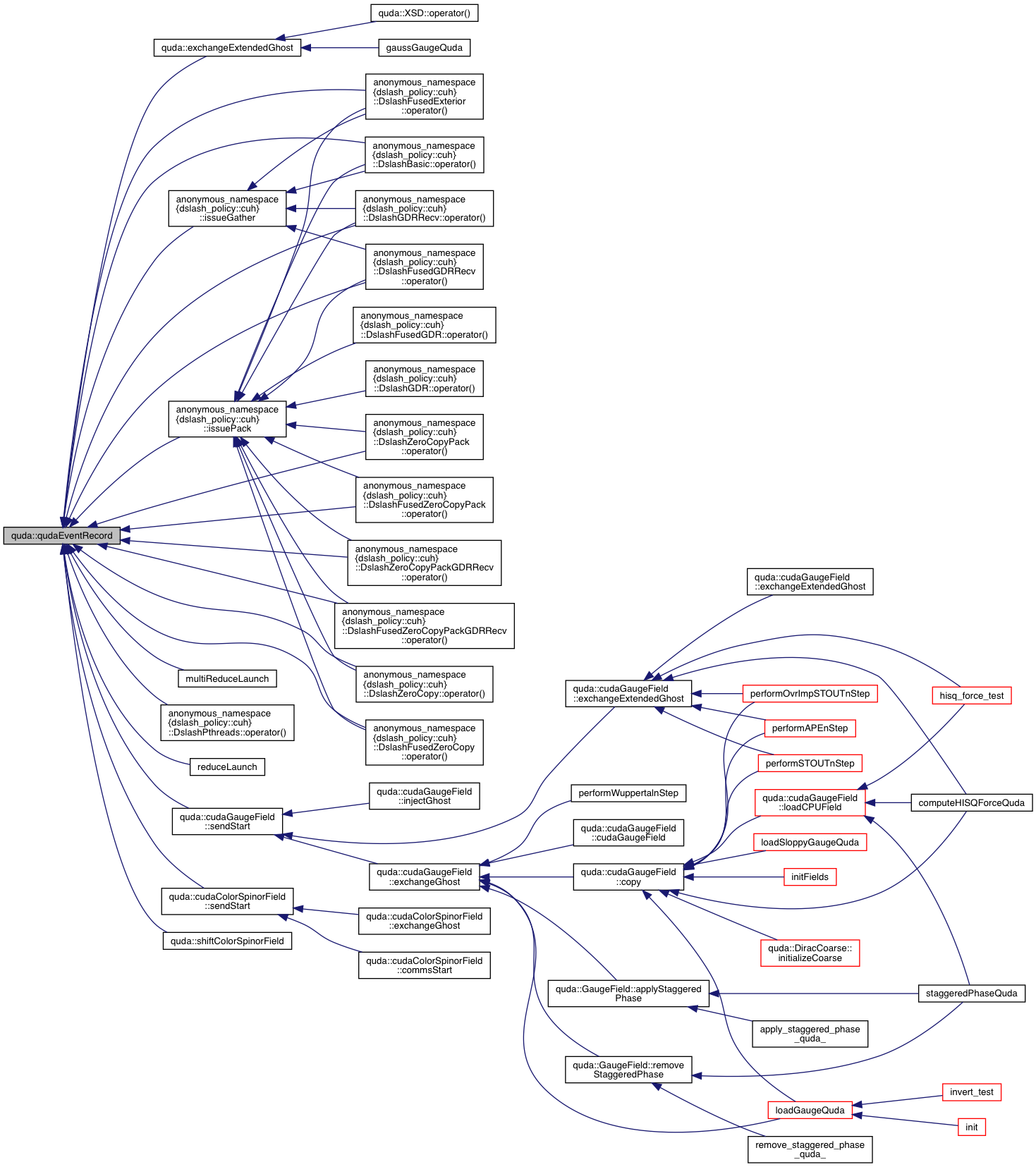
◆ qudaEventSynchronize()
| cudaError_t quda::qudaEventSynchronize | ( | cudaEvent_t & | event | ) |
Wrapper around cudaEventSynchronize or cuEventSynchronize.
- Parameters
-
[in] event Event which we are synchronizing with respect to
Definition at line 260 of file quda_cuda_api.cpp.
References cudaErrorUnknown, errorQuda, event, PROFILE, and QUDA_PROFILE_EVENT_SYNCHRONIZE.
Referenced by quda::cudaGaugeField::commsComplete().
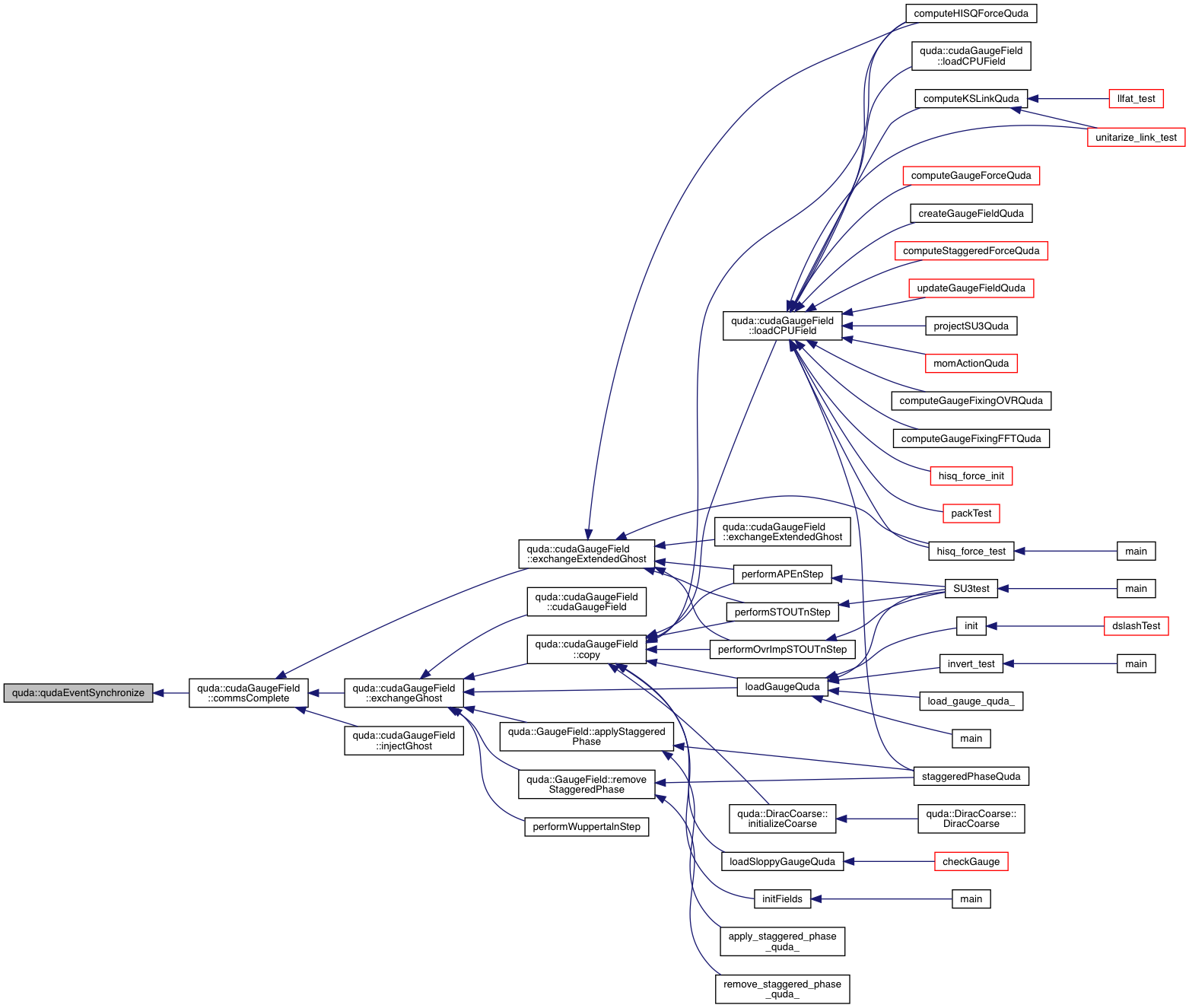
◆ qudaLaunchKernel()
| cudaError_t quda::qudaLaunchKernel | ( | const void * | func, |
| dim3 | gridDim, | ||
| dim3 | blockDim, | ||
| void ** | args, | ||
| size_t | sharedMem, | ||
| cudaStream_t | stream | ||
| ) |
Wrapper around cudaLaunchKernel.
- Parameters
-
[in] func Device function symbol [in] gridDim Grid dimensions [in] blockDim Block dimensions [in] args Arguments [in] sharedMem Shared memory requested per thread block [in] stream Stream identifier
Definition at line 182 of file quda_cuda_api.cpp.
References activeTuning(), args, blockDim, errorQuda, func, gridDim, PROFILE, QUDA_PROFILE_LAUNCH_KERNEL, sharedMem, and stream.

◆ qudaMemcpy2DAsync_()
| void quda::qudaMemcpy2DAsync_ | ( | void * | dst, |
| size_t | dpitch, | ||
| const void * | src, | ||
| size_t | spitch, | ||
| size_t | width, | ||
| size_t | hieght, | ||
| cudaMemcpyKind | kind, | ||
| const cudaStream_t & | stream, | ||
| const char * | func, | ||
| const char * | file, | ||
| const char * | line | ||
| ) |
Wrapper around cudaMemcpy2DAsync or driver API equivalent Potentially add auto-profiling support.
- Parameters
-
[out] dst Destination pointer [in] dpitch Destination pitch [in] src Source pointer [in] spitch Source pitch [in] width Width in bytes [in] height Number of rows [in] kind Type of memory copy [in] stream Stream to issue copy
Definition at line 151 of file quda_cuda_api.cpp.
References dpitch, errorQuda, height, kind, param, PROFILE, QUDA_PROFILE_MEMCPY2D_D2H_ASYNC, spitch, src, stream, and width.
◆ qudaMemcpy_()
| void quda::qudaMemcpy_ | ( | void * | dst, |
| const void * | src, | ||
| size_t | count, | ||
| cudaMemcpyKind | kind, | ||
| const char * | func, | ||
| const char * | file, | ||
| const char * | line | ||
| ) |
Wrapper around cudaMemcpy used for auto-profiling. Do not call directly, rather call macro below which will grab the location of the call.
- Parameters
-
[out] dst Destination pointer [in] src Source pointer [in] count Size of transfer [in] kind Type of memory copy
Definition at line 113 of file quda_cuda_api.cpp.
References checkCudaError, copy(), count, func, getVerbosity(), kind, printfQuda, QUDA_DEBUG_VERBOSE, and src.
◆ qudaMemcpyAsync_()
| void quda::qudaMemcpyAsync_ | ( | void * | dst, |
| const void * | src, | ||
| size_t | count, | ||
| cudaMemcpyKind | kind, | ||
| const cudaStream_t & | stream, | ||
| const char * | func, | ||
| const char * | file, | ||
| const char * | line | ||
| ) |
Wrapper around cudaMemcpyAsync or driver API equivalent Potentially add auto-profiling support.
- Parameters
-
[out] dst Destination pointer [in] src Source pointer [in] count Size of transfer [in] kind Type of memory copy [in] stream Stream to issue copy
Definition at line 128 of file quda_cuda_api.cpp.
References count, errorQuda, kind, PROFILE, QUDA_PROFILE_MEMCPY_D2D_ASYNC, QUDA_PROFILE_MEMCPY_D2H_ASYNC, QUDA_PROFILE_MEMCPY_H2D_ASYNC, src, and stream.
◆ qudaStreamSynchronize()
| cudaError_t quda::qudaStreamSynchronize | ( | cudaStream_t & | stream | ) |
Wrapper around cudaStreamSynchronize or cuStreamSynchronize.
- Parameters
-
[in] stream Stream which we are synchronizing with respect to
Definition at line 243 of file quda_cuda_api.cpp.
References cudaErrorUnknown, errorQuda, PROFILE, QUDA_PROFILE_STREAM_SYNCHRONIZE, and stream.
Referenced by contractCuda(), quda::cudaGaugeField::exchangeGhost(), quda::cudaGaugeField::injectGhost(), anonymous_namespace{dslash_policy.cuh}::DslashZeroCopyPack::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashFusedZeroCopyPack::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashZeroCopyPackGDRRecv::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashFusedZeroCopyPackGDRRecv::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashZeroCopy::operator()(), and anonymous_namespace{dslash_policy.cuh}::DslashFusedZeroCopy::operator()().
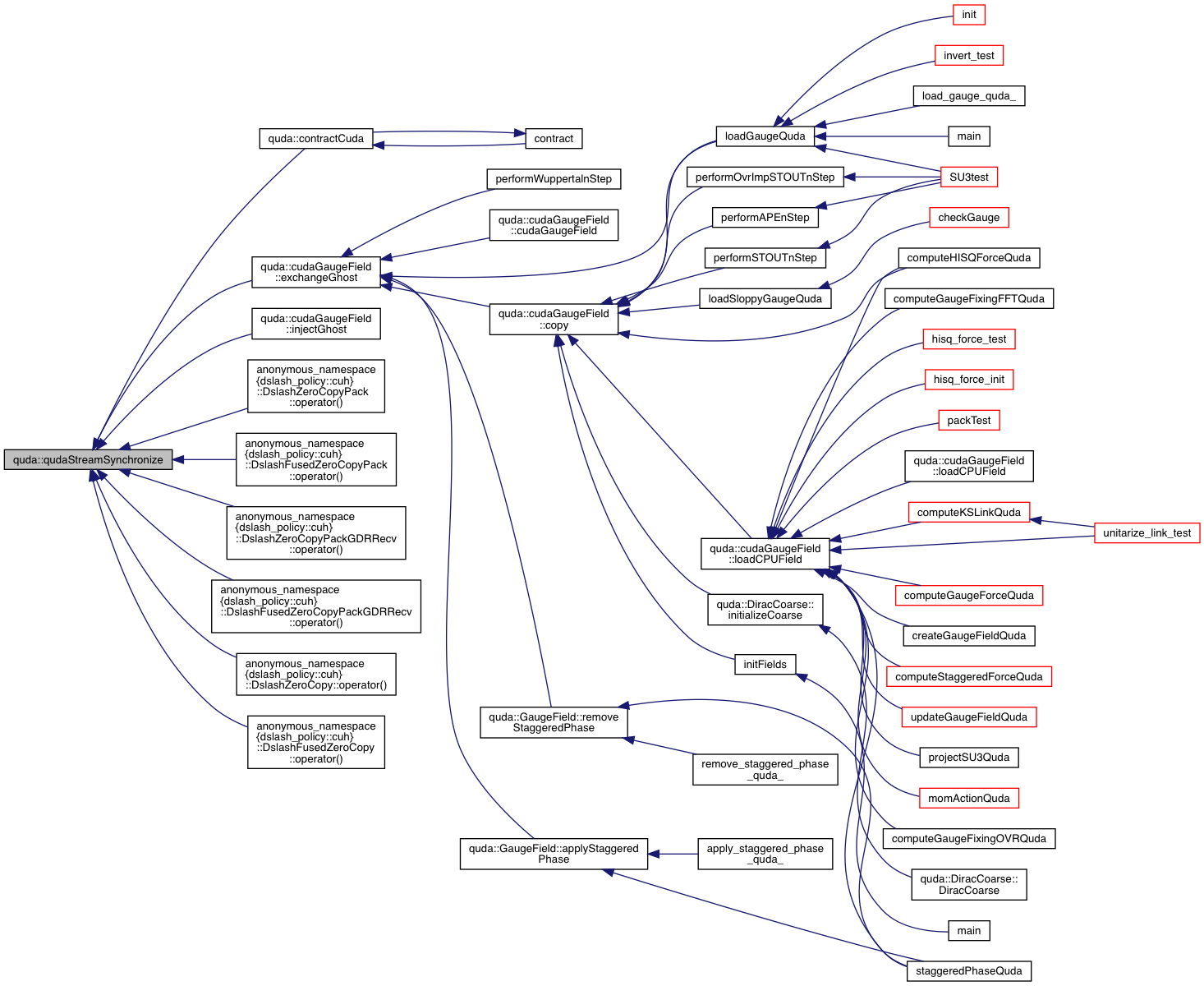
◆ qudaStreamWaitEvent()
| cudaError_t quda::qudaStreamWaitEvent | ( | cudaStream_t | stream, |
| cudaEvent_t | event, | ||
| unsigned int | flags | ||
| ) |
Wrapper around cudaEventRecord or cuEventRecord.
- Parameters
-
[in,out] stream Stream which we are instructing to wait [in] event Event we are waiting on [in] flags Flags to pass to function
Definition at line 226 of file quda_cuda_api.cpp.
References cudaErrorUnknown, errorQuda, event, flags, PROFILE, QUDA_PROFILE_STREAM_WAIT_EVENT, and stream.
Referenced by anonymous_namespace{dslash_policy.cuh}::commsComplete(), anonymous_namespace{dslash_policy.cuh}::completeDslash(), quda::cudaColorSpinorField::exchangeGhost(), anonymous_namespace{dslash_policy.cuh}::issueGather(), anonymous_namespace{dslash_policy.cuh}::DslashBasic::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashPthreads::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashFusedExterior::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashZeroCopyPack::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashFusedZeroCopyPack::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashZeroCopyPackGDRRecv::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashFusedZeroCopyPackGDRRecv::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashZeroCopy::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashFusedZeroCopy::operator()(), and shiftColorSpinorField().
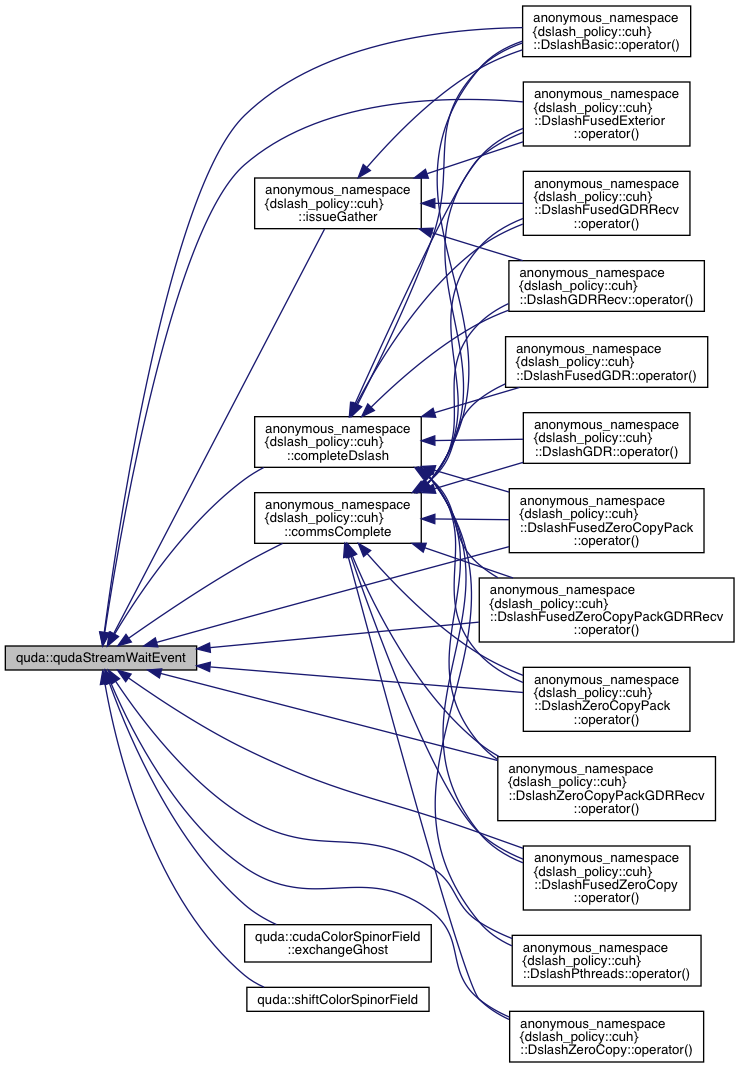
◆ r_slant()
|
inline |
Definition at line 47 of file malloc_quda.h.
Referenced by file_name().

◆ random()
| void quda::random | ( | T & | t | ) |
Random number insertion over all field elements
Definition at line 13 of file color_spinor_util.cu.
References c, comm_drand(), parity, s, and t.
Referenced by genericSource().


◆ Random() [1/2]
|
inline |
Return a random number between a and b.
- Parameters
-
state curand rng state a lower range b upper range
- Returns
- random number in range a,b
Definition at line 70 of file random_quda.h.
◆ Random() [2/2]
|
inline |
Return a random number between 0 and 1.
- Parameters
-
state curand rng state
- Returns
- random number in range 0,1
Definition at line 91 of file random_quda.h.
◆ Random< double >() [1/2]
|
inline |
Definition at line 81 of file random_quda.h.
◆ Random< double >() [2/2]
|
inline |
Definition at line 102 of file random_quda.h.
◆ Random< float >() [1/2]
|
inline |
Definition at line 76 of file random_quda.h.
◆ Random< float >() [2/2]
|
inline |
Definition at line 97 of file random_quda.h.
◆ reduce()
|
inline |
Definition at line 163 of file cub_helper.cuh.
References arg(), idx, and in.
Referenced by multiReduceCuda(), and reduceCuda().

◆ reduce2d()
|
inline |
Definition at line 122 of file cub_helper.cuh.
References __syncthreads(), arg(), count, gridDim, fused_exterior_ndeg_tm_dslash_cuda_gen::i, idx, in, isLastBlockDone, sum(), value, and zero().
◆ reduceRow()
|
inline |
Definition at line 233 of file cub_helper.cuh.
References __syncthreads(), arg(), count, quda::ColorSpinorField::exchange(), gridDim, fused_exterior_ndeg_tm_dslash_cuda_gen::i, in, isLastBlockDone, sum(), value, and y.
◆ reliable()
| int quda::reliable | ( | double & | rNorm, |
| double & | maxrx, | ||
| double & | maxrr, | ||
| const double & | r2, | ||
| const double & | delta | ||
| ) |
Definition at line 37 of file inv_bicgstab_quda.cpp.
References delta, sqrt(), and updateR().
Referenced by quda::BiCGstab::operator()(), and quda::MultiShiftCG::operator()().
◆ reorder_location()
| QudaFieldLocation quda::reorder_location | ( | ) |
Return whether data is reordered on the CPU or GPU. This can set at QUDA initialization using the environment variable QUDA_REORDER_LOCATION.
- Returns
- Reorder location
Definition at line 585 of file lattice_field.cpp.
References reorder_location_.
Referenced by quda::cudaCloverField::copy(), quda::cudaGaugeField::copy(), quda::cpuGaugeField::copy(), quda::cudaColorSpinorField::loadSpinorField(), quda::cudaGaugeField::saveCPUField(), and quda::cudaColorSpinorField::saveSpinorField().
◆ reorder_location_set()
| void quda::reorder_location_set | ( | QudaFieldLocation | reorder_location_ | ) |
Set whether data is reorderd on the CPU or GPU. This can set at QUDA initialization using the environment variable QUDA_REORDER_LOCATION.
- Parameters
-
reorder_location_ The location to set where data will be reordered
Definition at line 586 of file lattice_field.cpp.
References reorder_location_.
Referenced by initQudaDevice().
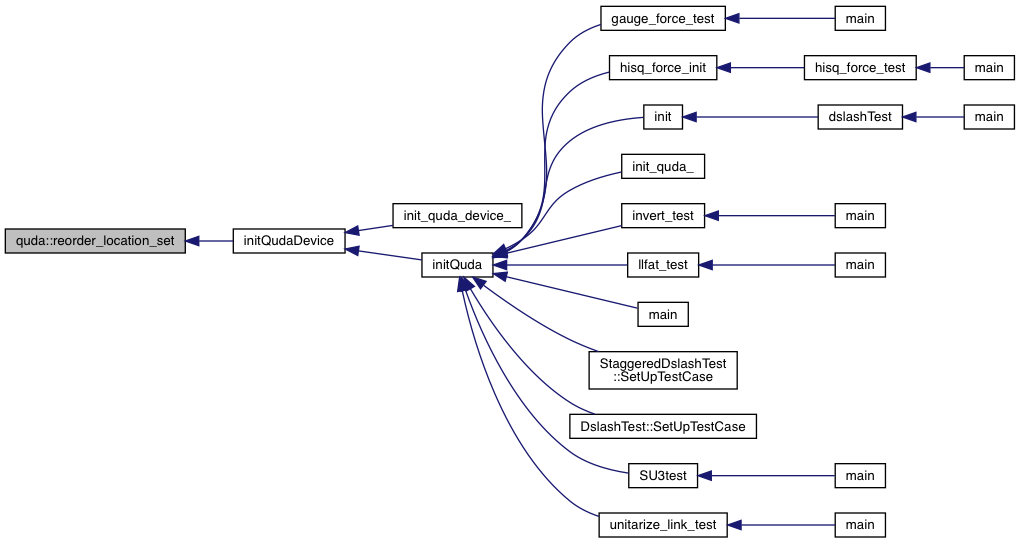
◆ report() [1/2]
|
static |
Definition at line 7 of file eig_solver.cpp.
References getVerbosity(), printfQuda, and QUDA_VERBOSE.
Referenced by quda::Eig_Solver::create(), and quda::Solver::create().

◆ report() [2/2]
|
static |
Definition at line 8 of file solver.cpp.
References getVerbosity(), printfQuda, and QUDA_VERBOSE.
◆ Restrict()
| void quda::Restrict | ( | ColorSpinorField & | out, |
| const ColorSpinorField & | in, | ||
| const ColorSpinorField & | v, | ||
| int | Nvec, | ||
| const int * | fine_to_coarse, | ||
| const int * | coarse_to_fine, | ||
| const int * | spin_map, | ||
| int | parity = QUDA_INVALID_PARITY |
||
| ) |
Apply the restriction operator.
- Parameters
-
[out] out Resulting coarsened field [in] in Input field on fine grid [in] v Matrix field containing the null-space components [in] Nvec Number of null-space components [in] fine_to_coarse Fine-to-coarse lookup table (linear indices) [in] spin_map Spin blocking lookup table [in] parity of the input fine field (if single parity input field)
Definition at line 509 of file restrictor.cu.
References checkPrecision, errorQuda, quda::ColorSpinorField::FieldOrder(), in, out, parity, QUDA_DOUBLE_PRECISION, and QUDA_SINGLE_PRECISION.
Referenced by quda::Transfer::R().

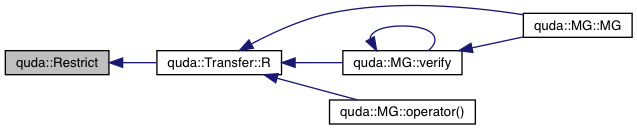
◆ s2d()
|
inlinestatic |
Definition at line 135 of file register_traits.h.
References a, and MAX_SHORT_INV.
◆ s2f()
|
inlinestatic |
Definition at line 134 of file register_traits.h.
References a, and MAX_SHORT_INV.
Referenced by copy().

◆ safe_malloc_()
Perform a standard malloc() with error-checking. This function should only be called via the safe_malloc() macro, defined in malloc_quda.h
Definition at line 219 of file malloc.cpp.
References a, errorQuda, func, HOST, malloc(), memset(), printfQuda, ptr, size, and track_malloc().
◆ saveProfile()
| void quda::saveProfile | ( | const std::string | label = "" | ) |
Save profile to disk.
Definition at line 472 of file tune.cpp.
References comm_rank(), count, ctime(), entry, getenv(), getVerbosity(), gitversion, param, printfQuda, quda_hash, QUDA_SUMMARIZE, quda_version, resource_path, serializeProfile(), serializeTrace(), strcmp(), strncpy(), time(), tmp, trace_list, traceEnabled(), tunecache, and warningQuda.
Referenced by endQuda(), newDeflationQuda(), and newMultigridQuda().
◆ saveTuneCache()
| void quda::saveTuneCache | ( | ) |
Write tunecache to disk.
Definition at line 388 of file tune.cpp.
References comm_rank(), ctime(), getVerbosity(), gitversion, initial_cache_size, printfQuda, quda_hash, QUDA_SUMMARIZE, quda_version, resource_path, serializeTuneCache(), time(), tunecache, and warningQuda.
Referenced by endQuda(), invertMultiShiftQuda(), invertMultiSrcQuda(), invertQuda(), lanczosQuda(), and newMultigridQuda().
◆ serializeProfile()
|
static |
Serialize tunecache to an ostream, useful for writing to a file or sending to other nodes.
Definition at line 181 of file tune.cpp.
References quda::TuneKey::aux, entry, quda::TuneKey::name, out, param, strcmp(), strncpy(), time(), tmp, tunecache, and quda::TuneKey::volume.
Referenced by saveProfile().
◆ serializeTrace()
|
static |
Serialize trace to an ostream, useful for writing to a file or sending to other nodes.
Definition at line 241 of file tune.cpp.
References quda::TuneKey::aux, it, quda::TuneKey::name, out, strcmp(), strncpy(), tmp, trace_list, and quda::TuneKey::volume.
Referenced by saveProfile().
◆ serializeTuneCache()
|
static |
Serialize tunecache to an ostream, useful for writing to a file or sending to other nodes.
Definition at line 154 of file tune.cpp.
References quda::TuneKey::aux, entry, quda::TuneKey::name, out, param, tunecache, and quda::TuneKey::volume.
Referenced by broadcastTuneCache(), and saveTuneCache().
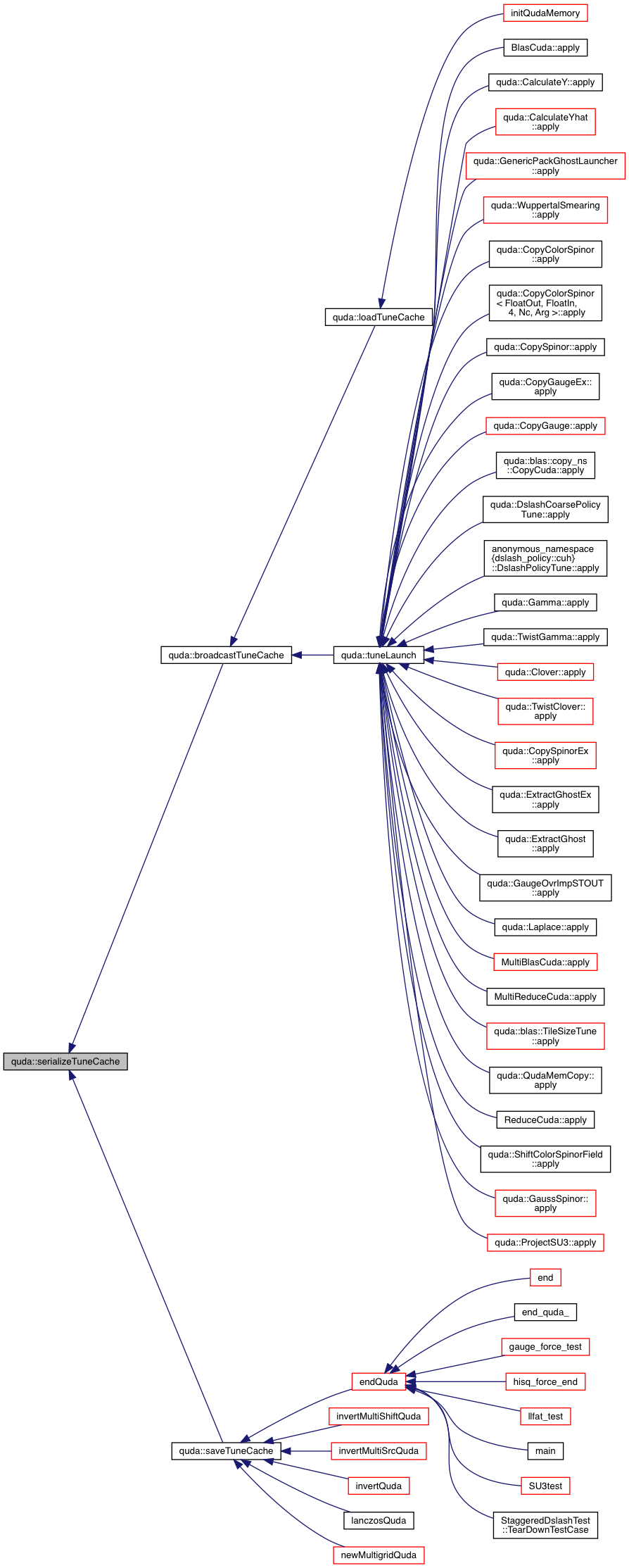
◆ setDiracParam()
| void quda::setDiracParam | ( | DiracParam & | diracParam, |
| QudaInvertParam * | inv_param, | ||
| bool | pc | ||
| ) |
Definition at line 1386 of file interface_quda.cpp.
References quda::GaugeField::Anisotropy(), quda::DiracParam::b_5, QudaInvertParam_s::b_5, quda::DiracParam::c_5, QudaInvertParam_s::c_5, quda::DiracParam::clover, cloverPrecise, quda::DiracParam::commDim, quda::DiracParam::dagger, QudaInvertParam_s::dagger, QudaInvertParam_s::dirac_order, QudaInvertParam_s::dslash_type, quda::DiracParam::epsilon, QudaInvertParam_s::epsilon, errorQuda, quda::DiracParam::fatGauge, quda::DiracParam::gauge, gaugeFatPrecise, gaugeLongPrecise, gaugePrecise, fused_exterior_ndeg_tm_dslash_cuda_gen::i, inv_param, quda::DiracParam::kappa, QudaInvertParam_s::kappa, kappa, quda::DiracParam::longGauge, quda::DiracParam::Ls, QudaInvertParam_s::Ls, quda::DiracParam::m5, QudaInvertParam_s::m5, quda::DiracParam::mass, QudaInvertParam_s::mass, QudaInvertParam_s::matpc_type, quda::DiracParam::matpcType, memcpy(), quda::DiracParam::mu, QudaInvertParam_s::mu, QUDA_ASQTAD_DIRAC, QUDA_ASQTAD_DSLASH, QUDA_ASQTADPC_DIRAC, QUDA_CLOVER_DIRAC, QUDA_CLOVER_WILSON_DSLASH, QUDA_CLOVERPC_DIRAC, QUDA_COVDEV_DSLASH, QUDA_CPS_WILSON_DIRAC_ORDER, QUDA_DOMAIN_WALL_4D_DSLASH, QUDA_DOMAIN_WALL_4DPC_DIRAC, QUDA_DOMAIN_WALL_DIRAC, QUDA_DOMAIN_WALL_DSLASH, QUDA_DOMAIN_WALLPC_DIRAC, QUDA_GAUGE_COVDEV_DIRAC, QUDA_GAUGE_LAPLACE_DIRAC, QUDA_GAUGE_LAPLACEPC_DIRAC, QUDA_LAPLACE_DSLASH, QUDA_MAX_DWF_LS, QUDA_MOBIUS_DOMAIN_WALL_DIRAC, QUDA_MOBIUS_DOMAIN_WALLPC_DIRAC, QUDA_MOBIUS_DWF_DSLASH, QUDA_STAGGERED_DIRAC, QUDA_STAGGERED_DSLASH, QUDA_STAGGEREDPC_DIRAC, QUDA_TWIST_NONDEG_DOUBLET, QUDA_TWIST_SINGLET, QUDA_TWISTED_CLOVER_DIRAC, QUDA_TWISTED_CLOVER_DSLASH, QUDA_TWISTED_CLOVERPC_DIRAC, QUDA_TWISTED_MASS_DIRAC, QUDA_TWISTED_MASS_DSLASH, QUDA_TWISTED_MASSPC_DIRAC, QUDA_WILSON_DIRAC, QUDA_WILSON_DSLASH, QUDA_WILSONPC_DIRAC, QudaInvertParam_s::twist_flavor, and quda::DiracParam::type.
Referenced by cloverQuda(), computeCloverForceQuda(), computeStaggeredForceQuda(), createDirac(), quda::deflated_solver::deflated_solver(), dslashQuda(), dslashQuda_4dpc(), dslashQuda_mdwf(), init(), lanczosQuda(), MatDagMatQuda(), MatQuda(), setDiracPreParam(), and setDiracSloppyParam().
◆ setDiracPreParam()
| void quda::setDiracPreParam | ( | DiracParam & | diracParam, |
| QudaInvertParam * | inv_param, | ||
| const bool | pc, | ||
| bool | comms | ||
| ) |
Definition at line 1485 of file interface_quda.cpp.
References quda::DiracParam::clover, cloverPrecondition, quda::DiracParam::commDim, QudaInvertParam_s::dslash_type, QudaInvertParam_s::dslash_type_precondition, quda::DiracParam::fatGauge, quda::DiracParam::gauge, gaugeExtended, gaugeFatExtended, gaugeFatPrecondition, gaugeLongExtended, gaugeLongPrecondition, gaugePrecondition, fused_exterior_ndeg_tm_dslash_cuda_gen::i, inv_param, QudaInvertParam_s::inv_type, quda::DiracParam::longGauge, QudaInvertParam_s::overlap, QUDA_ASQTAD_DSLASH, QUDA_PCG_INVERTER, QUDA_STAGGERED_DIRAC, QUDA_STAGGERED_DSLASH, QUDA_STAGGEREDPC_DIRAC, setDiracParam(), and quda::DiracParam::type.
Referenced by createDirac(), quda::multigrid_solver::multigrid_solver(), and updateMultigridQuda().

◆ setDiracSloppyParam()
| void quda::setDiracSloppyParam | ( | DiracParam & | diracParam, |
| QudaInvertParam * | inv_param, | ||
| bool | pc | ||
| ) |
Definition at line 1469 of file interface_quda.cpp.
References quda::DiracParam::clover, cloverSloppy, quda::DiracParam::commDim, quda::DiracParam::fatGauge, quda::DiracParam::gauge, gaugeFatSloppy, gaugeLongSloppy, gaugeSloppy, fused_exterior_ndeg_tm_dslash_cuda_gen::i, inv_param, quda::DiracParam::longGauge, and setDiracParam().
Referenced by createDirac(), quda::deflated_solver::deflated_solver(), quda::multigrid_solver::multigrid_solver(), and updateMultigridQuda().

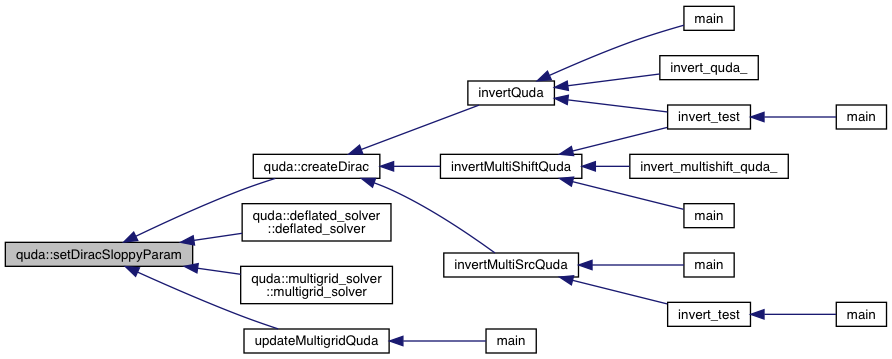
◆ setIdentity() [1/3]
|
inline |
Definition at line 543 of file quda_matrix.h.
References fused_exterior_ndeg_tm_dslash_cuda_gen::i.
Referenced by bdSVD(), computeOvrImpSTOUTStep(), constructHHMat(), exponentiate_iQ(), getRealBidiagMatrix(), and smallSVD().
◆ setIdentity() [2/3]
|
inline |
Definition at line 559 of file quda_matrix.h.
References fused_exterior_ndeg_tm_dslash_cuda_gen::i.
◆ setIdentity() [3/3]
|
inline |
Definition at line 575 of file quda_matrix.h.
References fused_exterior_ndeg_tm_dslash_cuda_gen::i.
◆ setKernelPackT()
| void quda::setKernelPackT | ( | bool | pack | ) |
- Parameters
-
pack Sets whether to use a kernel to pack the T dimension
Definition at line 59 of file dslash_quda.cu.
References kernelPackT.
Referenced by anonymous_namespace{dslash_policy.cuh}::DslashPolicyTune::apply(), anonymous_namespace{dslash_policy.cuh}::DslashPolicyTune::DslashPolicyTune(), dslashQuda(), dslashQuda_4dpc(), dslashQuda_mdwf(), quda::cudaColorSpinorField::exchangeGhost(), init(), invertMultiShiftQuda(), invertMultiSrcQuda(), invertQuda(), lanczosQuda(), MatDagMatQuda(), MatQuda(), set_kernel_pack_t_(), and twistedMassDslashCuda().
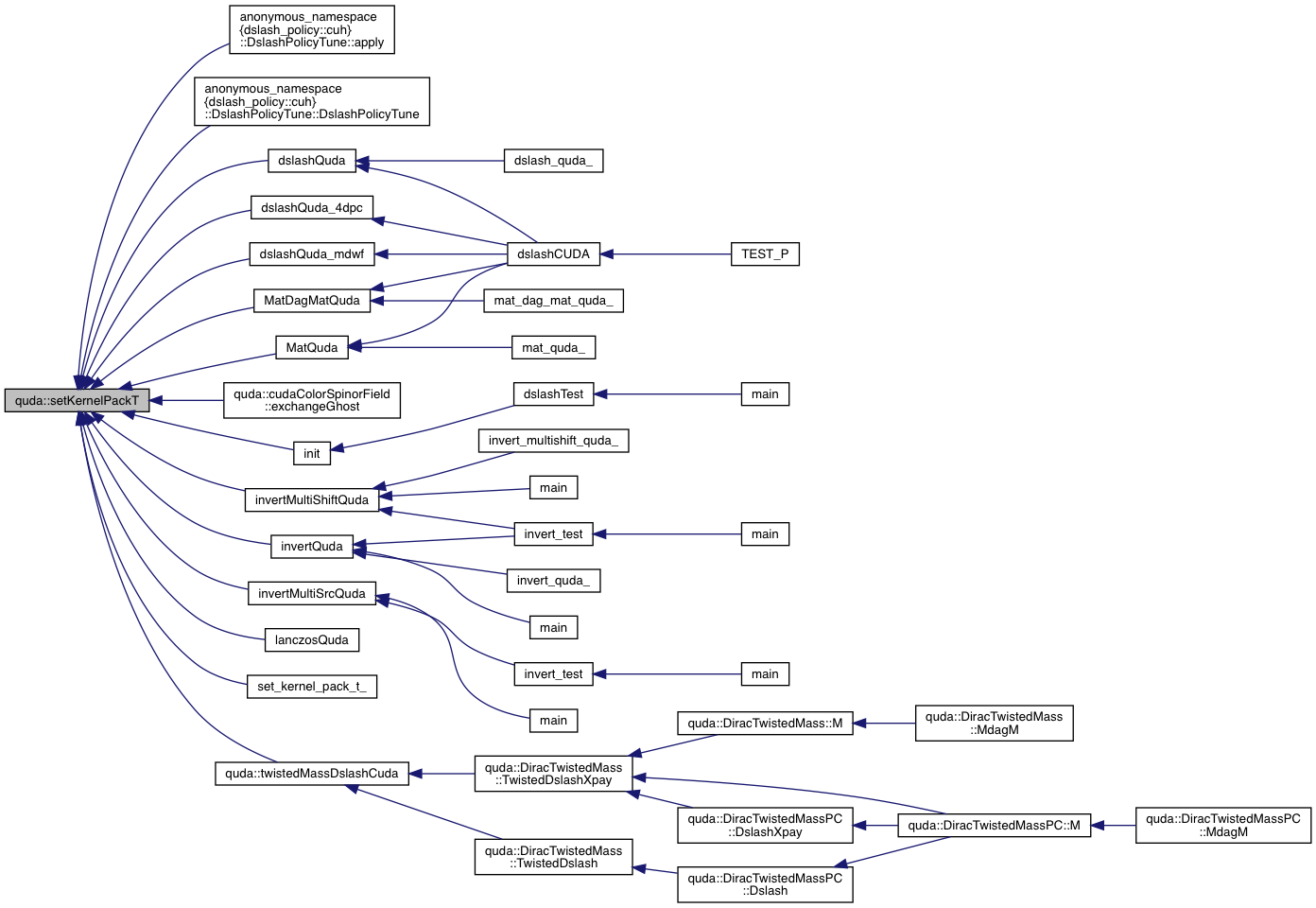
◆ setPackComms()
| void quda::setPackComms | ( | const int * | commDim | ) |
Sets commDim array used in dslash_pack.cu
Definition at line 41 of file dslash_pack.cu.
Referenced by DslashCuda::DslashCuda().

◆ setPolicyTuning()
| void quda::setPolicyTuning | ( | bool | policy_tuning_ | ) |
Definition at line 457 of file tune.cpp.
References policy_tuning.
Referenced by quda::DslashCoarsePolicyTune::DslashCoarsePolicyTune(), anonymous_namespace{dslash_policy.cuh}::DslashPolicyTune::DslashPolicyTune(), quda::blas::TileSizeTune< ReducerDiagonal, writeDiagonal, ReducerOffDiagonal, writeOffDiagonal >::TileSizeTune(), quda::DslashCoarsePolicyTune::~DslashCoarsePolicyTune(), anonymous_namespace{dslash_policy.cuh}::DslashPolicyTune::~DslashPolicyTune(), and quda::blas::TileSizeTune< ReducerDiagonal, writeDiagonal, ReducerOffDiagonal, writeOffDiagonal >::~TileSizeTune().
◆ setTransferGPU()
| void quda::setTransferGPU | ( | bool | ) |
◆ setUnitarizeLinksConstants()
| void quda::setUnitarizeLinksConstants | ( | double | unitarize_eps, |
| double | max_error, | ||
| bool | allow_svd, | ||
| bool | svd_only, | ||
| double | svd_rel_error, | ||
| double | svd_abs_error | ||
| ) |
Referenced by computeKSLinkQuda(), GaugeAlgTest::SetReunitarizationConsts(), setReunitarizationConsts(), and unitarize_link_test().
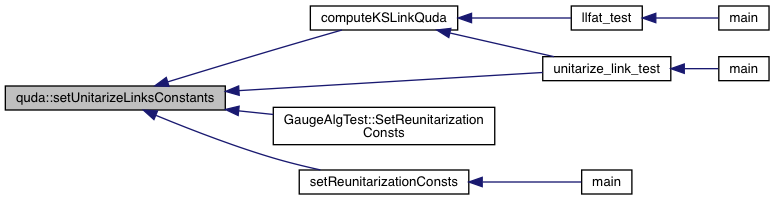
◆ setZero() [1/3]
|
inline |
Definition at line 592 of file quda_matrix.h.
References fused_exterior_ndeg_tm_dslash_cuda_gen::i.
Referenced by computeStapleRectangle(), and exponentiate_iQ().

◆ setZero() [2/3]
|
inline |
Definition at line 607 of file quda_matrix.h.
References fused_exterior_ndeg_tm_dslash_cuda_gen::i.
◆ setZero() [3/3]
|
inline |
Definition at line 622 of file quda_matrix.h.
References fused_exterior_ndeg_tm_dslash_cuda_gen::i.
◆ shiftColorSpinorField()
| void quda::shiftColorSpinorField | ( | cudaColorSpinorField & | dst, |
| const cudaColorSpinorField & | src, | ||
| const unsigned int | parity, | ||
| const unsigned int | dim, | ||
| const int | shift | ||
| ) |
Definition at line 207 of file shift_quark_field.cu.
References arg(), commDimPartitioned(), deg_tm_dslash_cuda_gen::dagger, dim, errorQuda, quda::ColorSpinorField::Even(), dslash::gatherEnd, quda::ColorSpinorField::Odd(), offset, dslash::packEnd, parity, quda::LatticeField::Precision(), QUDA_BACKWARDS, QUDA_CPU_FIELD_LOCATION, QUDA_DOUBLE_PRECISION, QUDA_FORWARDS, QUDA_FULL_SITE_SUBSET, QUDA_SINGLE_PRECISION, qudaEventRecord(), qudaStreamWaitEvent(), dslash::scatterEnd, shift, quda::ColorSpinorField::SiteSubset(), src, and streams.
◆ shiftColorSpinorFieldExternalKernel()
| __global__ void quda::shiftColorSpinorFieldExternalKernel | ( | ShiftQuarkArg< Output, Input > | arg | ) |

◆ shiftColorSpinorFieldKernel()
| __global__ void quda::shiftColorSpinorFieldKernel | ( | ShiftQuarkArg< Output, Input > | arg | ) |
Definition at line 68 of file shift_quark_field.cu.
References arg(), blockDim, gridDim, idx, neighborIndex(), shift, and x.

◆ sin() [1/4]
|
inline |
Definition at line 40 of file complex_quda.h.
Referenced by cos(), cosh(), exponentiate_iQ(), genericSource(), genGauss(), new_load_half(), polar(), polarSu3(), quda::Trig< isHalf, T >::Sin(), sin(), quda::Trig< isHalf, T >::SinCos(), sinh(), and tan().
◆ sin() [2/4]
◆ sin() [3/4]
|
inline |
◆ sin() [4/4]
◆ sinh() [1/3]
|
inline |
◆ sinh() [2/3]
|
inline |
◆ sinh() [3/3]
◆ siteChecksum()
|
inline |
Definition at line 17 of file checksum.cu.
References arg(), quda::Matrix< T, N >::checksum(), d, nColor, and parity.
Referenced by ChecksumCPU().


◆ solve()
| void quda::solve | ( | Complex * | psi, |
| std::vector< ColorSpinorField *> & | p, | ||
| std::vector< ColorSpinorField *> & | q, | ||
| ColorSpinorField & | b | ||
| ) |
Solve the equation A p_k psi_k = b by minimizing the residual and using Gaussian elimination.
- Parameters
-
psi[out] Array of coefficients p[in] Search direction vectors q[in] Search direction vectors with the operator applied
Definition at line 64 of file inv_mre.cpp.
References abs(), b, quda::blas::cDotProduct(), conj(), fused_exterior_ndeg_tm_dslash_cuda_gen::i, and p.
Referenced by invertMultiSrcQuda(), invertQuda(), and quda::MinResExt::operator()().
◆ spinorGauss() [1/2]
| void quda::spinorGauss | ( | ColorSpinorField & | src, |
| int | seed | ||
| ) |
Definition at line 149 of file spinor_gauss.cu.
References quda::RNG::Init(), quda::RNG::Release(), and src.
◆ spinorGauss() [2/2]
| void quda::spinorGauss | ( | ColorSpinorField & | src, |
| RNG & | randstates | ||
| ) |
Definition at line 126 of file spinor_gauss.cu.
References errorQuda, QUDA_DOUBLE_PRECISION, QUDA_SINGLE_PRECISION, and src.
◆ sqrt() [1/3]
|
inline |
Definition at line 105 of file complex_quda.h.
Referenced by acosh(), asinh(), quda::linalg::Cholesky< Mat, T, N, fast >::Cholesky(), quda::IncEigCG::eigCGsolve(), exponentiate_iQ(), quda::GMResDR::FlexArnoldiProcedure(), quda::MG::generateNullVectors(), genGauss(), quda::Deflation::increment(), invertMultiShiftQuda(), invertMultiSrcQuda(), invertQuda(), l2(), new_save_half(), quda::Lanczos::operator()(), quda::Deflation::operator()(), quda::CG::operator()(), quda::CGNR::operator()(), quda::MPCG::operator()(), quda::PreconCG::operator()(), quda::BiCGstab::operator()(), quda::SimpleBiCGstab::operator()(), quda::MPBiCGstab::operator()(), quda::BiCGstabL::operator()(), quda::GCR::operator()(), quda::MR::operator()(), quda::SD::operator()(), quda::MultiShiftCG::operator()(), quda::MinResExt::operator()(), quda::IncEigCG::operator()(), quda::GMResDR::operator()(), quda::Solver::PrintStats(), quda::Solver::PrintSummary(), quda::Deflation::reduce(), reliable(), quda::BiCGstabL::reliable(), quda::GMResDR::RestartVZH(), quda::CG::solve(), sqrt(), test(), quda::gauge::Reconstruct< 8, Float >::Unpack(), quda::Deflation::verify(), and quda::MG::verify().
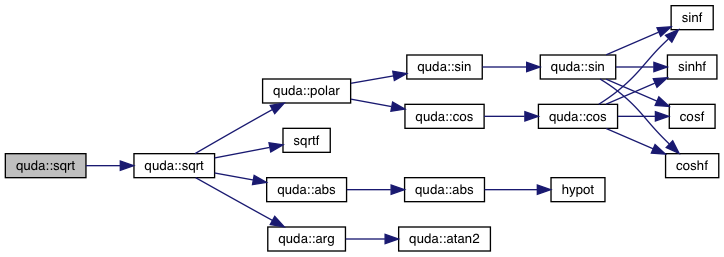
◆ sqrt() [2/3]
|
inline |
◆ sqrt() [3/3]
◆ staggeredDslashCuda()
| void quda::staggeredDslashCuda | ( | cudaColorSpinorField * | out, |
| const cudaGaugeField & | gauge, | ||
| const cudaColorSpinorField * | in, | ||
| const int | parity, | ||
| const int | dagger, | ||
| const cudaColorSpinorField * | x, | ||
| const double & | k, | ||
| const int * | commDim, | ||
| TimeProfile & | profile | ||
| ) |
Definition at line 152 of file dslash_staggered.cu.
References deg_tm_dslash_cuda_gen::dagger, deg_tm_dslash_cuda_gen::dslash, errorQuda, fused_exterior_ndeg_tm_dslash_cuda_gen::i, in, out, parity, QUDA_DOUBLE_PRECISION, QUDA_HALF_PRECISION, QUDA_MAX_DIM, QUDA_SINGLE_PRECISION, and x.
Referenced by quda::DiracStaggered::Dslash(), and quda::DiracStaggered::DslashXpay().
◆ store_streaming_double2()
Definition at line 49 of file inline_ptx.h.
Referenced by vector_store().

◆ store_streaming_float2()
Definition at line 54 of file inline_ptx.h.
Referenced by vector_store().

◆ store_streaming_float4()
|
inline |
Definition at line 39 of file inline_ptx.h.
References __PTR, w, x, y, and z.
Referenced by vector_store().

◆ store_streaming_short2()
|
inline |
Definition at line 59 of file inline_ptx.h.
Referenced by vector_store().

◆ store_streaming_short4()
|
inline |
Definition at line 44 of file inline_ptx.h.
References __PTR, w, x, y, and z.
Referenced by vector_store().

◆ STOUTStep()
| void quda::STOUTStep | ( | GaugeField & | dataDs, |
| const GaugeField & | dataOr, | ||
| double | rho | ||
| ) |
Apply STOUT smearing to the gauge field
- Parameters
-
dataDs Output smeared field dataOr Input gauge field rho smearing parameter
Definition at line 300 of file gauge_stout.cu.
References errorQuda, float, quda::GaugeField::isNative(), quda::GaugeField::Order(), quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, QUDA_HALF_PRECISION, QUDA_SINGLE_PRECISION, and quda::GaugeField::Reconstruct().
Referenced by performSTOUTnStep().
◆ str_end()
|
inline |
Definition at line 45 of file malloc_quda.h.
Referenced by file_name().

◆ str_slant()
|
inline |
Definition at line 46 of file malloc_quda.h.
Referenced by file_name().

◆ SubTraceUnit()
|
inline |
Definition at line 1015 of file quda_matrix.h.
References a.
◆ tan() [1/2]
|
inline |
◆ tan() [2/2]
|
inline |

◆ tanh() [1/2]
|
inline |

◆ tanh() [2/2]
|
inline |
Definition at line 1068 of file complex_quda.h.
Referenced by tanh().

◆ timeInterval()
Definition at line 18 of file inv_gcr_quda.cpp.
◆ traceEnabled()
| bool quda::traceEnabled | ( | ) |
Definition at line 75 of file tune.cpp.
References enable_trace, getenv(), quda::blas::init(), and strcmp().
Referenced by saveProfile(), and tuneLaunch().
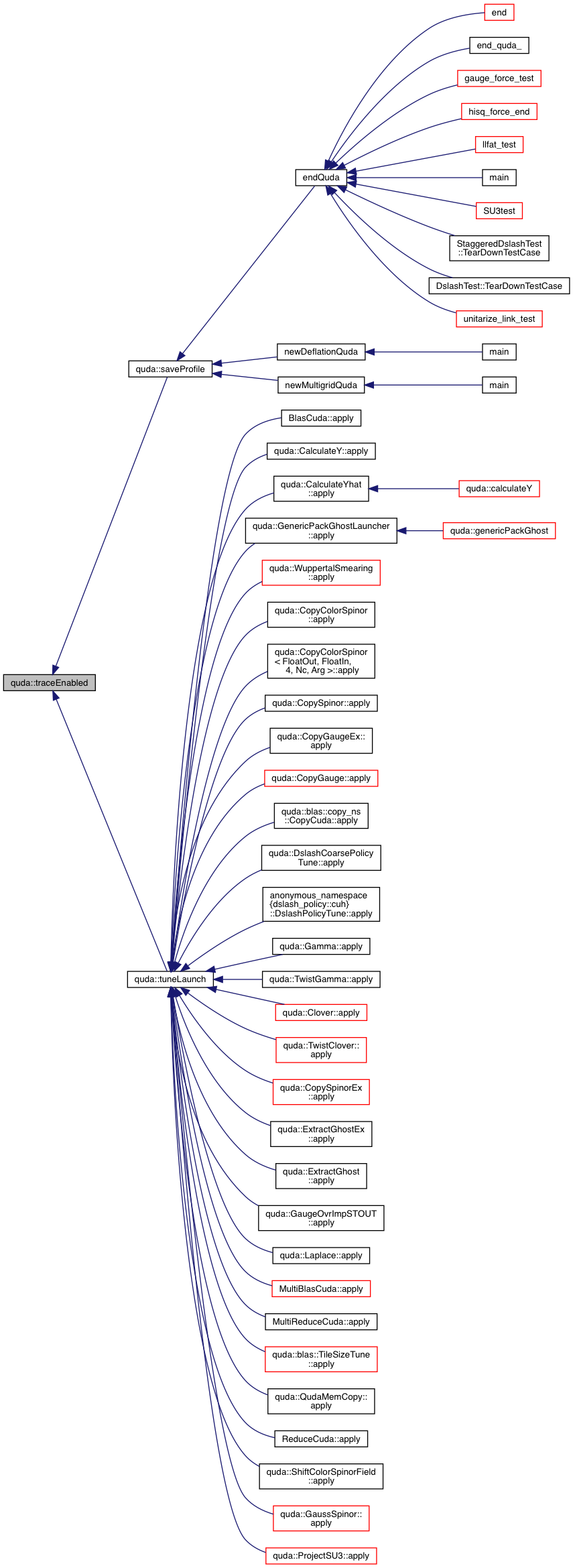
◆ track_free()
|
static |
Definition at line 119 of file malloc.cpp.
References alloc, DEVICE, MAPPED, PINNED, ptr, size, total_bytes, total_host_bytes, and total_pinned_bytes.
Referenced by device_free_(), device_pinned_free_(), and host_free_().
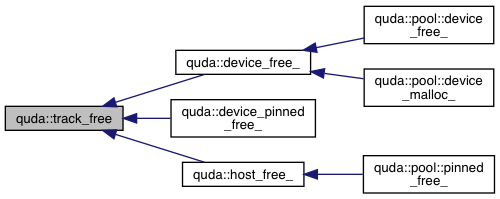
◆ track_malloc()
Definition at line 97 of file malloc.cpp.
References a, alloc, DEVICE, MAPPED, max_total_bytes, max_total_host_bytes, max_total_pinned_bytes, PINNED, ptr, total_bytes, total_host_bytes, and total_pinned_bytes.
Referenced by device_malloc_(), device_pinned_malloc_(), mapped_malloc_(), pinned_malloc_(), and safe_malloc_().
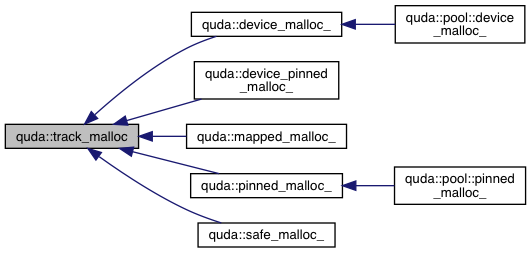
◆ tuneLaunch()
| TuneParam & quda::tuneLaunch | ( | Tunable & | tunable, |
| QudaTune | enabled, | ||
| QudaVerbosity | verbosity | ||
| ) |
Return the optimal launch parameters for a given kernel, either by retrieving them from tunecache or autotuning on the spot.
Definition at line 603 of file tune.cpp.
References quda::Tunable::advanceTuneParam(), quda::Tunable::apply(), quda::TuneKey::aux, broadcastTuneCache(), quda::Tunable::checkLaunchParam(), comm_rank(), quda::TuneParam::comment, commGlobalReduction(), ctime(), quda::Tunable::defaultTuneParam(), end, errorQuda, fused_exterior_ndeg_tm_dslash_cuda_gen::i, quda::Tunable::initTuneParam(), it, last_key, launchTimer, quda::TuneKey::name, param, quda::Tunable::paramString(), quda::Tunable::perfString(), policyTuning(), quda::Tunable::postTune(), quda::Tunable::preTune(), printfQuda, profile_count, QUDA_DEBUG_VERBOSE, QUDA_PROFILE_COMPUTE, QUDA_PROFILE_EPILOGUE, QUDA_PROFILE_INIT, QUDA_PROFILE_PREAMBLE, QUDA_PROFILE_TOTAL, QUDA_TUNE_NO, QUDA_TUNE_YES, QUDA_VERBOSE, start, quda::TuneParam::time, time(), trace_list, traceEnabled(), tunecache, quda::Tunable::tuneKey(), tuning, quda::Tunable::tuningIter(), verbosity, and quda::TuneKey::volume.
Referenced by quda::CopySpinor< FloatOut, FloatIn, Ns, Nc, OutOrder, InOrder >::apply(), quda::QudaMemCopy::apply(), quda::blas::copy_ns::CopyCuda< FloatN, N, Output, Input >::apply(), quda::GaussSpinor< FloatIn, Ns, Nc, InOrder >::apply(), BlasCuda< FloatN, M, SpinorX, SpinorY, SpinorZ, SpinorW, Functor >::apply(), quda::CopyGaugeEx< FloatOut, FloatIn, length, OutOrder, InOrder >::apply(), quda::GenericPackGhostLauncher< Float, Ns, Ms, Nc, Mc, Arg >::apply(), ReduceCuda< doubleN, ReduceType, FloatN, M, SpinorX, SpinorY, SpinorZ, SpinorW, SpinorV, Reducer >::apply(), quda::ShiftColorSpinorField< Output, Input >::apply(), quda::CopyColorSpinor< FloatOut, FloatIn, Ns, Nc, Arg >::apply(), quda::WuppertalSmearing< Float, Ns, Nc, Arg >::apply(), MultiBlasCuda< NXZ, FloatN, M, SpinorX, SpinorY, SpinorZ, SpinorW, Functor >::apply(), quda::Laplace< Float, nDim, nColor, Arg >::apply(), quda::ExtractGhost< Float, length, nDim, Order >::apply(), quda::ExtractGhostEx< Float, length, nDim, dim, Order >::apply(), quda::CopyGauge< FloatOut, FloatIn, length, OutOrder, InOrder, isGhost >::apply(), quda::CopyColorSpinor< FloatOut, FloatIn, 4, Nc, Arg >::apply(), quda::Gamma< ValueType, basis, dir >::apply(), quda::CopySpinorEx< FloatOut, FloatIn, Ns, Nc, OutOrder, InOrder, Basis, extend >::apply(), MultiReduceCuda< NXZ, doubleN, ReduceType, FloatN, M, SpinorX, SpinorY, SpinorZ, SpinorW, Reducer >::apply(), quda::TwistGamma< Float, nColor, Arg >::apply(), quda::blas::TileSizeTune< ReducerDiagonal, writeDiagonal, ReducerOffDiagonal, writeOffDiagonal >::apply(), quda::Clover< Float, nSpin, nColor, Arg >::apply(), quda::ProjectSU3< Float, G >::apply(), quda::TwistClover< Float, nSpin, nColor, Arg >::apply(), quda::GaugeOvrImpSTOUT< Float, GaugeOr, GaugeDs >::apply(), quda::DslashCoarsePolicyTune::apply(), quda::CalculateY< from_coarse, Float, fineSpin, fineColor, coarseSpin, coarseColor, Arg >::apply(), quda::CalculateYhat< Float, n, Arg >::apply(), and anonymous_namespace{dslash_policy.cuh}::DslashPolicyTune::apply().
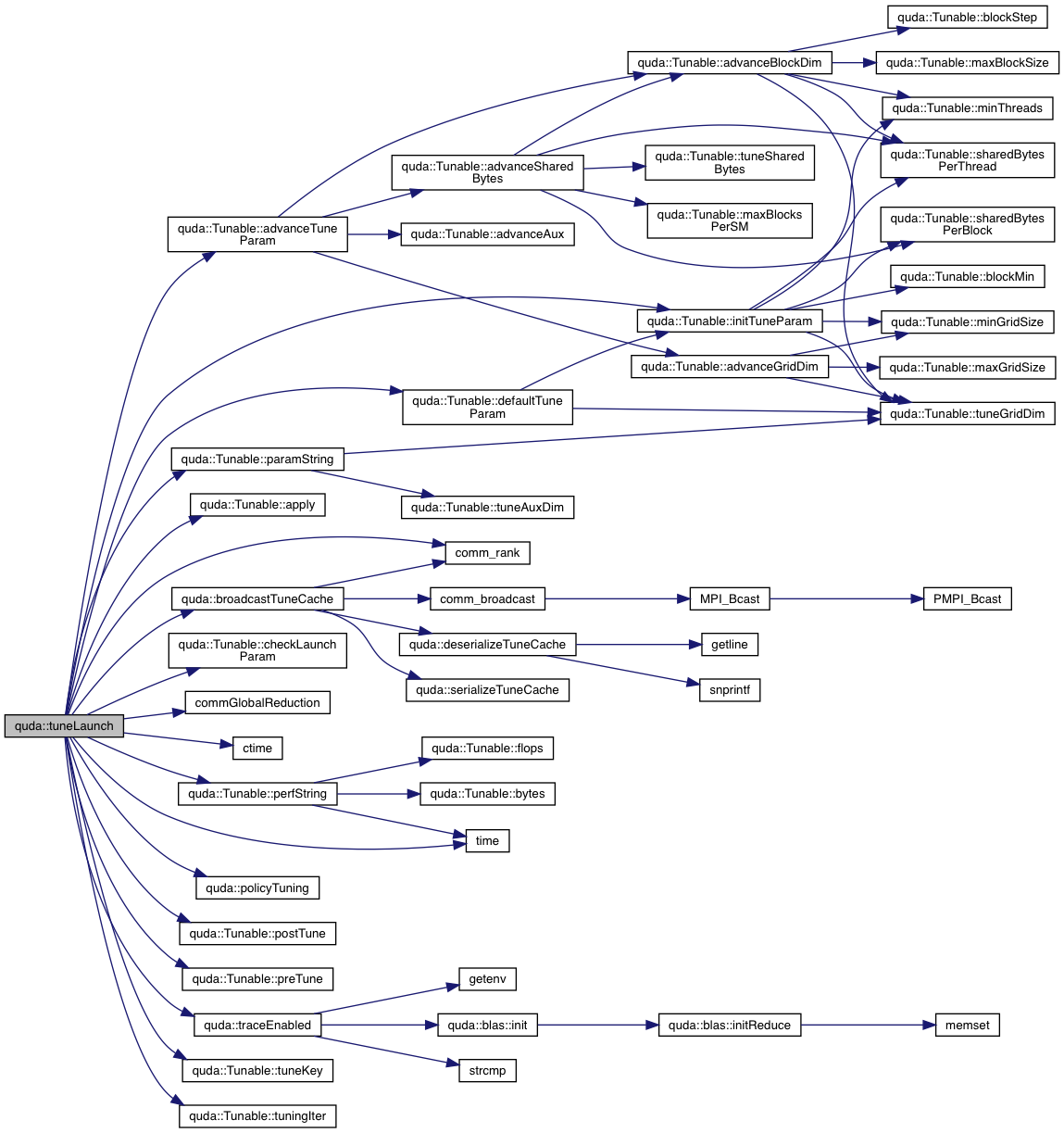
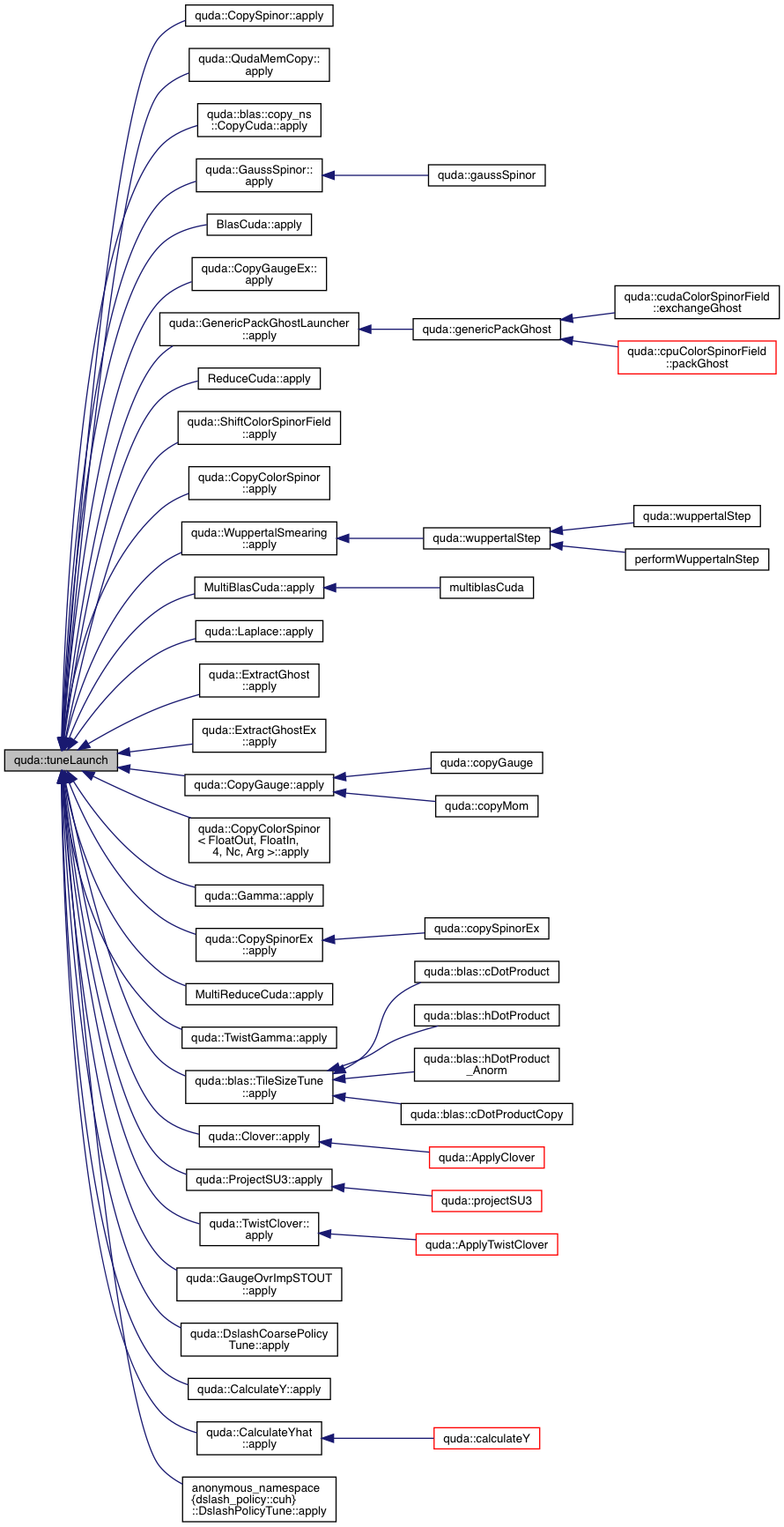
◆ twistCloverApply()

◆ twistCloverCPU()
| void quda::twistCloverCPU | ( | Arg & | arg | ) |
Definition at line 648 of file dslash_quda.cu.
References arg(), for(), and parity.

◆ twistCloverGPU()
| __global__ void quda::twistCloverGPU | ( | Arg | arg | ) |

◆ twistedCloverDslashCuda()
| void quda::twistedCloverDslashCuda | ( | cudaColorSpinorField * | out, |
| const cudaGaugeField & | gauge, | ||
| const FullClover * | clover, | ||
| const FullClover * | cloverInv, | ||
| const cudaColorSpinorField * | in, | ||
| const int | parity, | ||
| const int | dagger, | ||
| const cudaColorSpinorField * | x, | ||
| const QudaTwistCloverDslashType | type, | ||
| const double & | kappa, | ||
| const double & | mu, | ||
| const double & | epsilon, | ||
| const double & | k, | ||
| const int * | commDim, | ||
| TimeProfile & | profile | ||
| ) |
Definition at line 215 of file dslash_twisted_clover.cu.
References dslash_cuda_gen::clover, deg_tm_dslash_cuda_gen::dagger, deg_tm_dslash_cuda_gen::dslash, errorQuda, fused_exterior_ndeg_tm_dslash_cuda_gen::i, in, kappa, mu, out, parity, QUDA_DOUBLE_PRECISION, QUDA_HALF_PRECISION, QUDA_SINGLE_PRECISION, QUDA_TWIST_SINGLET, and x.
Referenced by quda::DiracTwistedCloverPC::Dslash(), quda::DiracTwistedCloverPC::DslashXpay(), quda::DiracTwistedClover::M(), and quda::DiracTwistedCloverPC::M().
◆ twistedMassDslashCuda()
| void quda::twistedMassDslashCuda | ( | cudaColorSpinorField * | out, |
| const cudaGaugeField & | gauge, | ||
| const cudaColorSpinorField * | in, | ||
| const int | parity, | ||
| const int | dagger, | ||
| const cudaColorSpinorField * | x, | ||
| const QudaTwistDslashType | type, | ||
| const double & | kappa, | ||
| const double & | mu, | ||
| const double & | epsilon, | ||
| const double & | k, | ||
| const int * | commDim, | ||
| TimeProfile & | profile | ||
| ) |
Definition at line 169 of file dslash_twisted_mass.cu.
References deg_tm_dslash_cuda_gen::dagger, deg_tm_dslash_cuda_gen::dslash, errorQuda, in, kappa, mu, out, parity, QUDA_DEG_TWIST_INV_DSLASH, QUDA_DOUBLE_PRECISION, QUDA_HALF_PRECISION, QUDA_SINGLE_PRECISION, setKernelPackT(), and x.
Referenced by quda::DiracTwistedMass::TwistedDslash(), and quda::DiracTwistedMass::TwistedDslashXpay().


◆ twistGammaCPU()
| void quda::twistGammaCPU | ( | Arg | arg | ) |
Definition at line 300 of file dslash_quda.cu.
References arg(), in, and parity.

◆ twistGammaGPU()
| __global__ void quda::twistGammaGPU | ( | Arg | arg | ) |

◆ u32toa()
|
inline |
Definition at line 45 of file uint_to_char.h.
References a, b, c, gDigitsLut, fused_exterior_ndeg_tm_dslash_cuda_gen::i, and value.
Referenced by i32toa().

◆ u64toa()
|
inline |
Definition at line 127 of file uint_to_char.h.
References a, b, c, gDigitsLut, fused_exterior_ndeg_tm_dslash_cuda_gen::i, and value.
Referenced by i64toa(), quda::blas::TileSizeTune< ReducerDiagonal, writeDiagonal, ReducerOffDiagonal, writeOffDiagonal >::TileSizeTune(), and quda::QudaMemCopy::tuneKey().
◆ unitarizeLinks() [1/2]
| void quda::unitarizeLinks | ( | cudaGaugeField & | outfield, |
| const cudaGaugeField & | infield, | ||
| int * | fails | ||
| ) |
Definition at line 495 of file unitarize_links_quda.cu.
References errorQuda, quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, and QUDA_SINGLE_PRECISION.
Referenced by GaugeAlgTest::CallUnitarizeLinks(), CallUnitarizeLinks(), computeKSLinkQuda(), unitarize_link_test(), and unitarizeLinks().

◆ unitarizeLinks() [2/2]
| void quda::unitarizeLinks | ( | cudaGaugeField & | outfield, |
| int * | fails | ||
| ) |
Definition at line 512 of file unitarize_links_quda.cu.
References links, and unitarizeLinks().

◆ unitarizeLinksCPU()
| void quda::unitarizeLinksCPU | ( | cpuGaugeField & | outfield, |
| const cpuGaugeField & | infield | ||
| ) |

◆ updateAlphaZeta()
| void quda::updateAlphaZeta | ( | double * | alpha, |
| double * | zeta, | ||
| double * | zeta_old, | ||
| const double * | r2, | ||
| const double * | beta, | ||
| const double | pAp, | ||
| const double * | offset, | ||
| const int | nShift, | ||
| const int | j_low | ||
| ) |
Compute the new values of alpha and zeta
Definition at line 127 of file inv_multi_cg_quda.cpp.
References offset, and QUDA_MAX_MULTI_SHIFT.
Referenced by quda::MultiShiftCG::operator()().

◆ updateAp()
| void quda::updateAp | ( | Complex ** | beta, |
| std::vector< ColorSpinorField *> | Ap, | ||
| int | begin, | ||
| int | size, | ||
| int | k | ||
| ) |
Definition at line 70 of file inv_gcr_quda.cpp.
References quda::blas::caxpy(), fused_exterior_ndeg_tm_dslash_cuda_gen::i, and size.
Referenced by orthoDir().


◆ updateGaugeField()
| void quda::updateGaugeField | ( | GaugeField & | out, |
| double | dt, | ||
| const GaugeField & | in, | ||
| const GaugeField & | mom, | ||
| bool | conj_mom, | ||
| bool | exact | ||
| ) |
Evolve the gauge field by step size dt using the momentuim field
- Parameters
-
out Updated gauge field dt Step size in Input gauge field mom Momentum field conj_mom Whether we conjugate the momentum in the exponential exact Calculate exact exponential or use an expansion
Definition at line 308 of file gauge_update_quda.cu.
References errorQuda, in, quda::LatticeField::Location(), out, quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, and QUDA_SINGLE_PRECISION.
Referenced by updateGaugeFieldQuda().
◆ updateMomentum()
| void quda::updateMomentum | ( | GaugeField & | mom, |
| double | coeff, | ||
| GaugeField & | force | ||
| ) |
Update the momentum field from the force field
mom = mom - coeff * [force]_TA
where [A]_TA means the traceless anti-hermitian projection of A
- Parameters
-
mom Momentum field force Force field
Definition at line 224 of file momentum.cu.
References checkCudaError, dw_dslash_4D_cuda_gen::coeff(), errorQuda, quda::GaugeField::Order(), quda::LatticeField::Precision(), QUDA_DOUBLE_PRECISION, and QUDA_FLOAT2_GAUGE_ORDER.
Referenced by computeCloverForceQuda(), computeHISQForceQuda(), and computeStaggeredForceQuda().

◆ updateSolution()
| void quda::updateSolution | ( | ColorSpinorField & | x, |
| const Complex * | alpha, | ||
| Complex **const | beta, | ||
| double * | gamma, | ||
| int | k, | ||
| std::vector< ColorSpinorField *> | p | ||
| ) |
Definition at line 141 of file inv_gcr_quda.cpp.
References backSubs(), quda::blas::caxpy(), delta, gamma(), fused_exterior_ndeg_tm_dslash_cuda_gen::i, p, X, and x.
Referenced by quda::GCR::operator()().

◆ vector_load()
|
inline |
Definition at line 275 of file register_traits.h.
◆ vector_store() [1/6]
|
inline |
Definition at line 285 of file register_traits.h.
References idx, ptr, and value.
Referenced by quda::clover::FloatNOrder< Float, length, N, huge_alloc >::save(), quda::colorspinor::FloatNOrder< Float, Ns, Nc, N, huge_alloc >::save(), quda::gauge::FloatNOrder< Float, length, N, reconLenParam, stag_phase, huge_alloc >::save(), quda::colorspinor::FloatNOrder< Float, Ns, Nc, N, huge_alloc >::saveGhost(), quda::gauge::FloatNOrder< Float, length, N, reconLenParam, stag_phase, huge_alloc >::saveGhost(), and quda::gauge::FloatNOrder< Float, length, N, reconLenParam, stag_phase, huge_alloc >::saveGhostEx().
◆ vector_store() [2/6]
|
inline |
Definition at line 290 of file register_traits.h.
References idx, ptr, store_streaming_double2(), and value.

◆ vector_store() [3/6]
|
inline |
Definition at line 299 of file register_traits.h.
References idx, ptr, store_streaming_float4(), and value.

◆ vector_store() [4/6]
|
inline |
Definition at line 308 of file register_traits.h.
References idx, ptr, store_streaming_float2(), and value.

◆ vector_store() [5/6]
|
inline |
Definition at line 317 of file register_traits.h.
References idx, ptr, store_streaming_short4(), and value.

◆ vector_store() [6/6]
|
inline |
Definition at line 326 of file register_traits.h.
References idx, ptr, store_streaming_short2(), and value.

◆ wilsonDslashCuda()
| void quda::wilsonDslashCuda | ( | cudaColorSpinorField * | out, |
| const cudaGaugeField & | gauge, | ||
| const cudaColorSpinorField * | in, | ||
| const int | oddBit, | ||
| const int | daggerBit, | ||
| const cudaColorSpinorField * | x, | ||
| const double & | k, | ||
| const int * | commDim, | ||
| TimeProfile & | profile | ||
| ) |
Definition at line 108 of file dslash_wilson.cu.
References deg_tm_dslash_cuda_gen::dagger, deg_tm_dslash_cuda_gen::dslash, errorQuda, in, out, parity, QUDA_DOUBLE_PRECISION, QUDA_HALF_PRECISION, QUDA_SINGLE_PRECISION, and x.
Referenced by quda::DiracWilson::Dslash(), and quda::DiracWilson::DslashXpay().
◆ writeLinkVariableToArray() [1/2]
|
inline |
Definition at line 816 of file quda_matrix.h.
References array, quda::Matrix< T, N >::data, fused_exterior_ndeg_tm_dslash_cuda_gen::i, and idx.
◆ writeLinkVariableToArray() [2/2]
|
inline |
Definition at line 829 of file quda_matrix.h.
References array, fused_exterior_ndeg_tm_dslash_cuda_gen::i, and idx.
◆ writeMatrixToArray()
|
inline |
Definition at line 785 of file quda_matrix.h.
References array, fused_exterior_ndeg_tm_dslash_cuda_gen::i, idx, and mat().
◆ writeMomentumToArray()
|
inline |
Definition at line 881 of file quda_matrix.h.
References array, dw_dslash_4D_cuda_gen::coeff(), quda::Matrix< T, N >::data, and idx.

◆ wuppertalStep() [1/2]
| void quda::wuppertalStep | ( | ColorSpinorField & | out, |
| const ColorSpinorField & | in, | ||
| int | parity, | ||
| const GaugeField & | U, | ||
| double | A, | ||
| double | B | ||
| ) |
Apply a generic Wuppertal smearing step Computes out(x) = A*in(x) + B* (U_{-}(x)in(x+mu) + U^(x-mu)in(x-mu))
- Parameters
-
[out] out The out result field [in] in The in spinor field [in] U The gauge field [in] A The scaling factor for in(x) [in] B The scaling factor for (U_{-}(x)in(x+mu) + U^(x-mu)in(x-mu))
Definition at line 189 of file color_spinor_wuppertal.cu.
References quda::WuppertalSmearing< Float, Ns, Nc, Arg >::apply(), arg(), in, out, and parity.
Referenced by performWuppertalnStep(), and wuppertalStep().
◆ wuppertalStep() [2/2]
| void quda::wuppertalStep | ( | ColorSpinorField & | out, |
| const ColorSpinorField & | in, | ||
| int | parity, | ||
| const GaugeField & | U, | ||
| double | alpha | ||
| ) |
Apply a standard Wuppertal smearing step Computes out(x) = 1/(1+6*alpha)*(in(x) + alpha* (U_{-}(x)in(x+mu) + U^(x-mu)in(x-mu)))
- Parameters
-
[out] out The out result field [in] in The in spinor field [in] U The gauge field [in] alpha The smearing parameter
Definition at line 294 of file color_spinor_wuppertal.cu.
References in, out, parity, and wuppertalStep().
◆ wuppertalStepCPU()
| void quda::wuppertalStepCPU | ( | Arg | arg | ) |
Definition at line 119 of file color_spinor_wuppertal.cu.
References arg(), for(), and parity.

◆ wuppertalStepGPU()
| __global__ void quda::wuppertalStepGPU | ( | Arg | arg | ) |
Definition at line 135 of file color_spinor_wuppertal.cu.
References arg(), blockDim, and parity.

◆ zero() [1/10]
|
inline |
Definition at line 14 of file float_vector.h.
References a.
◆ zero() [2/10]
|
inline |
Definition at line 15 of file float_vector.h.
References a.
◆ zero() [3/10]
|
inline |
Definition at line 16 of file float_vector.h.
References a.
◆ zero() [4/10]
|
inline |
Definition at line 17 of file float_vector.h.
References a.
◆ zero() [5/10]
|
inline |
Definition at line 19 of file float_vector.h.
References a.
◆ zero() [6/10]
|
inline |
Definition at line 20 of file float_vector.h.
References a.
◆ zero() [7/10]
|
inline |
Definition at line 21 of file float_vector.h.
References a.
◆ zero() [8/10]
|
inline |
Definition at line 22 of file float_vector.h.
References a.
◆ zero() [9/10]
|
static |
Definition at line 52 of file inv_mpcg_quda.cpp.
References fused_exterior_ndeg_tm_dslash_cuda_gen::i.
◆ zero() [10/10]
|
inline |
Definition at line 82 of file cub_helper.cuh.
References quda::vector_type< scalar, n >::data, fused_exterior_ndeg_tm_dslash_cuda_gen::i, and n.
Referenced by quda::clover::Accessor< Float, nColor, nSpin, QUDA_PACKED_CLOVER_ORDER >::Accessor(), quda::ShiftUpdate::apply(), applyThirdTerm(), quda::GMResDR::FlexArnoldiProcedure(), quda::MG::generateNullVectors(), quda::HMatrix< T, N >::HMatrix(), quda::MG::loadVectors(), quda::Matrix< T, N >::Matrix(), quda::MG::MG(), quda::Lanczos::operator()(), quda::clover::Accessor< Float, nColor, nSpin, QUDA_PACKED_CLOVER_ORDER >::operator()(), quda::MPCG::operator()(), quda::PreconCG::operator()(), quda::MPBiCGstab::operator()(), quda::SD::operator()(), quda::GMResDR::operator()(), reduce2d(), quda::vector_type< scalar, n >::vector_type(), quda::Deflation::verify(), and quda::MG::verify().
Variable Documentation
◆ alloc
|
static |
Definition at line 51 of file malloc.cpp.
Referenced by assertAllMemFree(), device_free_(), quda::gauge::Accessor< Float, nColor, QUDA_FLOAT2_GAUGE_ORDER >::device_norm2(), device_pinned_free_(), host_free_(), quda::colorspinor::FieldOrderCB< Float, nSpin, nColor, nVec, order >::norm2(), print_alloc(), track_free(), and track_malloc().
◆ apiTimer
|
static |
Referenced by printAPIProfile().
◆ bidirectional_debug
|
static |
Definition at line 7 of file coarse_op.cuh.
Referenced by calculateY().
◆ complete_recv_back
|
static |
Definition at line 1150 of file cuda_color_spinor_field.cu.
Referenced by quda::cudaColorSpinorField::commsQuery().
◆ complete_recv_fwd
|
static |
Definition at line 1149 of file cuda_color_spinor_field.cu.
Referenced by quda::cudaColorSpinorField::commsQuery().
◆ complete_send_back
|
static |
Definition at line 1152 of file cuda_color_spinor_field.cu.
Referenced by quda::cudaColorSpinorField::commsQuery().
◆ complete_send_fwd
|
static |
Definition at line 1151 of file cuda_color_spinor_field.cu.
Referenced by quda::cudaColorSpinorField::commsQuery().
◆ config
|
static |
Definition at line 957 of file dslash_coarse.cu.
Referenced by quda::DslashCoarsePolicyTune::apply(), quda::DslashCoarsePolicyTune::defaultTuneParam(), quda::DslashCoarsePolicyTune::DslashCoarsePolicyTune(), and quda::DslashCoarsePolicyTune::initTuneParam().
◆ count
| __device__ unsigned int quda::count[QUDA_MAX_MULTI_REDUCE] = { } |
Definition at line 118 of file cub_helper.cuh.
Referenced by quda::ShiftUpdate::apply(), quda::BiCGstabLUpdate::apply(), quda::blas::caxpy_recurse(), quda::blas::caxpyz_recurse(), device_free_(), device_pinned_free_(), host_free_(), quda::blas::multiReduce_recurse(), quda::TimeProfile::Print(), quda::TimeProfile::PrintGlobal(), qudaMemcpy_(), qudaMemcpyAsync_(), reduce2d(), reduceRow(), and saveProfile().
◆ debug
|
static |
Definition at line 11 of file multigrid.cpp.
Referenced by quda::MG::operator()().
◆ dslash_init
|
static |
Definition at line 955 of file dslash_coarse.cu.
Referenced by quda::DslashCoarsePolicyTune::DslashCoarsePolicyTune().
◆ enable_trace
|
static |
Definition at line 73 of file tune.cpp.
Referenced by traceEnabled().
◆ gDigitsLut
|
static |
Definition at line 32 of file uint_to_char.h.
◆ initial_cache_size
|
static |
Definition at line 92 of file tune.cpp.
Referenced by loadTuneCache(), and saveTuneCache().
◆ isLastBlockDone
| __shared__ bool quda::isLastBlockDone |
Definition at line 119 of file cub_helper.cuh.
Referenced by reduce2d(), and reduceRow().
◆ isLastWarpDone
| __shared__ volatile bool quda::isLastWarpDone[16] |
Definition at line 166 of file cub_helper.cuh.
◆ it
|
static |
Definition at line 91 of file tune.cpp.
Referenced by quda::pool::device_malloc_(), quda::pool::flush_device(), quda::pool::flush_pinned(), quda::MPCG::operator()(), quda::MPBiCGstab::operator()(), quda::pool::pinned_malloc_(), serializeTrace(), and tuneLaunch().
◆ kernelPackT
|
static |
Definition at line 57 of file dslash_quda.cu.
Referenced by getKernelPackT(), and setKernelPackT().
◆ last_key
|
static |
Definition at line 24 of file tune.cpp.
Referenced by getLastTuneKey(), and tuneLaunch().
◆ launchTimer
|
static |
Referenced by printLaunchTimer(), and tuneLaunch().
◆ max_eigcg_cycles
|
static |
Definition at line 44 of file inv_eigcg_quda.cpp.
Referenced by quda::IncEigCG::operator()().
◆ max_total_bytes
|
static |
Definition at line 53 of file malloc.cpp.
Referenced by device_allocated_peak(), host_allocated_peak(), mapped_allocated_peak(), pinned_allocated_peak(), printPeakMemUsage(), and track_malloc().
◆ max_total_host_bytes
|
static |
Definition at line 54 of file malloc.cpp.
Referenced by printPeakMemUsage(), and track_malloc().
◆ max_total_pinned_bytes
|
static |
Definition at line 55 of file malloc.cpp.
Referenced by printPeakMemUsage(), and track_malloc().
◆ Nstream
| const int quda::Nstream = 9 |
Definition at line 330 of file quda_internal.h.
Referenced by ApplyClover(), ApplyGamma(), ApplyTwistClover(), ApplyTwistGamma(), anonymous_namespace{dslash_policy.cuh}::commsComplete(), anonymous_namespace{dslash_policy.cuh}::completeDslash(), contractCuda(), createDslashEvents(), destroyDslashEvents(), endQuda(), quda::blas::init(), initQudaMemory(), anonymous_namespace{dslash_policy.cuh}::DslashBasic::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashPthreads::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashFusedExterior::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashGDR::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashFusedGDR::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashGDRRecv::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashFusedGDRRecv::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashZeroCopyPack::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashFusedZeroCopyPack::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashZeroCopyPackGDRRecv::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashFusedZeroCopyPackGDRRecv::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashZeroCopy::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashFusedZeroCopy::operator()(), anonymous_namespace{dslash_policy.cuh}::DslashNC::operator()(), quda::cudaColorSpinorField::packExtended(), and quda::cudaColorSpinorField::zero().
◆ pinned_allocator
|
static |
Definition at line 24 of file deflation.cpp.
Referenced by quda::Deflation::reduce(), and quda::Deflation::verify().
◆ pinned_deleter
|
static |
Definition at line 25 of file deflation.cpp.
Referenced by quda::Deflation::reduce(), and quda::Deflation::verify().
◆ policy
|
static |
Definition at line 956 of file dslash_coarse.cu.
Referenced by quda::DslashCoarsePolicyTune::advanceAux(), quda::DslashCoarsePolicyTune::apply(), ApplyCoarse(), quda::DslashCoarsePolicyTune::DslashCoarsePolicyTune(), anonymous_namespace{dslash_policy.cuh}::DslashPolicyTune::DslashPolicyTune(), and quda::DslashCoarseLaunch::operator()().
◆ policy_tuning
|
static |
Definition at line 452 of file tune.cpp.
Referenced by policyTuning(), and setPolicyTuning().
◆ profile_count
|
static |
Definition at line 105 of file tune.cpp.
Referenced by disableProfileCount(), enableProfileCount(), and tuneLaunch().
◆ quda_hash
|
static |
Definition at line 88 of file tune.cpp.
Referenced by loadTuneCache(), saveProfile(), and saveTuneCache().
◆ quda_version
|
static |
Definition at line 96 of file tune.cpp.
Referenced by initQudaDevice(), loadTuneCache(), saveProfile(), and saveTuneCache().
◆ reorder_location_
|
static |
Definition at line 583 of file lattice_field.cpp.
Referenced by reorder_location(), and reorder_location_set().
◆ resource_path
|
static |
Definition at line 89 of file tune.cpp.
Referenced by loadTuneCache(), saveProfile(), and saveTuneCache().
◆ stream
| cudaStream_t* quda::stream |
Definition at line 898 of file cuda_color_spinor_field.cu.
Referenced by quda::CopySpinor< FloatOut, FloatIn, Ns, Nc, OutOrder, InOrder >::apply(), quda::blas::copy_ns::CopyCuda< FloatN, N, Output, Input >::apply(), quda::GaussSpinor< FloatIn, Ns, Nc, InOrder >::apply(), quda::CopyGaugeEx< FloatOut, FloatIn, length, OutOrder, InOrder >::apply(), quda::GenericPackGhostLauncher< Float, Ns, Ms, Nc, Mc, Arg >::apply(), quda::CopyColorSpinor< FloatOut, FloatIn, Ns, Nc, Arg >::apply(), quda::WuppertalSmearing< Float, Ns, Nc, Arg >::apply(), quda::Laplace< Float, nDim, nColor, Arg >::apply(), quda::ExtractGhost< Float, length, nDim, Order >::apply(), quda::ExtractGhostEx< Float, length, nDim, dim, Order >::apply(), quda::CopyGauge< FloatOut, FloatIn, length, OutOrder, InOrder, isGhost >::apply(), quda::CopyColorSpinor< FloatOut, FloatIn, 4, Nc, Arg >::apply(), quda::Gamma< ValueType, basis, dir >::apply(), quda::CopySpinorEx< FloatOut, FloatIn, Ns, Nc, OutOrder, InOrder, Basis, extend >::apply(), quda::TwistGamma< Float, nColor, Arg >::apply(), quda::Clover< Float, nSpin, nColor, Arg >::apply(), quda::ProjectSU3< Float, G >::apply(), quda::TwistClover< Float, nSpin, nColor, Arg >::apply(), quda::cudaColorSpinorField::gather(), quda::cudaColorSpinorField::pack(), quda::cudaColorSpinorField::packExtended(), quda::cudaColorSpinorField::packGhost(), quda::cudaColorSpinorField::packGhostExtended(), qudaEventRecord(), qudaLaunchKernel(), qudaMemcpy2DAsync_(), qudaMemcpyAsync_(), qudaStreamSynchronize(), qudaStreamWaitEvent(), quda::cudaColorSpinorField::scatter(), quda::cudaColorSpinorField::scatterExtended(), quda::cudaColorSpinorField::sendGhost(), quda::cudaColorSpinorField::sendStart(), quda::cudaColorSpinorField::streamInit(), quda::cudaColorSpinorField::unpackGhost(), and quda::cudaColorSpinorField::unpackGhostExtended().
◆ total_bytes
|
static |
Definition at line 52 of file malloc.cpp.
Referenced by track_free(), and track_malloc().
◆ total_host_bytes
|
static |
Definition at line 54 of file malloc.cpp.
Referenced by track_free(), and track_malloc().
◆ total_pinned_bytes
|
static |
Definition at line 55 of file malloc.cpp.
Referenced by track_free(), and track_malloc().
◆ trace_list
|
static |
Definition at line 72 of file tune.cpp.
Referenced by saveProfile(), serializeTrace(), and tuneLaunch().
◆ tunecache
|
static |
Definition at line 90 of file tune.cpp.
Referenced by deserializeTuneCache(), flushProfile(), getTuneCache(), loadTuneCache(), saveProfile(), saveTuneCache(), serializeProfile(), serializeTuneCache(), and tuneLaunch().
◆ tuning
|
static |
tuning in progress?
Definition at line 101 of file tune.cpp.
Referenced by activeTuning(), and tuneLaunch().
◆ unscaled_shifts
|
static |
Definition at line 1530 of file interface_quda.cpp.
Referenced by invertMultiShiftQuda(), and massRescale().
